Olá pessoal!
Nesse post, eu gostaria de demonstrar algumas formas de identificar consultas lentas ou pesadas, que acabam consumindo muito recurso da máquina e acabam demorando muito para retornar os resultados, seja por excesso de uso de CPU, memória ou disco.
O objetivo desse artigo é te auxiliar na identificação das consultas que estão com possíveis problemas de performance. Uma vez identificadas quais são essas consultas, aí você deve avaliar se é necessário adicionar mais hardware na máquina ou iniciar atividades de performance e query tuning (que não é o foco desse post).
Análise de eventos de wait
Visualizar conteúdoUm bom ponto de início para a nossa análise, é consultando a DMV sys.dm_os_wait_stats, com a query abaixo:
SELECT *
FROM sys.dm_os_wait_stats
ORDER BY wait_time_ms DESC
Resultado:
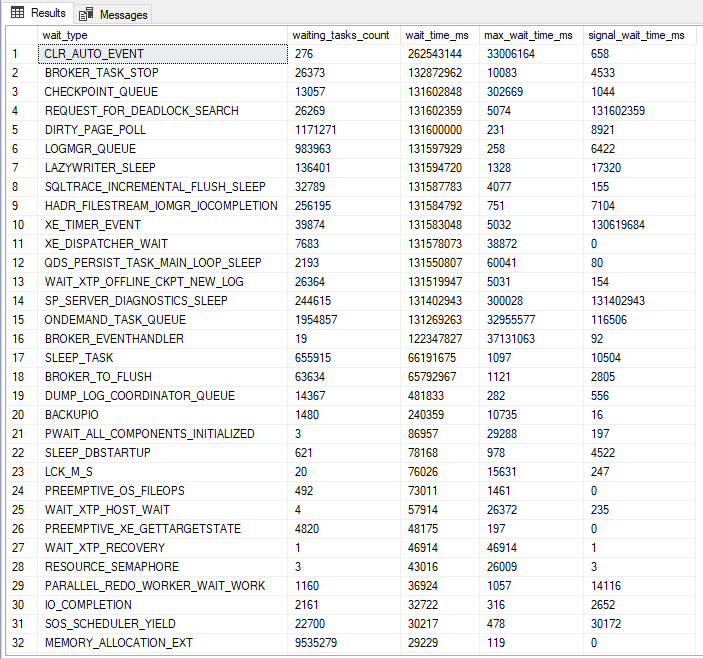
Essa consulta vai apresentar quais os eventos de waiting que mais demandaram tempo, ou seja, vai avaliar entre tudo o que foi executado na instância, o que mais fez essas consultas aguardarem recursos, seja disco, CPU, memória, rede, etc. Isso é muito útil para identificar onde está o nosso maior gargalo de processamento.
O grande Paul Randal disponibilizou uma versão dessa query, que traz algumas estatísticas sobre esses eventos de wait, como % de tempo de wait e um link para a explicação do que é esse evento de wait, e também filtra eventos que geralmente só apenas avisos e não problemas, facilitando a identificação do que realmente está atrapalhando a nossa instância.
Segue script:
;WITH [Waits]
AS ( SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
( [wait_time_ms] - [signal_wait_time_ms] ) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM([wait_time_ms]) OVER () AS [Percentage],
ROW_NUMBER() OVER ( ORDER BY
[wait_time_ms] DESC
) AS [RowNum]
FROM
sys.dm_os_wait_stats
WHERE
[wait_type] NOT IN (
-- These wait types are almost 100% never a problem and so they are
-- filtered out to avoid them skewing the results. Click on the URL
-- for more information.
N'BROKER_EVENTHANDLER', -- https://www.sqlskills.com/help/waits/BROKER_EVENTHANDLER
N'BROKER_RECEIVE_WAITFOR', -- https://www.sqlskills.com/help/waits/BROKER_RECEIVE_WAITFOR
N'BROKER_TASK_STOP', -- https://www.sqlskills.com/help/waits/BROKER_TASK_STOP
N'BROKER_TO_FLUSH', -- https://www.sqlskills.com/help/waits/BROKER_TO_FLUSH
N'BROKER_TRANSMITTER', -- https://www.sqlskills.com/help/waits/BROKER_TRANSMITTER
N'CHECKPOINT_QUEUE', -- https://www.sqlskills.com/help/waits/CHECKPOINT_QUEUE
N'CHKPT', -- https://www.sqlskills.com/help/waits/CHKPT
N'CLR_AUTO_EVENT', -- https://www.sqlskills.com/help/waits/CLR_AUTO_EVENT
N'CLR_MANUAL_EVENT', -- https://www.sqlskills.com/help/waits/CLR_MANUAL_EVENT
N'CLR_SEMAPHORE', -- https://www.sqlskills.com/help/waits/CLR_SEMAPHORE
N'CXCONSUMER', -- https://www.sqlskills.com/help/waits/CXCONSUMER
-- Maybe comment these four out if you have mirroring issues
N'DBMIRROR_DBM_EVENT', -- https://www.sqlskills.com/help/waits/DBMIRROR_DBM_EVENT
N'DBMIRROR_EVENTS_QUEUE', -- https://www.sqlskills.com/help/waits/DBMIRROR_EVENTS_QUEUE
N'DBMIRROR_WORKER_QUEUE', -- https://www.sqlskills.com/help/waits/DBMIRROR_WORKER_QUEUE
N'DBMIRRORING_CMD', -- https://www.sqlskills.com/help/waits/DBMIRRORING_CMD
N'DIRTY_PAGE_POLL', -- https://www.sqlskills.com/help/waits/DIRTY_PAGE_POLL
N'DISPATCHER_QUEUE_SEMAPHORE', -- https://www.sqlskills.com/help/waits/DISPATCHER_QUEUE_SEMAPHORE
N'EXECSYNC', -- https://www.sqlskills.com/help/waits/EXECSYNC
N'FSAGENT', -- https://www.sqlskills.com/help/waits/FSAGENT
N'FT_IFTS_SCHEDULER_IDLE_WAIT', -- https://www.sqlskills.com/help/waits/FT_IFTS_SCHEDULER_IDLE_WAIT
N'FT_IFTSHC_MUTEX', -- https://www.sqlskills.com/help/waits/FT_IFTSHC_MUTEX
-- Maybe comment these six out if you have AG issues
N'HADR_CLUSAPI_CALL', -- https://www.sqlskills.com/help/waits/HADR_CLUSAPI_CALL
N'HADR_FILESTREAM_IOMGR_IOCOMPLETION', -- https://www.sqlskills.com/help/waits/HADR_FILESTREAM_IOMGR_IOCOMPLETION
N'HADR_LOGCAPTURE_WAIT', -- https://www.sqlskills.com/help/waits/HADR_LOGCAPTURE_WAIT
N'HADR_NOTIFICATION_DEQUEUE', -- https://www.sqlskills.com/help/waits/HADR_NOTIFICATION_DEQUEUE
N'HADR_TIMER_TASK', -- https://www.sqlskills.com/help/waits/HADR_TIMER_TASK
N'HADR_WORK_QUEUE', -- https://www.sqlskills.com/help/waits/HADR_WORK_QUEUE
N'KSOURCE_WAKEUP', -- https://www.sqlskills.com/help/waits/KSOURCE_WAKEUP
N'LAZYWRITER_SLEEP', -- https://www.sqlskills.com/help/waits/LAZYWRITER_SLEEP
N'LOGMGR_QUEUE', -- https://www.sqlskills.com/help/waits/LOGMGR_QUEUE
N'MEMORY_ALLOCATION_EXT', -- https://www.sqlskills.com/help/waits/MEMORY_ALLOCATION_EXT
N'ONDEMAND_TASK_QUEUE', -- https://www.sqlskills.com/help/waits/ONDEMAND_TASK_QUEUE
N'PARALLEL_REDO_DRAIN_WORKER', -- https://www.sqlskills.com/help/waits/PARALLEL_REDO_DRAIN_WORKER
N'PARALLEL_REDO_LOG_CACHE', -- https://www.sqlskills.com/help/waits/PARALLEL_REDO_LOG_CACHE
N'PARALLEL_REDO_TRAN_LIST', -- https://www.sqlskills.com/help/waits/PARALLEL_REDO_TRAN_LIST
N'PARALLEL_REDO_WORKER_SYNC', -- https://www.sqlskills.com/help/waits/PARALLEL_REDO_WORKER_SYNC
N'PARALLEL_REDO_WORKER_WAIT_WORK', -- https://www.sqlskills.com/help/waits/PARALLEL_REDO_WORKER_WAIT_WORK
