
E aí, pessoal!
Nesse post eu trago para vocês uma solução simples, mas que eu gostei bastante, porque me ajudou a reduzir bastante o tempo de processamento de um pipeline do Azure Data Factory (ADF) ao alterar o Service Objective e redimensionar um Azure SQL Database utilizando comandos T-SQL antes do início do processamento, e voltando ao tier original ao final de todo o processamento.
Para alterar o tier do Azure SQL Database, você pode utilizar a interface do portal Azure, Powershell, Azure CLI, Azure DevOps e mais uma série de alternativas, além do nosso querido Transact-SQL (T-SQL), que, na minha visão, é a escolha mais fácil e prática de todas.
Vejam como é fácil:
ALTER DATABASE [dirceuresende]
MODIFY(SERVICE_OBJECTIVE = 'S3')
O problema de todas essas soluções, especialmente no cenário que eu estou falando, é que a alteração do Service Objetive, vulgo Service Tier, não é feita imediatamente, ou seja, você executa o comando e o Azure SQL irá efetivar a troca do tier no momento que o Azure achar melhor. Pode demorar 1 segundo, 10 segundos, 60 segundos, etc… E quando o tier do Azure SQL Database é alterado, as sessões são desconectadas.
No cenário que listei acima, onde altero o tier antes de iniciar o processamento dos dados, se eu simplesmente executar o comando T-SQL e continuar o processamento, no meio dele o Azure irá alterar o tier, a conexão irá cair por alguns segundos e o banco ficará indisponível por alguns segundos.
Você também pode utilizar o Retry em todos os componentes do seu pipeline e assim, evitar que isso seja um problema para você, pois quando a conexão cair, o retry será ativado e as operações serão feitas novamente, mas você teria que configurar o retry em todos os componentes ao invés de configurar apenas no componente do upsizing, pode ter sido cobrado por movimentação de dados e uso de recursos do próprio ADF durante esse tempo que processou à toa. Além disso, podem acontecer efeitos colaterais caso algum componente não esteja preparado para ser interrompido no meio da execução e executado novamente.
Outra possível solução é colocar um operador de Wait no Azure Data Factory e especificar um tempo qualquer que você ache ser suficiente para o Azure alterar o tier. Pelos meus testes, o tempo necessário para o Azure SQL Database efetivar a troca do tier costuma ser algo entre 50 e 90 segundos.
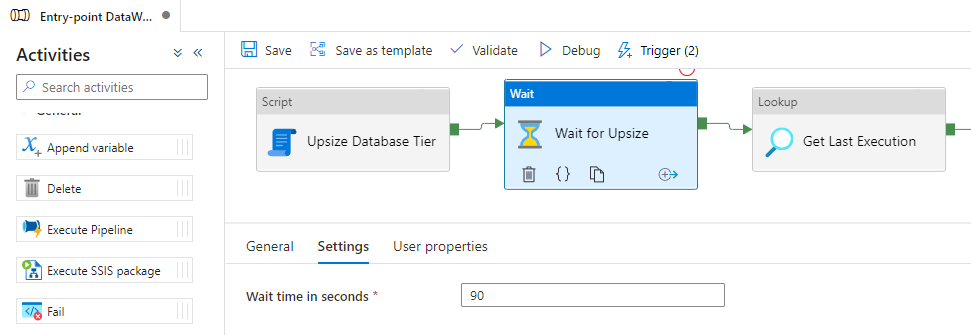
Embora isso possa funcionar em alguns casos (e em outros não), essa solução não me parece ser muito confiável. Se o tempo de alterar o tier ultrapassar o limite que eu defini, vou ter esperado um bom tempo e ainda vai falhar no meio do processamento. E se a alteração terminar antes, terei esperado um bom tempo sem necessidade.
Procurei algumas soluções para resolver esse meu problema e acabei caindo na ideia do MVP de Data Platform Greg Low nesse post aqui, mas optei por criar a minha procedure visando ter uma solução mais simples para tentar resolver esse problema.
