Neste artigo, gostaria de compartilhar com vocês um problema que tive recentemente, o qual várias colunas, de várias tabelas de um determinado database utilizavam uma collation diferente do padrão do DB, fazendo com que ao realizar joins e condições WHERE entre colunas VARCHAR/CHAR/NVARCHAR com collations diferentes, o banco nos retorne a seguinte mensagem de erro:
Cannot resolve the collation conflict between “SQL_Latin1_General_CP1_CI_AI” and “SQL_Latin1_General_CP1_CI_AS” in the equal to operation.
O que é uma COLLATION?
O Collation nada mais é do que a forma de codificação de caracteres que um banco de dados utiliza para interpretá-los.
Um Collation é um agrupamento desses caracteres em uma determinada ordem (cada Collation tem uma ordem diferente), onde o “A” é um caracter diferente do “a”, caso o collation seja case-sensitive (diferenciação de maiúsculos e minúsculos) e o “a” é diferente do “á”, caso o collation seja Accent-Sensitive (diferenciação de acentos).
O COLLATION possui três níveis de hierarquia:
– Servidor
– Database
– Coluna
Caso o database seja criado sem especificar qual a collation que será utilizada, ele será criado com a collation do servidor (idioma do sistema operacional). Quando uma tabela é criada sem especificar o collation das colunas de texto (VARCHAR, NVARCHAR, CHAR, etc), o collate do database será utilizado como o collation das tabelas.
No SQL Server, o nome da Collation segue o seguinte padrão de nomeclatura:
SQL_CollationDesignator_CaseSensitivity_AccentSensitivity_KanatypeSensitive_WidthSensitivity
Exemplo de Collation:
SQL_Latin1_General_CP1_CS_AS
Onde:
CollationDesignator: Especifica as regras de agrupamento básicas usadas pelo agrupamento do Windows, onde as regras de classificação são baseadas no alfabeto ou no idioma.
CaseSensitivity: CI especifica que não diferencia maiúsculas de minúsculas, CS especifica que diferencia maiúsculas de minúsculas.
AccentSensitivity: AI especifica que não diferencia acentos, AS especifica que diferencia acento.
KanatypeSensitive: Omitido especifica que não faz distinção de caracteres kana, KS especifica que faz distinção de caracteres kana.
WidthSensitivity: Omitido especifica que não distingue largura, WS especifica que distingue largura.
Se uma coluna estiver utilizando uma COLLATION case sensitive (CS), uma query como SELECT * FROM Tabela WHERE Coluna LIKE ‘%Oracle%’ irá retornar o registro “Oracle”, mas não irá retornar o registro “oracle”.
A mesma coisa acontece com uma coluna utilizando um COLLATION accent sensitive (AS). Uma query como SELECT * FROM Tabela WHERE Coluna LIKE ‘%JOÃO%’ irá retornar o registro “João”, mas não irá retornar o registro “Joao”.
Para verificar a lista completa de Collations por região e idioma, acesse este link, lembrando que o mais utilizado no idioma Português (Brasil) é o SQL_Latin1_General_CP1_CI_AI (ou SQL_Latin1_General_CP1_CS_AS).