N'PREEMPTIVE_XE_GETTARGETSTATE', -- https://www.sqlskills.com/help/waits/PREEMPTIVE_XE_GETTARGETSTATE
N'PWAIT_ALL_COMPONENTS_INITIALIZED', -- https://www.sqlskills.com/help/waits/PWAIT_ALL_COMPONENTS_INITIALIZED
N'PWAIT_DIRECTLOGCONSUMER_GETNEXT', -- https://www.sqlskills.com/help/waits/PWAIT_DIRECTLOGCONSUMER_GETNEXT
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP', -- https://www.sqlskills.com/help/waits/QDS_PERSIST_TASK_MAIN_LOOP_SLEEP
N'QDS_ASYNC_QUEUE', -- https://www.sqlskills.com/help/waits/QDS_ASYNC_QUEUE
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP', -- https://www.sqlskills.com/help/waits/QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP
N'QDS_SHUTDOWN_QUEUE', -- https://www.sqlskills.com/help/waits/QDS_SHUTDOWN_QUEUE
N'REDO_THREAD_PENDING_WORK', -- https://www.sqlskills.com/help/waits/REDO_THREAD_PENDING_WORK
N'REQUEST_FOR_DEADLOCK_SEARCH', -- https://www.sqlskills.com/help/waits/REQUEST_FOR_DEADLOCK_SEARCH
N'RESOURCE_QUEUE', -- https://www.sqlskills.com/help/waits/RESOURCE_QUEUE
N'SERVER_IDLE_CHECK', -- https://www.sqlskills.com/help/waits/SERVER_IDLE_CHECK
N'SLEEP_BPOOL_FLUSH', -- https://www.sqlskills.com/help/waits/SLEEP_BPOOL_FLUSH
N'SLEEP_DBSTARTUP', -- https://www.sqlskills.com/help/waits/SLEEP_DBSTARTUP
N'SLEEP_DCOMSTARTUP', -- https://www.sqlskills.com/help/waits/SLEEP_DCOMSTARTUP
N'SLEEP_MASTERDBREADY', -- https://www.sqlskills.com/help/waits/SLEEP_MASTERDBREADY
N'SLEEP_MASTERMDREADY', -- https://www.sqlskills.com/help/waits/SLEEP_MASTERMDREADY
N'SLEEP_MASTERUPGRADED', -- https://www.sqlskills.com/help/waits/SLEEP_MASTERUPGRADED
N'SLEEP_MSDBSTARTUP', -- https://www.sqlskills.com/help/waits/SLEEP_MSDBSTARTUP
N'SLEEP_SYSTEMTASK', -- https://www.sqlskills.com/help/waits/SLEEP_SYSTEMTASK
N'SLEEP_TASK', -- https://www.sqlskills.com/help/waits/SLEEP_TASK
N'SLEEP_TEMPDBSTARTUP', -- https://www.sqlskills.com/help/waits/SLEEP_TEMPDBSTARTUP
N'SNI_HTTP_ACCEPT', -- https://www.sqlskills.com/help/waits/SNI_HTTP_ACCEPT
N'SP_SERVER_DIAGNOSTICS_SLEEP', -- https://www.sqlskills.com/help/waits/SP_SERVER_DIAGNOSTICS_SLEEP
N'SQLTRACE_BUFFER_FLUSH', -- https://www.sqlskills.com/help/waits/SQLTRACE_BUFFER_FLUSH
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP', -- https://www.sqlskills.com/help/waits/SQLTRACE_INCREMENTAL_FLUSH_SLEEP
N'SQLTRACE_WAIT_ENTRIES', -- https://www.sqlskills.com/help/waits/SQLTRACE_WAIT_ENTRIES
N'WAIT_FOR_RESULTS', -- https://www.sqlskills.com/help/waits/WAIT_FOR_RESULTS
N'WAITFOR', -- https://www.sqlskills.com/help/waits/WAITFOR
N'WAITFOR_TASKSHUTDOWN', -- https://www.sqlskills.com/help/waits/WAITFOR_TASKSHUTDOWN
N'WAIT_XTP_RECOVERY', -- https://www.sqlskills.com/help/waits/WAIT_XTP_RECOVERY
N'WAIT_XTP_HOST_WAIT', -- https://www.sqlskills.com/help/waits/WAIT_XTP_HOST_WAIT
N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG', -- https://www.sqlskills.com/help/waits/WAIT_XTP_OFFLINE_CKPT_NEW_LOG
N'WAIT_XTP_CKPT_CLOSE', -- https://www.sqlskills.com/help/waits/WAIT_XTP_CKPT_CLOSE
N'XE_DISPATCHER_JOIN', -- https://www.sqlskills.com/help/waits/XE_DISPATCHER_JOIN
N'XE_DISPATCHER_WAIT', -- https://www.sqlskills.com/help/waits/XE_DISPATCHER_WAIT
N'XE_TIMER_EVENT' -- https://www.sqlskills.com/help/waits/XE_TIMER_EVENT
)
AND [waiting_tasks_count] > 0 )
SELECT
MAX([W1].[wait_type]) AS [WaitType],
CAST(MAX([W1].[WaitS]) AS DECIMAL(16, 2)) AS [Wait_S],
CAST(MAX([W1].[ResourceS]) AS DECIMAL(16, 2)) AS [Resource_S],
CAST(MAX([W1].[SignalS]) AS DECIMAL(16, 2)) AS [Signal_S],
MAX([W1].[WaitCount]) AS [WaitCount],
CAST(MAX([W1].[Percentage]) AS DECIMAL(5, 2)) AS [Percentage],
CAST(( MAX([W1].[WaitS]) / MAX([W1].[WaitCount])) AS DECIMAL(16, 4)) AS [AvgWait_S],
CAST(( MAX([W1].[ResourceS]) / MAX([W1].[WaitCount])) AS DECIMAL(16, 4)) AS [AvgRes_S],
CAST(( MAX([W1].[SignalS]) / MAX([W1].[WaitCount])) AS DECIMAL(16, 4)) AS [AvgSig_S],
CAST('https://www.sqlskills.com/help/waits/' + MAX([W1].[wait_type]) AS XML) AS [Help/Info URL]
FROM
[Waits] AS [W1]
INNER JOIN [Waits] AS [W2] ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY
[W1].[RowNum]
HAVING
SUM([W2].[Percentage]) - MAX([W1].[Percentage]) < 95; -- percentage threshold
GO
Resultado: (bem mais “clean” né?”
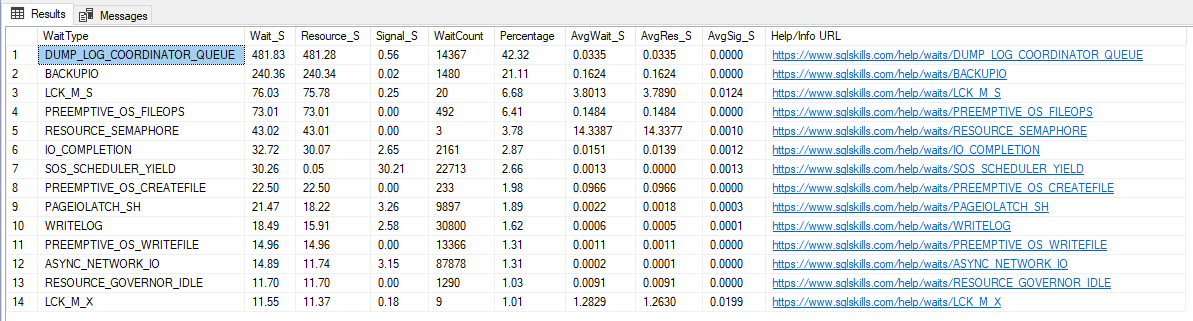
Para facilitar a sua vida, vou listar abaixo alguns eventos comuns e sua possível causa:
- ASYNC_NETWORK_IO / NETWORKIO: Os eventos de wait networkio (SQL 2000) e async_network_io (SQL 2005+) podem apontar para problemas relacionados à rede (raramente), mas geralmente podem indicar que uma aplicação cliente não está processando os resultados do SQL Server rápido o bastante. Esse evento costuma aparecer em casos de RBAR (Row-By-Agonizing-Row)
- CXPACKET: Evento geralmente ligado à execução de consultas utilizando processamento paralelo, ele pode indicar que uma thread já concluiu o seu processamento e está aguardando a execução das outras threads do processo para concluir a execução. Caso esse evento esteja com wait_time muito alto, talvez seja interessante revisar as configurações de MAXDOP, avaliar se o hint OPTION(MAXDOP x) pode ser útil em algumas consultas, reavaliar os índices utilizados pelas consultas que mais consomem disco (provavelmente, essas que estão utilizando paralelismo) e tentar garantir que argumentos sargable estão sendo utilizados.