Código-fonte da Stored Procedure
CREATE PROCEDURE dbo.stpAltera_Tier_DB (
@ServiceLevelObjective VARCHAR(50),
@TimeoutEmSegundos INT = 60
)
AS
BEGIN
SET NOCOUNT ON
DECLARE
@Query NVARCHAR(MAX),
@DataHoraLimite DATETIME2 = DATEADD(SECOND, @TimeoutEmSegundos, GETDATE()),
@ServiceLevelObjectiveAtual VARCHAR(20) = CONVERT(VARCHAR(100), DATABASEPROPERTYEX( DB_NAME(), 'ServiceObjective' ))
IF (@ServiceLevelObjectiveAtual <> @ServiceLevelObjective)
BEGIN
SET @Query = N'ALTER DATABASE [' + DB_NAME() + '] MODIFY (SERVICE_OBJECTIVE = ''' + @ServiceLevelObjective + ''');'
EXEC sp_executesql @Query;
WHILE ((DATABASEPROPERTYEX( DB_NAME(), 'ServiceObjective' ) <> @ServiceLevelObjective) AND GETDATE() <= @DataHoraLimite)
BEGIN
WAITFOR DELAY '00:00:00.500';
END
END
ENDO uso dessa procedure é bem simples:
EXEC dbo.stpAltera_Tier_DB
@ServiceLevelObjective = 'S3',
@TimeoutEmSegundos = 60
Após a execução do comando, a procedure vai ficar aguardando até que a alteração seja efetivada pelo Azure, reavaliando a cada 500 milissegundos se a alteração já foi realizada, respeitando o limite de tempo definido. Caso o limite seja atingido, a procedure irá terminar a execução mesmo que a alteração ainda não esteja efetivada. Caso a efetivação da alteração seja menor que o tempo limite, a procedure irá terminar a execução assim que o tier for alterado, evitando desperdício de tempo.