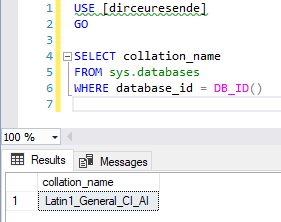
Para identificar a collation padrão de um database, basta utilizar a query abaixo:
USE [dirceuresende]
GO
SELECT collation_name
FROM sys.databases
WHERE database_id = DB_ID()
Resultado:
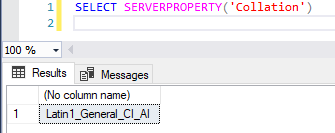
Para identificar a collation padrão da sua instância, basta utilizar o comando abaixo:
SELECT SERVERPROPERTY('Collation')
Resultado:
Geração da base para os testes
Para padronizar os exemplos e ajudar no entendimento prático desse artigo, vou utilizar um script simples para gerar dados de exemplo (testes):
------------------------------------------------------------------------
-- Geração dos dados para teste
------------------------------------------------------------------------
CREATE TABLE dbo.Cliente (
CPF VARCHAR(11) COLLATE Latin1_General_CS_AS NOT NULL PRIMARY KEY CLUSTERED,
Nome VARCHAR(50)
)
INSERT INTO dbo.Cliente ( CPF, Nome )
VALUES ( '12345678909', 'Joãozinho' )
CREATE NONCLUSTERED INDEX SK01 ON dbo.Cliente(CPF) INCLUDE(Nome)
CREATE TABLE dbo.Pedido (
Id INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED,
Dt_Pedido DATETIME DEFAULT GETDATE(),
Vl_Pedido MONEY,
CPF_Cliente VARCHAR(11) COLLATE Latin1_General_CS_AS CONSTRAINT [FK_Cliente] FOREIGN KEY(CPF_Cliente) REFERENCES dbo.Cliente(CPF) NOT NULL
)
INSERT INTO dbo.Pedido ( Vl_Pedido, CPF_Cliente )
VALUES
(
9.99, -- Vl_Pedido - money
'12345678909' -- Id_Cliente - int
)
CREATE NONCLUSTERED INDEX SK02 ON dbo.Pedido(Id, Dt_Pedido, CPF_Cliente)
Como padronizar a collation de todas as colunas?
Caso você queira padronizar a collation de todas as colunas de um database, de modo que elas utilizem uma collation específica ou a padrão do database, desenvolvi um script que irá identificar todas as colunas que estão fora do padrão e irá executar um comando de ALTER TABLE para aplicar a alteração.
Como existem dependências (constraints, índices e foreign keys), o script irá dropar os objetos dependentes identificados, aplicar as alterações e recriar esses objetos. Por conta disso, recomendo fortemente que você teste bem antes de executar esse script em produção. De preferência, faça um backup de estrutura antes.
Script para alterar a collation de todas as colunas (e dependências) que estejam com o Collation diferente do database Visualizar código-fonte
SET NOCOUNT ON
-------------------------------------------------------------------------
-- Identifica as colunas com collation diferente do padrão do database conectado
-------------------------------------------------------------------------
IF (OBJECT_ID('tempdb..#Colunas') IS NOT NULL) DROP TABLE #Colunas
SELECT
B.[object_id] AS table_object_id,
B.[name] AS table_name,
B.[schema_id] AS table_schema_id,
C.[name] AS [type_name],
D.[name] AS [schema_name],
D.[schema_id],
A.*,
C.system_type_id AS type_system_type_id,
C.user_type_id AS type_user_type_id,
C.collation_name AS type_collation_name,