- DTC: Esse evento de wait não é local. Quando se utiliza o Microsoft Distributed Transaction Coordinator (MS-DTC), uma transação é aberta em vários sistemas ao mesmo tempo e a transação só é concluída quando ela é executada em todos esses sistemas.
- OLEDB: Esse evento de wait indica que o processo fez uma chamada para um provedor OLEDB e está aguardando que essa chamada processo no servidor de destino e retorne os dados. Esse evento é gerado também quando executamos comandos em outras instâncias utilizando Linked Servers (chamadas remotas), comandos BULK INSERT e consultas FULLTEXT-SEARCH. Não há nada o que se fazer na instância local, mas em casos de chamadas remotas a outras instâncias, você pode analisar a instância de destino e tentar identificar o motivo da demora no processamento e retorno dos dados.
- PAGEIOLATCH_*: Esse evento ocorre quando o SQL Server está aguardando para ler dados no disco/storage de páginas que não estão em memória, gerando contenção de disco. Para diminuir esse evento de I/O, você pode tentar aumentar a velocidade do disco (para reduzir esse tempo), adicionar mais memória (para alocar mais páginas) ou tentar identificar e tunar essas consultas que estão gerando esse evento de I/O.
Uma causa muito comum que gera esse evento, é a falta de índices ótimos para essa determinada consulta, o que pode ser resolvido criando novos índices com a ajuda das DMV’s de Missing Index para evitar operações de Scan (Dê uma lida no post Entendendo o funcionamento dos índices no SQL Server para entender melhor sobre isso).
- PAGELATCH_*: As causas mais comuns para esse evento são contenção na tempdb em instâncias com muita sobrecarga. O wait PAGELATCH_UP geralmente ocorre quando múltiplas threads estão tentando acessar o mesmo bitmap, enquanto o evento PAGELATCH_EX ocorre quando threads estão tentando inserir dados na mesma página do disco, e o evento PAGELATCH_SH indica que alguma thread está tentando ler dados de uma página que está sendo modificada
- IO_COMPLETION: Esse evento de wait ocorre quando o SQL Server está aguardando operações de I/O para concluir o processamento, as quais não são leituras de índices os de dados no disco, e sim, leituras de alocações de bitmaps do disco (GAM, SGAM, PFS), transaction log, escritas de sort buffers no disco, leitura de cabeçalhos de VLF’s da transaction log, leitura/escrita de merge join/eager spools no disco, etc.
Esse evento é normal acontecer, pois ele costuma aparece logo antes de se iniciar alguma operação que requisite I/O, mas pode ser um problema se o tempo de wait está muito alto e a sua lista de maiores waits inclui ASYNC_IO_COMPLETION, LOGMGR, WRITELOG ou PAGEIOLATCH_*.
Quando existe um problema de I/O na instância, o log do SQL Server costuma apresentar mensagens de “I/O requests are taking longer than X seconds to complete”, o que pode acontecer se houver realmente uma lentidão nos discos ou estiverem processando operações que consomem muito I/O, como BACKUP, ALTER/CREATE DATABASE e eventos de AutoGrowth.
Para investir esse problema, procure por consultas que esteja com tempos de leitura/escrita de disco muito altas, incluindo os contadores Disk avg. read time, Disk avg. write time, Avg. disk queue length, Buffer cache hit ratio, Buffer free pages, Buffer page life expectancy e Machine: memory used
- SOS_SCHEDULER_YIELD: Esse evento ocorre quando o SqlOS (SOS) está aguardando mais recursos de CPU para terminar o processamento, o que pode indicar que o servidor está com sobrecarga de CPU e não está conseguindo processar todas as tarefas que são requisitadas. Entretanto, nem sempre isso indica que é um problema geral da instância, pois pode indicar que uma query em específico que está precisando de mais CPU.
Se a sua query possui alguns inibidores de paralelismo (Ex: HINT MAXDOP(1), funções UDF seriais, consultas a tabelas de sistemas, etc), ela pode fazer com que o processamento seja feito utilizando apenas 1 CPU Core, fazendo com que o evento SOS_SCHEDULER_YIELD possa ser gerado, mesmo que o servidor tenha vários cores disponíveis para processamento e com baixa utilização de CPU na instância.
Para tentar identificar isso, tente localizar as consultas que estão mais consumindo CPU e/ou que o tempo de CPU seja menor que o tempo de execução (quando ocorre paralelismo, às vezes a consulta consome 10s de CPU e executa em 2s, o que significa que ela foi paralelizada em vários núcleos da CPU)
- WRITELOG: Quando uma transação está aguardando pelo evento WRITELOG, isso quer dizer que ela está aguardando que o SQL Server capture os dados do log cache e os grave em disco (na transaction log). Como essa operação envolve escrita em disco, que é uma operação geralmente muito mais lenta que um acesso à memória ou processamento na CPU, esse tipo de evento pode ser bem comum em instâncias que não tenham um disco muito rápido. Se você encontra muito esse evento, uma alternativa para reduzir esse wait é utilizar o recurso Delayed Durability, disponível a partir do SQL Server 2014
- LCK*: Evento muito comum e que não está diretamente relacionado à performance, esse evento ocorre quando uma transação está alterando um objeto e ela coloca um lock nesse objeto, para impedir que nenhuma outra transação possar modificar ou acessar os dados enquanto ela está processando. Com isso, caso outra transação tente acessar esse objeto, ela terá que ficar aguardando a remoção desse lock para continuar o processamento, gerando justamente esse evento de wait. Isso é muito confundido com problema de performance, porque a consulta vai realmente demorar o tempo que for necessário até que o lock seja liberado e ela possar processar seus dados, fazendo com o que o usuário tenha uma sensação de lentidão no ambiente, ainda mais se for uma consulta muito utilizada no sistema. Nesse caso, é cabível uma análise da sessão que está gerando o lock para avaliar porquê ela está demorando tanto para processar e liberar o objeto.
Para se aprofundar na análise de eventos de wait, recomendo a leitura dos posts abaixo:
– https://www.sqlskills.com/help/sql-server-performance-tuning-using-wait-statistics/
– https://www.sqlskills.com/blogs/erin/the-accidental-dba-day-25-of-30-wait-statistics-analysis/
– Wait statistics, or please tell me where it hurts
– List of common wait types
– Using Wait Stats to Find Why SQL Server is Slow
– What is the most worrying wait type?
Como identificar consultas demoradas utilizando Extended Event (XE)
Visualizar conteúdo
Desta forma, em conjunto com a análise de eventos de wait, podemos iniciar o trabalho de identificar possíveis agressores ao consumo de CPU, Disco ou tempo de execução.
Como identificar consultas demoradas utilizando Trace
Visualizar conteúdo
Desta forma, em conjunto com a análise de eventos de wait, podemos iniciar o trabalho de identificar possíveis agressores ao consumo de CPU, Disco ou tempo de execução.
Como identificar consultas ad-hoc “pesadas” com DMV’s
Visualizar conteúdoUtilizando as estatísticas do banco e a DMV sys.dm_exec_query_stats, podemos consultar as queries que foram executadas na instância e aplicar os filtros e ordenação de tempo de execução, disco e CPU, permitindo inclusive, identificar a quantidade de vezes que essa consulta foi executada, tempo médio de execução e tempo da última execução, além de informar a query completa (text) que está sendo executada e também o trecho específico desse objeto/query (TSQL) dessas estatísticas coletadas e também o plano de execução dessa query.