Para executar essa procedure pelo Azure Data Factory, vamos utilizar o “novo” componente de Script, disponibilizado em 6 de março de 2022:
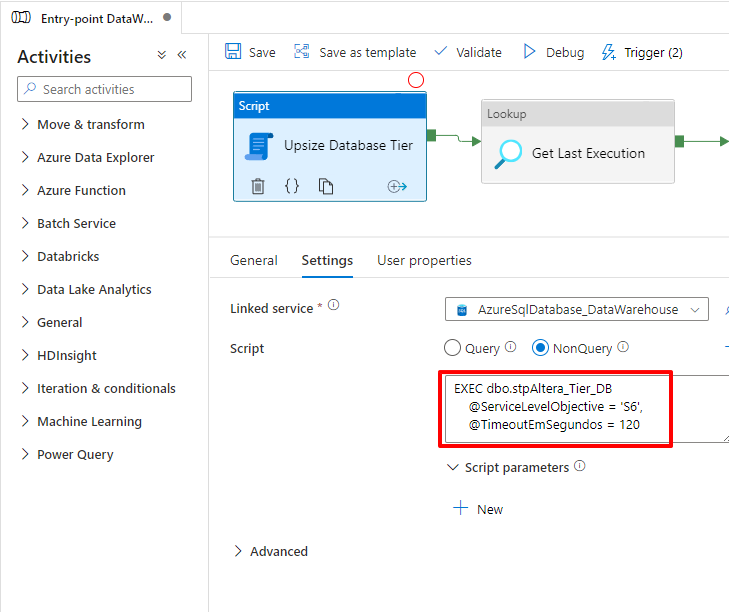
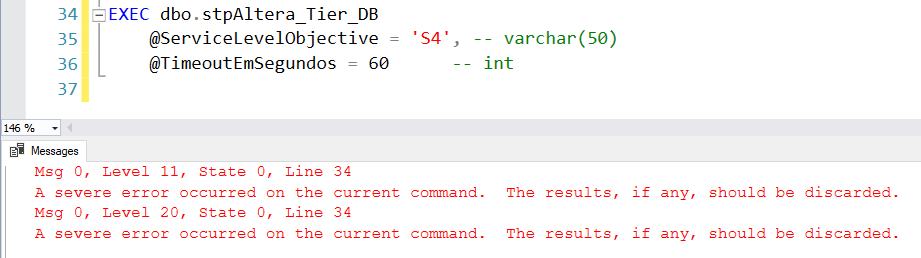
Como o Azure SQL Database elimina todas as conexões e o banco fica indisponível por uns segundos, mesmo com esse tratamento, a procedure irá retornar um erro por causa que a própria sessão dela foi eliminada:
No Azure Data Factory também vai dar erro ao executar essa procedure quando a troca for efetivada:
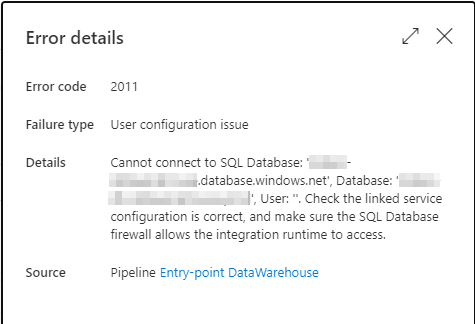
Para que essa solução dê certo, vamos definir um Retry para esse bloco de Script, de modo que quando ele falhar (e vai falhar), ele entre no Retry, espere mais 10 segundos e execute a Procedure de novo.
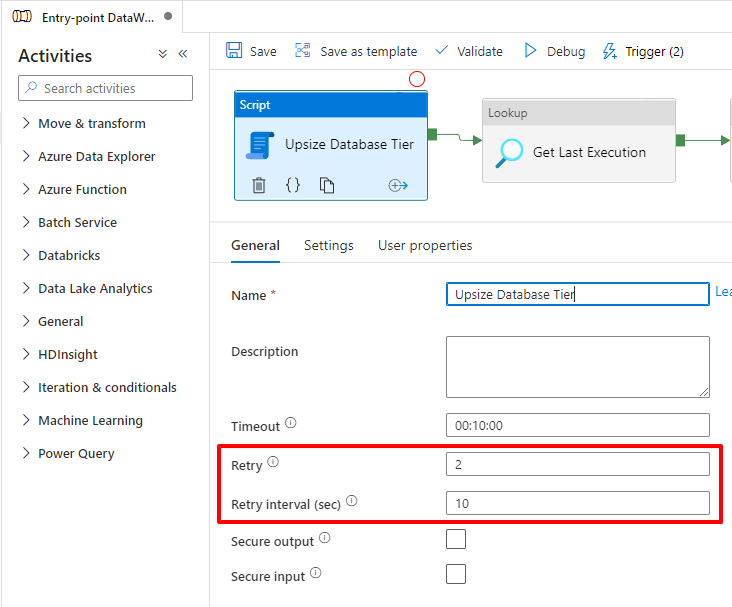
Na segunda execução da Stored Procedure, como a alteração será pelo mesmo tier da execução anterior, o comando será executado de forma instantânea e o Azure vai apenas ignorar o comando e retornar sucesso na execução, conforme demonstro abaixo:

E com isso, agora o seu banco já está com o novo tier e você pode iniciar o processamento dos dados. Ao final do processamento, eu faço o downscale para voltar o tier para o valor original, mas dessa vez, eu não preciso ficar esperando o término da alteração, pois não vou processar mais nada.