E.collation_name AS [database_default_collation]
INTO
#Colunas
FROM
sys.columns AS A
JOIN sys.tables AS B ON A.[object_id] = B.[object_id]
JOIN sys.types AS C ON A.user_type_id = C.user_type_id
JOIN sys.schemas AS D ON B.[schema_id] = D.[schema_id]
JOIN sys.databases AS E ON E.database_id = DB_ID()
WHERE
B.is_ms_shipped = 0
AND A.collation_name <> E.collation_name COLLATE DATABASE_DEFAULT
IF (OBJECT_ID('tempdb..#Tabelas') IS NOT NULL) DROP table #Tabelas
SELECT DISTINCT
table_object_id,
table_name,
table_schema_id,
[schema_name]
INTO
#Tabelas
FROM
#Colunas
-------------------------------------------------------------------------
-- Identifica os índices que utilizam essas colunas
-------------------------------------------------------------------------
IF (OBJECT_ID('tempdb..#Indices') IS NOT NULL) DROP TABLE #Indices
SELECT
A.*,
B.[name] AS index_name,
B.[type],
B.[type_desc],
B.is_unique,
B.is_primary_key,
B.is_unique_constraint,
B.is_disabled
INTO
#Indices
FROM
#Colunas A
JOIN sys.indexes B ON A.table_object_id = B.[object_id]
WHERE
EXISTS(SELECT NULL FROM sys.index_columns X WHERE X.index_id = B.index_id AND X.column_id = A.column_id)
IF (OBJECT_ID('tempdb..#Indices_Alteracao') IS NOT NULL) DROP TABLE #Indices_Alteracao
SELECT DISTINCT
table_object_id,
table_schema_id,
table_name,
[schema_name],
type_collation_name,
database_default_collation,
index_name,
is_unique_constraint,
is_primary_key
INTO
#Indices_Alteracao
FROM
#Indices
-------------------------------------------------------------------------
-- Gera os scripts
-------------------------------------------------------------------------
DECLARE
@CmdAlterTable VARCHAR(MAX) = '',
@CmdDropIndex VARCHAR(MAX) = '',
@CmdCreateIndex VARCHAR(MAX) = '',
@CmdDropFK VARCHAR(MAX) = '',
@CmdCreateFK VARCHAR(MAX) = '',
@CmdDropIndexConstraint VARCHAR(MAX) = '',
@CmdCreateIndexConstraint VARCHAR(MAX) = '',
@CmdDisableCK VARCHAR(MAX) = '',
@CmdEnableCK VARCHAR(MAX) = '',
@Fl_Debug BIT = 1
SELECT
@CmdDropIndex += (CASE WHEN is_unique_constraint = 0 AND is_primary_key = 0 THEN 'DROP INDEX [' + index_name + '] ON [' + [schema_name] + '].[' + table_name + ']; ' ELSE '' END),
@CmdDropIndexConstraint += (CASE WHEN is_unique_constraint = 1 OR is_primary_key = 1 THEN 'ALTER TABLE [' + [schema_name] + '].[' + table_name + '] DROP CONSTRAINT [' + index_name + ']; ' ELSE '' END),
@CmdDisableCK += 'ALTER TABLE [' + [schema_name] + '].[' + table_name + '] NOCHECK CONSTRAINT ALL; ',
@CmdEnableCK += 'ALTER TABLE [' + [schema_name] + '].[' + table_name + '] CHECK CONSTRAINT ALL; '
FROM
#Indices_Alteracao
-------------------------------------------------------------------------
-- Identifica AS FK's que utilizam essas colunas
-------------------------------------------------------------------------
SELECT
@CmdDropFK += N'ALTER TABLE ' + QUOTENAME(C.[name]) + '.' + QUOTENAME(B.[name]) + ' DROP CONSTRAINT ' + QUOTENAME(A.[name]) + ';'