Query utilizadada (Ordenando por tempo de execução):
SELECT TOP 100
DB_NAME(C.[dbid]) as [database],
B.[text],
(SELECT CAST(SUBSTRING(B.[text], (A.statement_start_offset/2)+1,
(((CASE A.statement_end_offset
WHEN -1 THEN DATALENGTH(B.[text])
ELSE A.statement_end_offset
END) - A.statement_start_offset)/2) + 1) AS NVARCHAR(MAX)) FOR XML PATH(''), TYPE) AS [TSQL],
C.query_plan,
A.last_execution_time,
A.execution_count,
A.total_elapsed_time / 1000 AS total_elapsed_time_ms,
A.last_elapsed_time / 1000 AS last_elapsed_time_ms,
A.min_elapsed_time / 1000 AS min_elapsed_time_ms,
A.max_elapsed_time / 1000 AS max_elapsed_time_ms,
((A.total_elapsed_time / A.execution_count) / 1000) AS avg_elapsed_time_ms,
A.total_worker_time / 1000 AS total_worker_time_ms,
A.last_worker_time / 1000 AS last_worker_time_ms,
A.min_worker_time / 1000 AS min_worker_time_ms,
A.max_worker_time / 1000 AS max_worker_time_ms,
((A.total_worker_time / A.execution_count) / 1000) AS avg_worker_time_ms,
A.total_physical_reads,
A.last_physical_reads,
A.min_physical_reads,
A.max_physical_reads,
A.total_logical_reads,
A.last_logical_reads,
A.min_logical_reads,
A.max_logical_reads,
A.total_logical_writes,
A.last_logical_writes,
A.min_logical_writes,
A.max_logical_writes
FROM
sys.dm_exec_query_stats A
CROSS APPLY sys.dm_exec_sql_text(A.[sql_handle]) B
OUTER APPLY sys.dm_exec_query_plan (A.plan_handle) AS C
ORDER BY
A.total_elapsed_time DESC
Resultado:
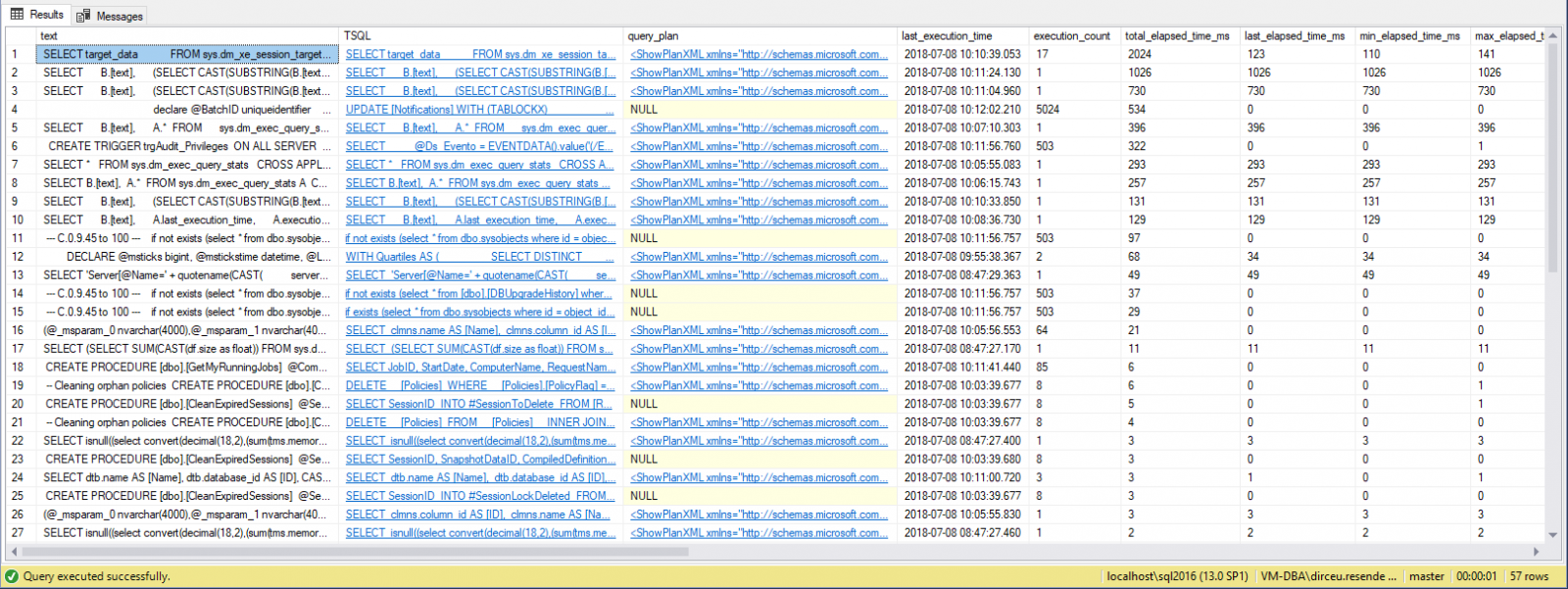
Como vocês puderam observar, no exemplo acima eu filtrei os dados para me retornar as consultas que demora mais tempo para executar, mas você pode ordenar pela coluna que desejar, conseguindo refinar bem a sua consulta de acordo com seu ambiente e necessidade, junto à análise dos eventos de wait.
Vale lembrar que, como estamos consultando dados de estatísticas do banco, caso o serviço seja reiniciado, esses dados são perdidos. Por este motivo, sugiro criar uma rotina que colete esses dados de tempos em tempos e armazene em uma tabela física, para quando isso acontecer, você possa continuar sua análise de onde parou e não precise esperar por horas ou dias para ter dados para continuar analisando.
Stored Procedure para armazenar as consultas Ad-hoc de todos os databases:
USE [dirceuresende]
GO
CREATE PROCEDURE [dbo].[stpCarga_Historico_Execucao_Consultas]
AS BEGIN
IF (OBJECT_ID('dirceuresende.dbo.Historico_Execucao_Consultas') IS NULL)
BEGIN
-- DROP TABLE dirceuresende.dbo.Historico_Execucao_Consultas
CREATE TABLE dirceuresende.dbo.Historico_Execucao_Consultas
(
Id_Coleta BIGINT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED,
Dt_Coleta datetime NOT NULL,
[database] sys.sysname NOT NULL,
[text] NVARCHAR(MAX) NULL,
[TSQL] XML NULL,
[query_plan] XML NULL,
last_execution_time datetime NULL,
execution_count bigint NOT NULL,
total_elapsed_time_ms bigint NULL,
last_elapsed_time_ms bigint NULL,
min_elapsed_time_ms bigint NULL,
max_elapsed_time_ms bigint NULL,
avg_elapsed_time_ms bigint NULL,
total_worker_time_ms bigint NULL,
last_worker_time_ms bigint NULL,
min_worker_time_ms bigint NULL,
max_worker_time_ms bigint NULL,
avg_worker_time_ms bigint NULL,
total_physical_reads bigint NOT NULL,
last_physical_reads bigint NOT NULL,
min_physical_reads bigint NOT NULL,
max_physical_reads bigint NOT NULL,
total_logical_reads bigint NOT NULL,
last_logical_reads bigint NOT NULL,
min_logical_reads bigint NOT NULL,
max_logical_reads bigint NOT NULL,
total_logical_writes bigint NOT NULL,
last_logical_writes bigint NOT NULL,
min_logical_writes bigint NOT NULL,
max_logical_writes bigint NOT NULL
) WITH(DATA_COMPRESSION=PAGE)
CREATE INDEX SK01_Historico_Execucao_Consultas ON dirceuresende.dbo.Historico_Execucao_Consultas(Dt_Coleta, [database])
END
DECLARE
@Dt_Referencia DATETIME = GETDATE(),
@Query VARCHAR(MAX)
SET @Query = '
IF (''?'' NOT IN (''master'', ''model'', ''msdb'', ''tempdb''))
BEGIN
INSERT INTO dirceuresende.dbo.Historico_Execucao_Consultas
SELECT
''' + CONVERT(VARCHAR(19), @Dt_Referencia, 120) + ''' AS Dt_Coleta,
''?'' AS [database],
B.[text],
(SELECT CAST(SUBSTRING(B.[text], (A.statement_start_offset/2)+1, (((CASE A.statement_end_offset WHEN -1 THEN DATALENGTH(B.[text]) ELSE A.statement_end_offset END) - A.statement_start_offset)/2) + 1) AS NVARCHAR(MAX)) FOR XML PATH(''''),TYPE) AS [TSQL],
C.query_plan,
A.last_execution_time,
A.execution_count,
A.total_elapsed_time / 1000 AS total_elapsed_time_ms,
A.last_elapsed_time / 1000 AS last_elapsed_time_ms,
A.min_elapsed_time / 1000 AS min_elapsed_time_ms,
A.max_elapsed_time / 1000 AS max_elapsed_time_ms,
((A.total_elapsed_time / A.execution_count) / 1000) AS avg_elapsed_time_ms,
A.total_worker_time / 1000 AS total_worker_time_ms,
A.last_worker_time / 1000 AS last_worker_time_ms,
A.min_worker_time / 1000 AS min_worker_time_ms,
A.max_worker_time / 1000 AS max_worker_time_ms,
((A.total_worker_time / A.execution_count) / 1000) AS avg_worker_time_ms,
A.total_physical_reads,
A.last_physical_reads,
A.min_physical_reads,
A.max_physical_reads,
A.total_logical_reads,
A.last_logical_reads,
A.min_logical_reads,
A.max_logical_reads,
A.total_logical_writes,
A.last_logical_writes,
A.min_logical_writes,
A.max_logical_writes
FROM
[?].sys.dm_exec_query_stats A
CROSS APPLY [?].sys.dm_exec_sql_text(A.[sql_handle]) B
OUTER APPLY [?].sys.dm_exec_query_plan (A.plan_handle) AS C
END'
EXEC master.dbo.sp_MSforeachdb
@command1 = @Query
END
GO
Como identificar procedures “pesadas” com DMV’s
Visualizar conteúdoQuery utilizada (Ordenação por quantidade de execuções):
SELECT TOP 100
B.[name] AS rotina,
A.cached_time,
A.last_execution_time,
A.execution_count,
A.total_elapsed_time / 1000 AS total_elapsed_time_ms,
A.last_elapsed_time / 1000 AS last_elapsed_time_ms,
A.min_elapsed_time / 1000 AS min_elapsed_time_ms,
A.max_elapsed_time / 1000 AS max_elapsed_time_ms,
((A.total_elapsed_time / A.execution_count) / 1000) AS avg_elapsed_time_ms,
A.total_worker_time / 1000 AS total_worker_time_ms,
A.last_worker_time / 1000 AS last_worker_time_ms,
A.min_worker_time / 1000 AS min_worker_time_ms,
A.max_worker_time / 1000 AS max_worker_time_ms,
((A.total_worker_time / A.execution_count) / 1000) AS avg_worker_time_ms,
A.total_physical_reads,
A.last_physical_reads,
A.min_physical_reads,
A.max_physical_reads,
A.total_logical_reads,
A.last_logical_reads,
A.min_logical_reads,
A.max_logical_reads,
A.total_logical_writes,
A.last_logical_writes,
A.min_logical_writes,
A.max_logical_writes
FROM
sys.dm_exec_procedure_stats A
JOIN sys.objects B ON A.[object_id] = B.[object_id]
ORDER BY
A.execution_count DESC
Resultado:

Vale lembrar que, como estamos consultando dados de estatísticas do banco, caso o serviço seja reiniciado, esses dados são perdidos. Por este motivo, sugiro criar uma rotina que colete esses dados de tempos em tempos e armazene em uma tabela física, para quando isso acontecer, você possa continuar sua análise de onde parou e não precise esperar por horas ou dias para ter dados para continuar analisando. Caso o objeto seja alterado ou recompilado, será gerado um novo plano de execução para ele e os dados dessa view serão zerados, o que reforça a necessidade de ter esse histórico para identificar o efeito dessas mudanças de plano.