Sendo assim, eu posso usar a forma mais básica para voltar ao tier anterior:
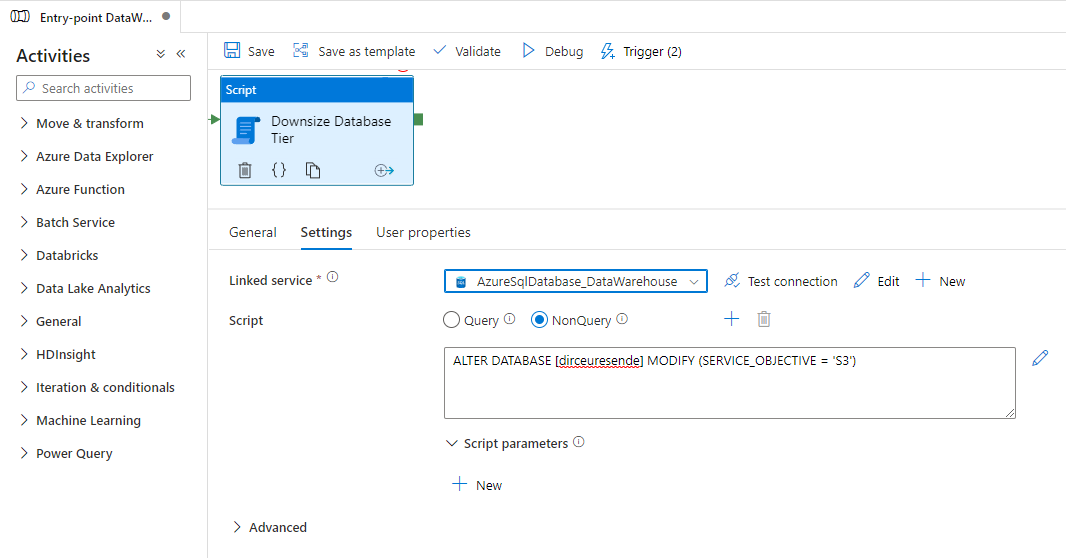
Para ser bem sincero com vocês, pensando na simplicidade em primeiro lugar, nem mesmo a Stored Procedure é necessária no final das contas. Como a conexão é sempre interrompida, posso apenas colocar um IF simples com um WAITFOR DELAY bem longo dentro do bloco do Script e ter o mesmo comportamento:
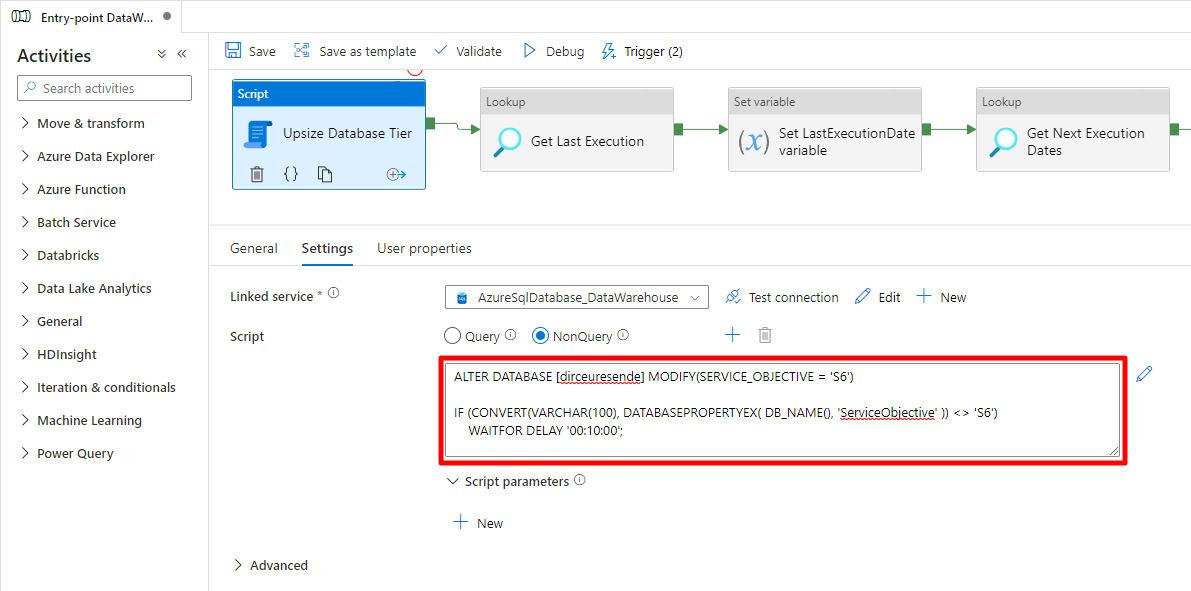
ALTER DATABASE [dirceuresende] MODIFY(SERVICE_OBJECTIVE = 'S6')
IF (CONVERT(VARCHAR(100), DATABASEPROPERTYEX( DB_NAME(), 'ServiceObjective' )) <> 'S6')
WAITFOR DELAY '00:10:00';
Bloco do script:
Resultado da execução:
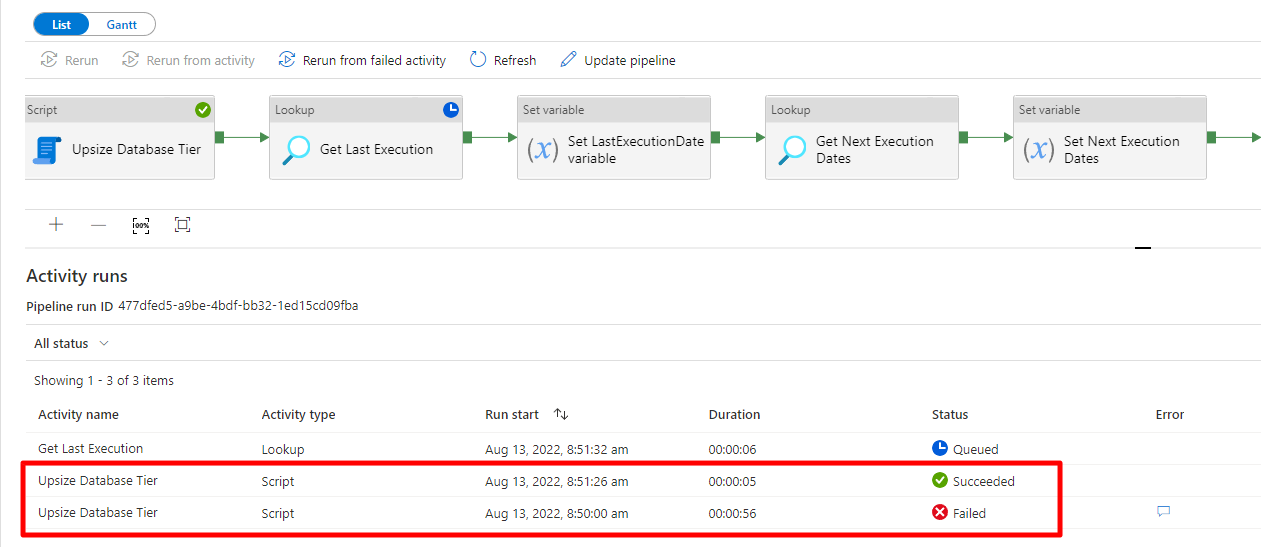
E assim como utilizando a Stored Procedure, a rotina deu erro na primeira execução, aguardando até que a alteração do tier seja efetivada no banco. Quando isso ocorre, a conexão é interrompida e a execução retorna falha.
O Azure Data Factory aguarda 10 segundos (tempo que eu defini) após a falha e tenta novamente. Desta vez, a execução é bem rápida, uma vez que o tier já foi alterado para o tier escolhido. Essa segunda execução retorna sucesso e o ciclo do pipeline segue normalmente.
O comportamento acabou sendo igual ao da Procedure, mas muito mais simples. Coloquei um wait bem longo (10 minutos), que vai acabar sendo o limite de tempo que o Azure terá para efetuar a mudança, o que é bem mais que o suficiente. Acabando a alteração antes, o ciclo já continua sem precisar esperar esses 10 minutos.
Acabou que a solução ficou ainda mais simples do que eu pensava. Agora vocês podem aumentar o tier do seu Azure SQL Database antes de iniciar o processamento do ETL usando o Azure Data Factory, para que o processamento seja mais rápido, e ao final do processamento, você volta ao tier original, pagando a mais somente durante o tempo em que ficou processando dados. Uma forma inteligente de ter uma performance bem superior pagando muito menos 🙂
Espero que vocês tenham gostado dessa dica e até a próxima.

Comentários (0)
Carregando comentários...