FROM
sys.foreign_keys AS A
JOIN sys.tables AS B ON A.parent_object_id = B.[object_id]
JOIN sys.schemas AS C ON B.[schema_id] = C.[schema_id]
JOIN #Tabelas AS D ON B.[object_id] = D.table_object_id
SELECT
@CmdCreateFK += N'ALTER TABLE ' + QUOTENAME(H.[name]) + '.' + QUOTENAME(G.[name]) + ' ADD CONSTRAINT ' + QUOTENAME(D.[name]) + ' FOREIGN KEY (' +
STUFF((
SELECT
',' + QUOTENAME(A.[name])
FROM
sys.columns AS A
INNER JOIN sys.foreign_key_columns AS B ON B.parent_column_id = A.column_id AND B.parent_object_id = A.[object_id]
WHERE
B.constraint_object_id = D.[object_id]
ORDER BY
B.constraint_column_id
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 1, N'') + ') REFERENCES ' + QUOTENAME(F.[name]) + '.' + QUOTENAME(E.[name]) + '(' +
STUFF((
SELECT
',' + QUOTENAME(C.[name])
FROM
sys.columns AS C
INNER JOIN sys.foreign_key_columns AS fkc ON fkc.referenced_column_id = C.column_id AND fkc.referenced_object_id = C.[object_id]
WHERE
fkc.constraint_object_id = D.[object_id]
ORDER BY
fkc.constraint_column_id
FOR XML PATH(N''), TYPE
).value(N'.[1]', N'nvarchar(max)'), 1, 1, N''
) + ');'
FROM
sys.foreign_keys AS D
JOIN sys.tables AS E ON D.referenced_object_id = E.[object_id]
JOIN sys.schemas AS F ON E.[schema_id] = F.[schema_id]
JOIN sys.tables AS G ON D.parent_object_id = G.[object_id]
JOIN sys.schemas AS H ON G.[schema_id] = H.[schema_id]
JOIN #Tabelas AS I ON G.[object_id] = I.table_object_id
WHERE
E.is_ms_shipped = 0
AND G.is_ms_shipped = 0
SELECT
@CmdCreateIndex += (CASE WHEN B.is_unique_constraint = 0 AND B.is_primary_key = 0 THEN 'CREATE ' + (CASE WHEN B.is_unique = 1 THEN 'UNIQUE ' ELSE '' END) + B.[type_desc] COLLATE DATABASE_DEFAULT + ' INDEX [' + B.[name] + '] ON [' + SCHEMA_NAME(C.[schema_id]) + '].[' + C.[name] + '] (' + E.KeyColumns + ')' + ISNULL(' INCLUDE (' + I.IncludedColumns + ')', '') + ISNULL(' WHERE ' + B.filter_definition, '') + ' WITH (' + CASE WHEN B.is_padded = 1 THEN 'PAD_INDEX = ON' ELSE 'PAD_INDEX = OFF' END + ', ' + 'FILLFACTOR = ' + CONVERT(VARCHAR(5), CASE WHEN B.fill_factor = 0 THEN 100 ELSE B.fill_factor END) + ', ' +
'SORT_IN_TEMPDB = OFF, ' + (CASE WHEN B.[ignore_dup_key] = 1 THEN 'IGNORE_DUP_KEY = ON' ELSE 'IGNORE_DUP_KEY = OFF' END) + ', ' + (CASE WHEN F.no_recompute = 0 THEN 'STATISTICS_NORECOMPUTE = OFF' ELSE 'STATISTICS_NORECOMPUTE = ON' END) + ', ' +
'ONLINE = OFF, DATA_COMPRESSION = PAGE, ' + (CASE WHEN B.[allow_row_locks] = 1 THEN 'ALLOW_ROW_LOCKS = ON' ELSE 'ALLOW_ROW_LOCKS = OFF' END) + ', ' + (CASE WHEN B.[allow_page_locks] = 1 THEN 'ALLOW_PAGE_LOCKS = ON' ELSE 'ALLOW_PAGE_LOCKS = OFF' END) + ') ON [' + G.[name] + ']; ' ELSE '' END),