Stored Procedure para armazenar as estatísticas de SP’s de todos os databases:
USE [dirceuresende]
GO
CREATE PROCEDURE [dbo].[stpCarga_Historico_Execucao_Procedures]
AS BEGIN
IF (OBJECT_ID('dirceuresende.dbo.Historico_Execucao_Procedures') IS NULL)
BEGIN
-- DROP TABLE dirceuresende.dbo.Historico_Execucao_Procedures
CREATE TABLE dirceuresende.dbo.Historico_Execucao_Procedures (
Id_Coleta BIGINT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED,
Dt_Coleta datetime NOT NULL,
[database] sys.sysname NOT NULL,
rotina sys.sysname NOT NULL,
cached_time datetime NULL,
last_execution_time datetime NULL,
execution_count bigint NOT NULL,
total_elapsed_time_ms bigint NULL,
last_elapsed_time_ms bigint NULL,
min_elapsed_time_ms bigint NULL,
max_elapsed_time_ms bigint NULL,
avg_elapsed_time_ms bigint NULL,
total_worker_time_ms bigint NULL,
last_worker_time_ms bigint NULL,
min_worker_time_ms bigint NULL,
max_worker_time_ms bigint NULL,
avg_worker_time_ms bigint NULL,
total_physical_reads bigint NOT NULL,
last_physical_reads bigint NOT NULL,
min_physical_reads bigint NOT NULL,
max_physical_reads bigint NOT NULL,
total_logical_reads bigint NOT NULL,
last_logical_reads bigint NOT NULL,
min_logical_reads bigint NOT NULL,
max_logical_reads bigint NOT NULL,
total_logical_writes bigint NOT NULL,
last_logical_writes bigint NOT NULL,
min_logical_writes bigint NOT NULL,
max_logical_writes bigint NOT NULL
) WITH(DATA_COMPRESSION = PAGE)
CREATE INDEX SK01_Historico_Execucao_Procedures ON dirceuresende.dbo.Historico_Execucao_Procedures(Dt_Coleta, [database], rotina)
END
DECLARE
@Dt_Referencia DATETIME = GETDATE(),
@Query VARCHAR(MAX)
SET @Query = '
INSERT INTO dirceuresende.dbo.Historico_Execucao_Procedures
SELECT
''' + CONVERT(VARCHAR(19), @Dt_Referencia, 120) + ''' AS Dt_Coleta,
''?'' AS [database],
B.name AS rotina,
A.cached_time,
A.last_execution_time,
A.execution_count,
A.total_elapsed_time / 1000 AS total_elapsed_time_ms,
A.last_elapsed_time / 1000 AS last_elapsed_time_ms,
A.min_elapsed_time / 1000 AS min_elapsed_time_ms,
A.max_elapsed_time / 1000 AS max_elapsed_time_ms,
((A.total_elapsed_time / A.execution_count) / 1000) AS avg_elapsed_time_ms,
A.total_worker_time / 1000 AS total_worker_time_ms,
A.last_worker_time / 1000 AS last_worker_time_ms,
A.min_worker_time / 1000 AS min_worker_time_ms,
A.max_worker_time / 1000 AS max_worker_time_ms,
((A.total_worker_time / A.execution_count) / 1000) AS avg_worker_time_ms,
A.total_physical_reads,
A.last_physical_reads,
A.min_physical_reads,
A.max_physical_reads,
A.total_logical_reads,
A.last_logical_reads,
A.min_logical_reads,
A.max_logical_reads,
A.total_logical_writes,
A.last_logical_writes,
A.min_logical_writes,
A.max_logical_writes
FROM
[?].sys.dm_exec_procedure_stats A WITH(NOLOCK)
JOIN [?].sys.objects B WITH(NOLOCK) ON A.object_id = B.object_id'
EXEC master.dbo.sp_MSforeachdb
@command1 = @Query
END
GO
Como identificar consultas “pesadas” com a WhoIsActive
Visualizar conteúdoUtilizando essa SP, podemos acompanhar as consultas em execução na instância e avaliar quais estão consumindo mais CPU, Disco, Memória e também, acompanhar os eventos de wait de cada query e se alguma sessão está causando locks na instância:

Por este motivo, eu acho muito interessante ter uma rotina que colete os dados dessa Stored Procedure/View a cada X minutos e armazene em uma tabela física por X dias, de modo que você consiga analisar o passado em caso de uma lentidão e você queira identificar exatamente o que estava sendo executado em determinado instante e como estava o consumo de recursos (CPU, disco, memória, eventos de wait, etc) de cada consulta dessas.
Ter esse nível de informação pode ser muito útil na investigação de problemas de performance (e até outros tipos de problemas também).
Como identificar consultas “pesadas” com a sp_BlitzFirst
Visualizar conteúdoJá a sp_BlitzCache, realiza várias verificações nos planos de execução em cache na instância e procura por situações que normalmente levam à uma má performance durante a execução, como índices ausentes (Missing index), conversões implícitas, etc.
Exemplo de execução da sp_BlitzFirst (Visão geral da instância):
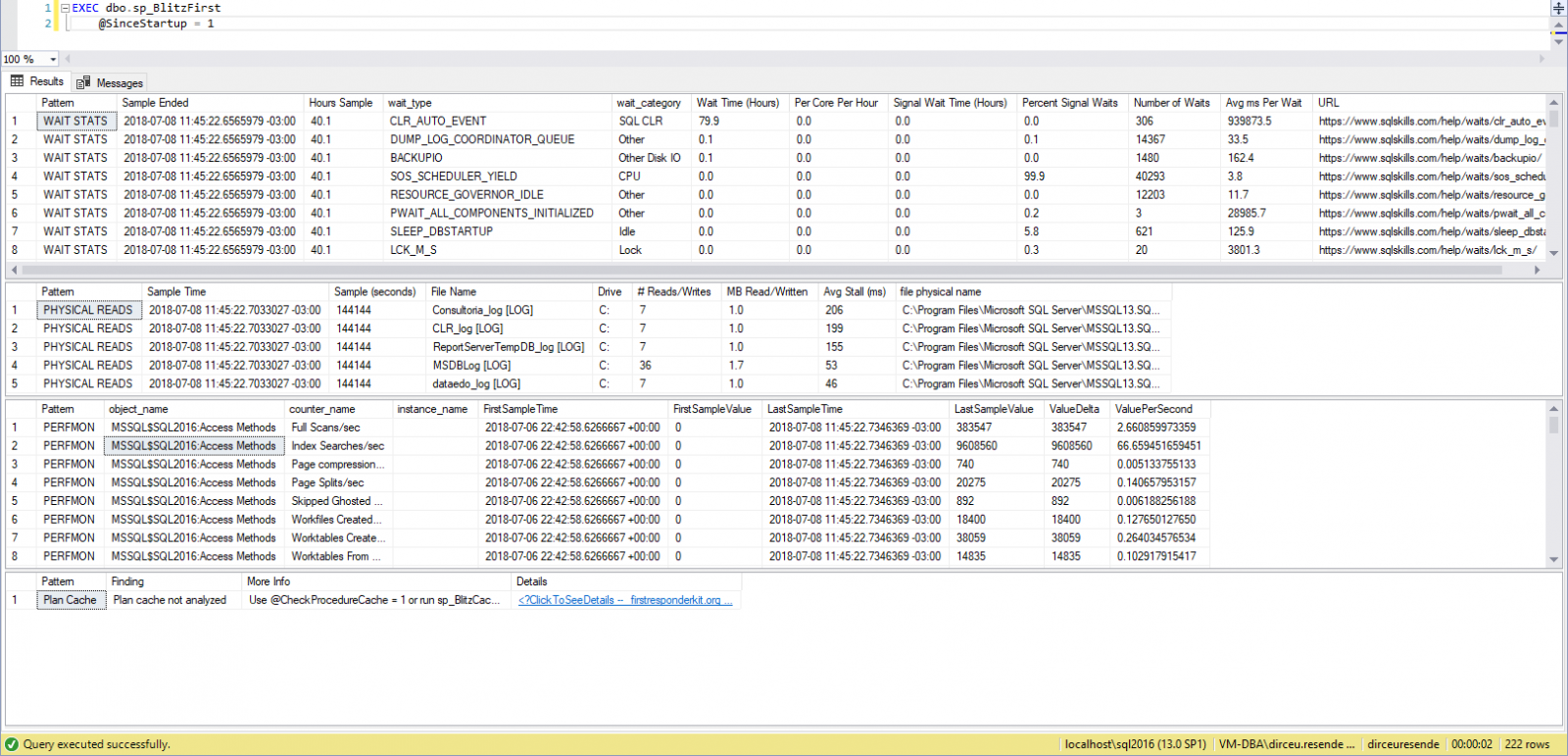
Exemplo de execução da sp_BlitzCache (Analisa os planos de execução em cache):
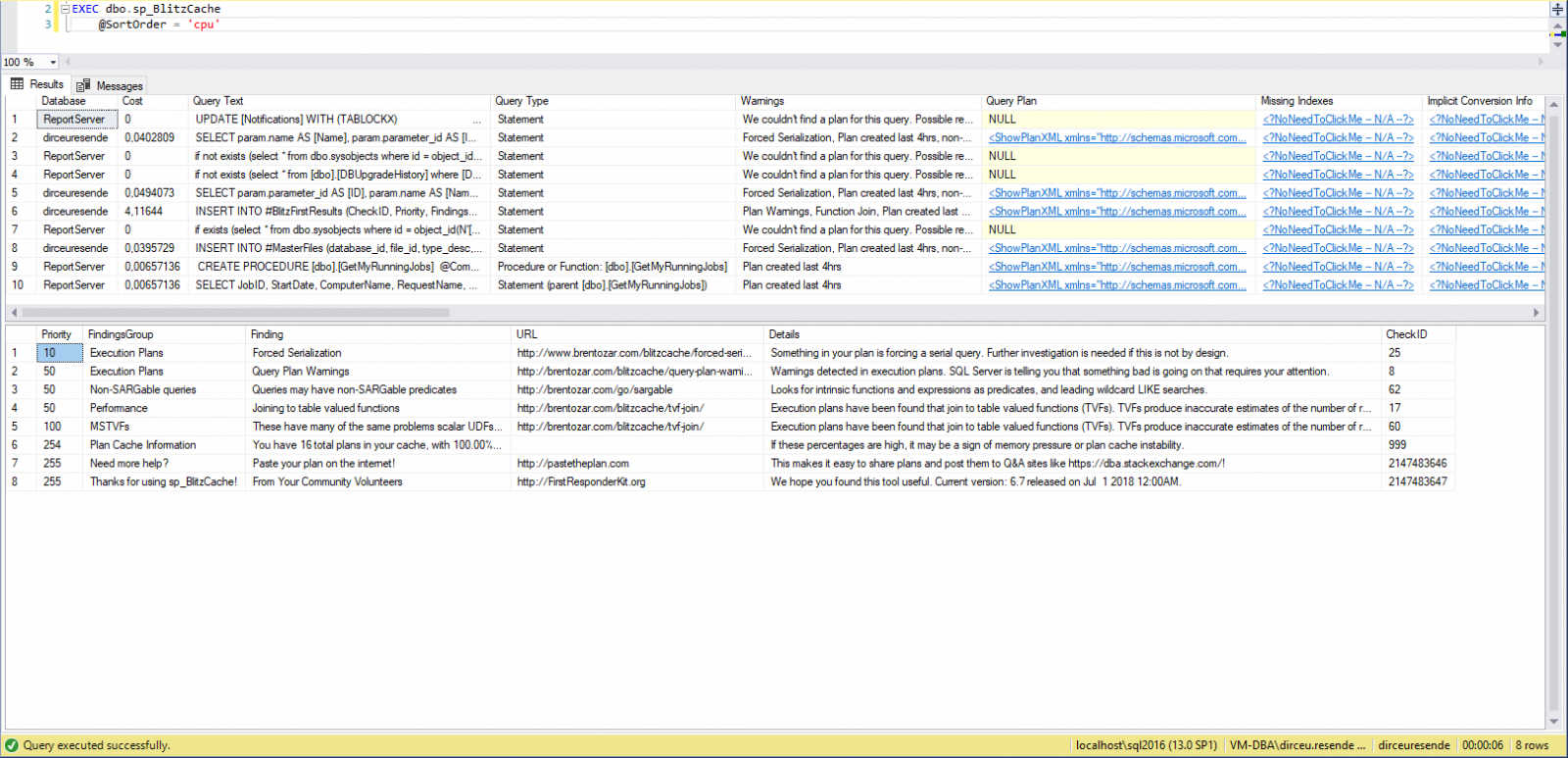
Veja como ela funciona na prática:
Download das SP’s neste link aqui.