@CmdCreateIndexConstraint += (CASE WHEN B.is_unique_constraint = 1 OR B.is_primary_key = 1 THEN 'ALTER TABLE [' + A.[schema_name] + '].[' + A.table_name + '] ADD CONSTRAINT [' + A.index_name + '] ' + (CASE WHEN B.is_primary_key = 1 THEN 'PRIMARY KEY ' ELSE '' END) + (CASE WHEN B.is_unique = 1 AND B.is_primary_key = 0 THEN 'UNIQUE ' ELSE '' END) + B.[type_desc] COLLATE DATABASE_DEFAULT + ' (' + E.KeyColumns + ')' + ISNULL(' INCLUDE (' + I.IncludedColumns + ')', '') + ISNULL(' WHERE ' + B.filter_definition, '') + ' WITH (' + CASE WHEN B.is_padded = 1 THEN 'PAD_INDEX = ON' ELSE 'PAD_INDEX = OFF' END + ', ' + 'FILLFACTOR = ' + CONVERT(VARCHAR(5), CASE WHEN B.fill_factor = 0 THEN 100 ELSE B.fill_factor END) + ', ' +
'SORT_IN_TEMPDB = OFF, ' + (CASE WHEN B.[ignore_dup_key] = 1 THEN 'IGNORE_DUP_KEY = ON' ELSE 'IGNORE_DUP_KEY = OFF' END) + ', ' + (CASE WHEN F.no_recompute = 0 THEN 'STATISTICS_NORECOMPUTE = OFF' ELSE 'STATISTICS_NORECOMPUTE = ON' END) + ', ' +
'ONLINE = OFF, DATA_COMPRESSION = PAGE, ' + (CASE WHEN B.[allow_row_locks] = 1 THEN 'ALLOW_ROW_LOCKS = ON' ELSE 'ALLOW_ROW_LOCKS = OFF' END) + ', ' + (CASE WHEN B.[allow_page_locks] = 1 THEN 'ALLOW_PAGE_LOCKS = ON' ELSE 'ALLOW_PAGE_LOCKS = OFF' END) + ') ON [' + G.[name] + ']; ' ELSE '' END)
FROM
#Indices_Alteracao AS A
JOIN sys.indexes AS B ON A.table_object_id = B.[object_id] AND A.index_name = B.[name] COLLATE DATABASE_DEFAULT
JOIN sys.tables AS C ON C.[object_id] = B.[object_id]
JOIN sys.indexes AS D ON B.[object_id] = D.[object_id] AND B.index_id = D.index_id
JOIN
(
SELECT
*
FROM
(
SELECT
X3.[object_id],
X3.index_id,
STUFF((
SELECT
', [' + X2.[name] + ']' + CASE WHEN MAX(CONVERT(INT, X1.is_descending_key)) = 1 THEN ' DESC' ELSE '' END
FROM
sys.index_columns AS X1
JOIN sys.columns AS X2 ON X2.[object_id] = X1.[object_id] AND X2.column_id = X1.column_id AND X1.is_included_column = 0
WHERE
X1.[object_id] = X3.[object_id]
AND X1.index_id = X3.index_id
GROUP BY
X1.[object_id],
X2.[name],
X1.index_id
ORDER BY
MAX(X1.key_ordinal)
FOR XML PATH('')
), 1, 2, ''
) AS KeyColumns
FROM
sys.index_columns AS X3
GROUP BY
X3.[object_id],
X3.index_id
) AS X4
) AS E ON B.[object_id] = E.[object_id] AND B.index_id = E.index_id
JOIN sys.stats AS F ON F.[object_id] = B.[object_id] AND F.stats_id = B.index_id
JOIN sys.data_spaces AS G ON B.data_space_id = G.data_space_id
JOIN sys.filegroups AS H ON B.data_space_id = H.data_space_id
LEFT JOIN
(
SELECT
*
FROM
(
SELECT
X3.[object_id],
X3.index_id,
STUFF((
SELECT
', [' + X2.[name] + ']'
FROM
sys.index_columns AS X1
JOIN sys.columns AS X2 ON X2.[object_id] = X1.[object_id] AND X2.column_id = X1.column_id AND X1.is_included_column = 1
WHERE
X1.[object_id] = X3.[object_id]
AND X1.index_id = X3.index_id
GROUP BY
X1.[object_id],
X2.[name],
X1.index_id
FOR XML PATH('')
), 1, 2, ''
) AS IncludedColumns
FROM
sys.index_columns AS X3
GROUP BY
X3.[object_id],
X3.index_id
) AS tmp1
WHERE
IncludedColumns IS NOT NULL
) AS I ON I.[object_id] = B.[object_id] AND I.index_id = B.index_id
SELECT