Como identificar consultas “pesadas” com o Management Studio (SSMS)
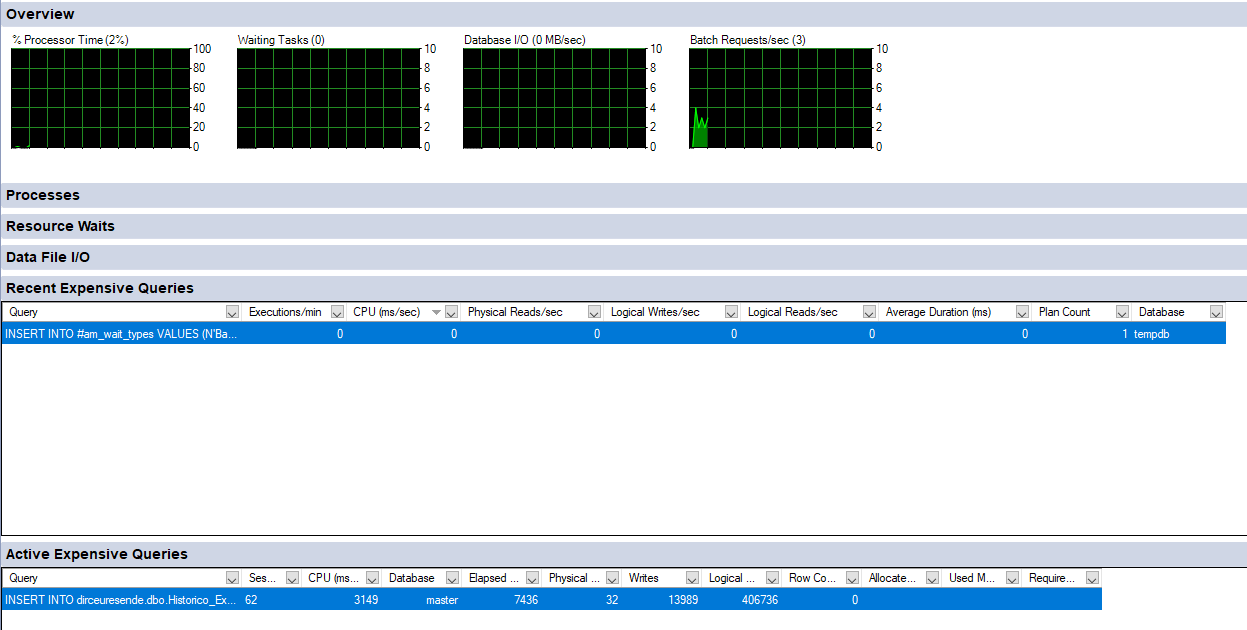
Visualizar conteúdo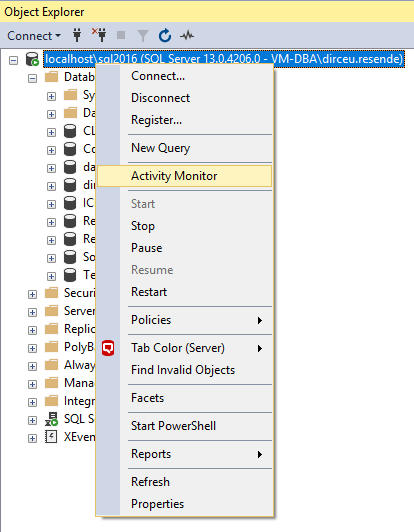
E analisando seus resultados, onde ele já mostra algumas consultas que ele julga que consomem muitos recursos da instância:
O SSMS também nos oferece vários relatórios prontos, que vão desde medir espaço em disco utilizado por cada tabela, quanto a relatórios de performance (Index Usage Statistics, Index Physical Statistics e Object Execution Statistics):
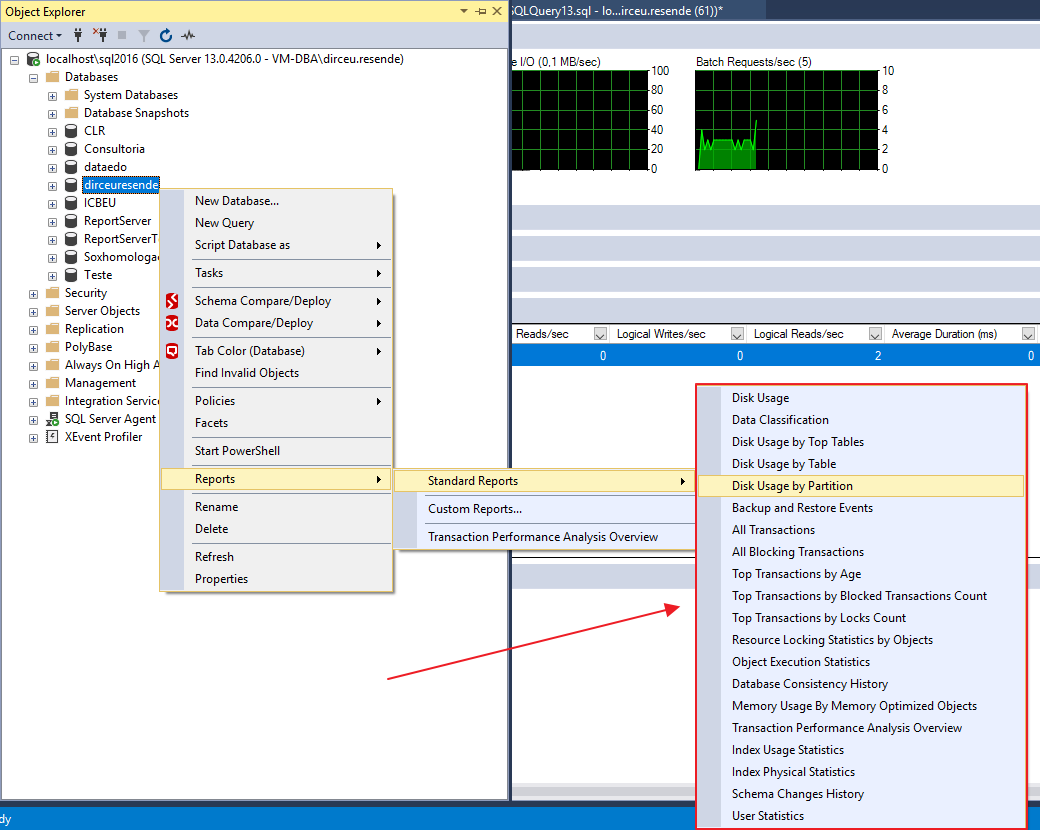
Relatório Object Execution Statistics:
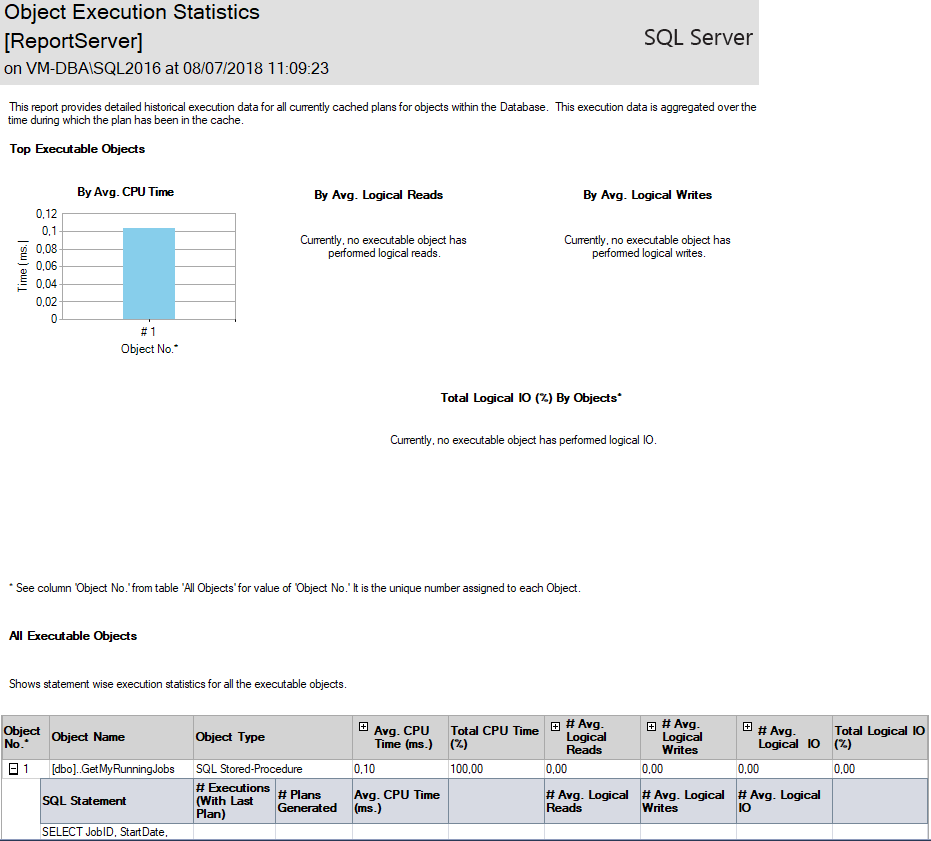
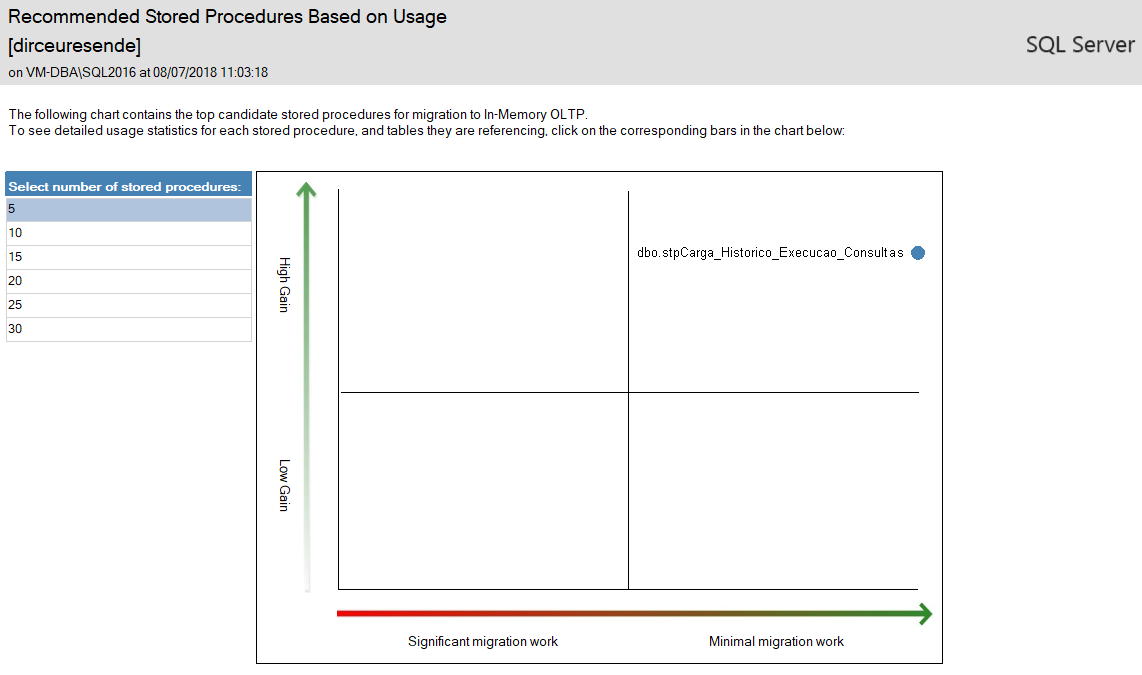
O SSMS possui até relatórios auxiliando a migração de objetos físicos (Tabelas e Stored procedures) para objetos em memória (In-Memory OLTP), através do relatório “Transaction Performance Analysis Overview”:
Como identificar consultas “pesadas” com o Perfmon
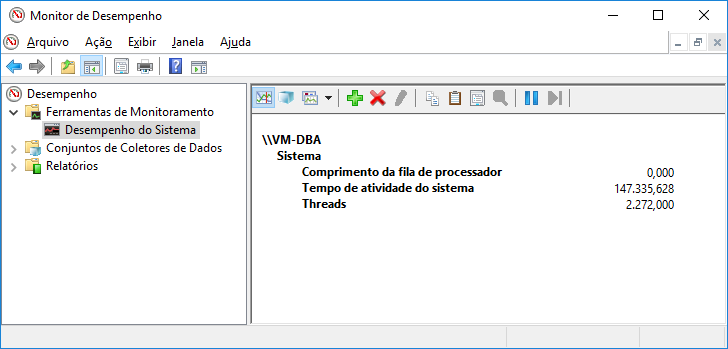
Visualizar conteúdoAcessando o Perfmon:
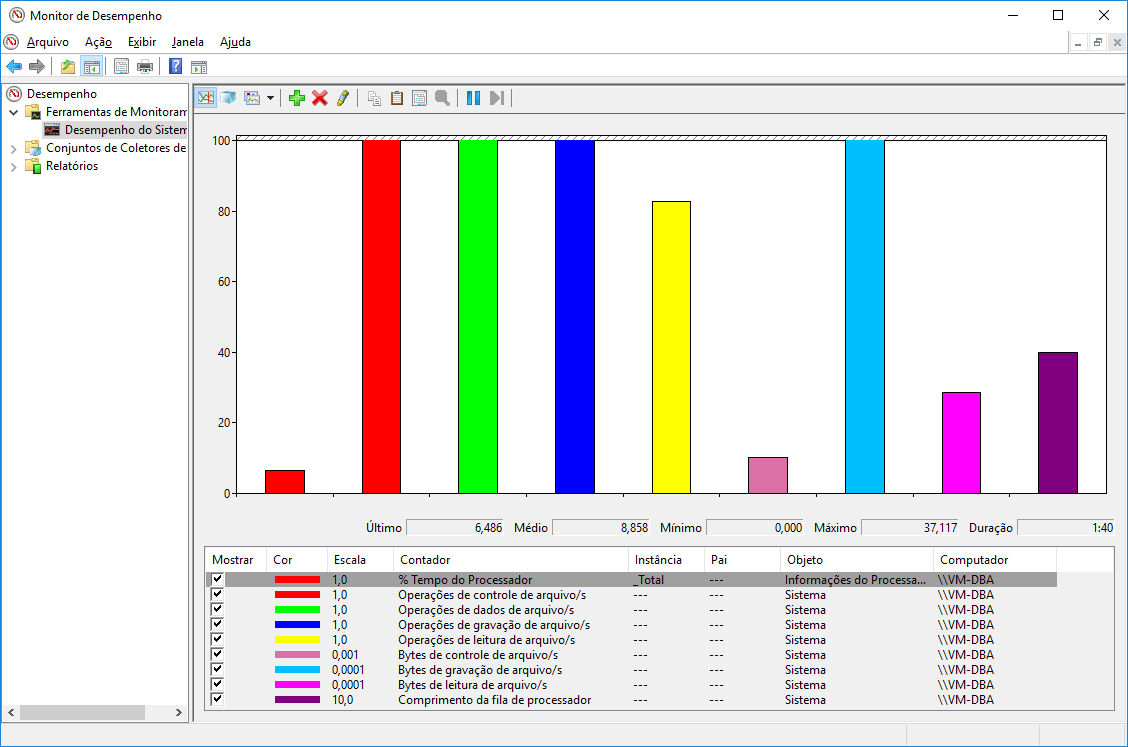
Visão gráfica:
Visão textual:
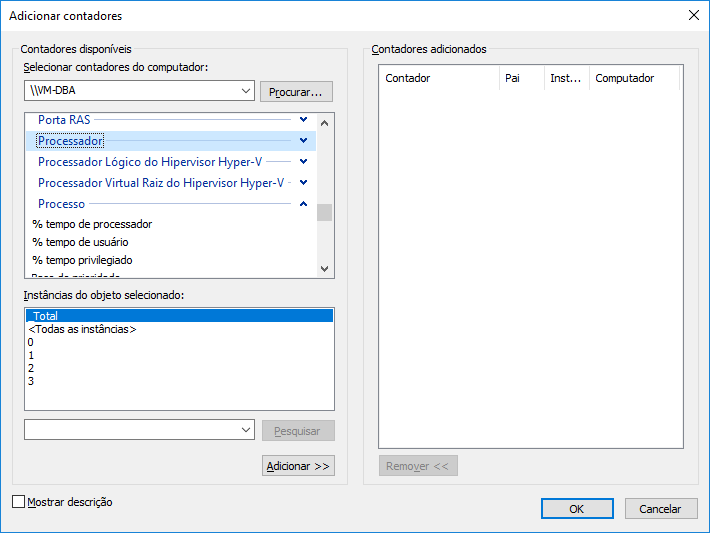
Tipos de contadores:
Vídeo do MVP Osanam Giordane sobre o Perfmon:
No artigo Contadores do Perfmon, do MCM Fabricio Catae, ele nos apresenta uma lista de contadores que costumam ser utilizados para monitorar instâncias SQL Server, que são:
Logical Disk
- Avg Disk Sec/Read
- Avg Disk Sec/Transfer
- Avg Disk Sec/Write
- Current Disk Queue Length
- Disk Bytes/sec
- Disk Read Bytes/sec
- Disk Write Bytes/sec
- Disk Reads/sec
- Disk Transfers/sec
- Disk Writes/sec
Memory
- %Committed Bytes In Use
- Available MB
- Committed Bytes
- Free System Page Table Entries
- Pool Nonpaged Bytes
- Pool Paged Bytes
Network Interfaces
- Bytes Received/sec
- Bytes Sent/sec
- Bytes Total/sec
Processor
- %Processor Time
- %Privileged Time
System
- Context Switches/sec
- Exception Dispatches/sec
- Processor Queue Length
- System Calls/sec
Adicionalmente, utilize esses contadores por instância do SQL:
Buffer Manager
- Database pages
- Free list stalls/sec
- Free pages
- Lazy writes/sec
- Page life expectancy
- Page lookups/sec
- Page reads/sec
- Readahead pages/sec
- Stolen pages
- Target pages
- Total pages
General Statistics
- Connection Reset/sec
- Logins/sec
- Logouts/sec
- User Connections
SQL Statistics
- Batch Requests/sec
- Safe Auto-Params/sec
- Forced Parametrizations/sec
- SQL Compilations/sec
- SQL Re-Compilations/sec
Para se aprofundar mais no monitoramento de instâncias SQL Server utilizando o Perfmon, não deixe de conferir os Posts de Perfmon do Ninja.
Como identificar consultas “pesadas” utilizando softwares de monitoramento
Visualizar conteúdoÉ isso aí, pessoal!
Espero que tenham gostado desse post e até a próxima!

Comentários (0)
Carregando comentários...