@CmdAlterTable += 'ALTER TABLE [' + [schema_name] + '].[' + table_name + '] ALTER COLUMN [' + [name] + '] ' + UPPER([type_name]) + (CASE WHEN UPPER([type_name]) <> 'SYSNAME' THEN '(' + (CASE WHEN A.max_length > 0 THEN CAST(A.max_length AS VARCHAR(10)) ELSE 'MAX' END) + ')' ELSE '' END) + ' COLLATE ' + [database_default_collation] + ' ' + (CASE WHEN A.is_sparse = 1 THEN 'SPARSE ' ELSE '' END) + (CASE WHEN A.is_nullable = 1 THEN 'NULL' ELSE 'NOT NULL' END) + ';'
FROM
#Colunas A
-------------------------------------------------------------------------
-- Executa os scripts
-------------------------------------------------------------------------
PRINT '---------- Dropando as contraints FK'
IF (NULLIF(LTRIM(RTRIM(@CmdDropFK)), '') IS NOT NULL) PRINT @CmdDropFK
IF (@Fl_Debug = 0) EXEC(@CmdDropFK)
PRINT '---------- Desativando as Check Contraints'
IF (NULLIF(LTRIM(RTRIM(@CmdDisableCK)), '') IS NOT NULL) PRINT @CmdDisableCK
IF (@Fl_Debug = 0) EXEC(@CmdDisableCK)
PRINT '---------- Dropando os índices'
IF (NULLIF(LTRIM(RTRIM(@CmdDropIndex)), '') IS NOT NULL) PRINT @CmdDropIndex
IF (@Fl_Debug = 0) EXEC(@CmdDropIndex)
PRINT '---------- Dropando os índices em constraints'
IF (NULLIF(LTRIM(RTRIM(@CmdDropIndexConstraint)), '') IS NOT NULL) PRINT @CmdDropIndexConstraint
IF (@Fl_Debug = 0) EXEC(@CmdDropIndexConstraint)
PRINT '---------- Alterando a tabela'
IF (NULLIF(LTRIM(RTRIM(@CmdAlterTable)), '') IS NOT NULL) PRINT @CmdAlterTable
IF (@Fl_Debug = 0) EXEC(@CmdAlterTable)
PRINT '---------- Reativando as constraints'
IF (NULLIF(LTRIM(RTRIM(@CmdEnableCK)), '') IS NOT NULL) PRINT @CmdEnableCK
IF (@Fl_Debug = 0) EXEC(@CmdEnableCK)
PRINT '---------- Recriando os índices'
IF (NULLIF(LTRIM(RTRIM(@CmdCreateIndex)), '') IS NOT NULL) PRINT @CmdCreateIndex
IF (@Fl_Debug = 0) EXEC(@CmdCreateIndex)
PRINT '---------- Recriando os índices em constraints'
IF (NULLIF(LTRIM(RTRIM(@CmdCreateIndexConstraint)), '') IS NOT NULL) PRINT @CmdCreateIndexConstraint
IF (@Fl_Debug = 0) EXEC(@CmdCreateIndexConstraint)
PRINT '---------- Recriando as FKs'
IF (NULLIF(LTRIM(RTRIM(@CmdCreateFK)), '') IS NOT NULL) PRINT @CmdCreateFK
IF (@Fl_Debug = 0) EXEC(@CmdCreateFK)
Script para alterar o collation de todas as colunas (e dependências) de acordo com o Collation desejado: Visualizar código-fonte
SET NOCOUNT ON
-------------------------------------------------------------------------
-- Identifica as colunas com collation diferente do desejado
-------------------------------------------------------------------------
DECLARE
@Collation_Desejado VARCHAR(100) = 'SQL_Latin1_General_CP1_CI_AI' -- SELECT * FROM sys.fn_helpcollations()
IF (OBJECT_ID('tempdb..#Colunas') IS NOT NULL) DROP TABLE #Colunas
SELECT
B.[object_id] AS table_object_id,
B.[name] AS table_name,
B.[schema_id] AS table_schema_id,
C.[name] AS [type_name],
D.[name] AS [schema_name],
D.[schema_id],
A.*,
C.system_type_id AS type_system_type_id,
C.user_type_id AS type_user_type_id,
C.collation_name AS type_collation_name,
E.collation_name AS [database_default_collation]
INTO
#Colunas
FROM
sys.columns AS A
JOIN sys.tables AS B ON A.[object_id] = B.[object_id]
JOIN sys.types AS C ON A.user_type_id = C.user_type_id
JOIN sys.schemas AS D ON B.[schema_id] = D.[schema_id]
JOIN sys.databases AS E ON E.database_id = DB_ID()
WHERE
B.is_ms_shipped = 0
AND A.collation_name <> @Collation_Desejado
IF (OBJECT_ID('tempdb..#Tabelas') IS NOT NULL) DROP table #Tabelas
SELECT DISTINCT
table_object_id,
table_name,
table_schema_id,
[schema_name]
INTO
#Tabelas
FROM
#Colunas
-------------------------------------------------------------------------
-- Identifica os índices que utilizam essas colunas
-------------------------------------------------------------------------
IF (OBJECT_ID('tempdb..#Indices') IS NOT NULL) DROP TABLE #Indices
SELECT
A.*,
B.[name] AS index_name,
B.[type],
B.[type_desc],
B.is_unique,
B.is_primary_key,
B.is_unique_constraint,
B.is_disabled
INTO
#Indices
FROM
#Colunas A
JOIN sys.indexes B ON A.table_object_id = B.[object_id]
WHERE
EXISTS(SELECT NULL FROM sys.index_columns X WHERE X.index_id = B.index_id AND X.column_id = A.column_id)
IF (OBJECT_ID('tempdb..#Indices_Alteracao') IS NOT NULL) DROP TABLE #Indices_Alteracao
SELECT DISTINCT
table_object_id,
table_schema_id,
table_name,
[schema_name],
type_collation_name,
database_default_collation,
index_name,
is_unique_constraint,
is_primary_key
INTO
#Indices_Alteracao
FROM
#Indices
-------------------------------------------------------------------------
-- Gera os scripts
-------------------------------------------------------------------------
DECLARE
@CmdAlterTable VARCHAR(MAX) = '',
@CmdDropIndex VARCHAR(MAX) = '',
@CmdCreateIndex VARCHAR(MAX) = '',
@CmdDropFK VARCHAR(MAX) = '',
@CmdCreateFK VARCHAR(MAX) = '',
@CmdDropIndexConstraint VARCHAR(MAX) = '',
@CmdCreateIndexConstraint VARCHAR(MAX) = '',
@CmdDisableCK VARCHAR(MAX) = '',
@CmdEnableCK VARCHAR(MAX) = '',
@Fl_Debug BIT = 1
SELECT
@CmdDropIndex += (CASE WHEN is_unique_constraint = 0 AND is_primary_key = 0 THEN 'DROP INDEX [' + index_name + '] ON [' + [schema_name] + '].[' + table_name + ']; ' ELSE '' END),
@CmdDropIndexConstraint += (CASE WHEN is_unique_constraint = 1 OR is_primary_key = 1 THEN 'ALTER TABLE [' + [schema_name] + '].[' + table_name + '] DROP CONSTRAINT [' + index_name + ']; ' ELSE '' END),
@CmdDisableCK += 'ALTER TABLE [' + [schema_name] + '].[' + table_name + '] NOCHECK CONSTRAINT ALL; ',
@CmdEnableCK += 'ALTER TABLE [' + [schema_name] + '].[' + table_name + '] CHECK CONSTRAINT ALL; '
FROM
#Indices_Alteracao
-------------------------------------------------------------------------
-- Identifica AS FK's que utilizam essas colunas
-------------------------------------------------------------------------
SELECT
@CmdDropFK += N'ALTER TABLE ' + QUOTENAME(C.[name]) + '.' + QUOTENAME(B.[name]) + ' DROP CONSTRAINT ' + QUOTENAME(A.[name]) + ';'
FROM
sys.foreign_keys AS A
JOIN sys.tables AS B ON A.parent_object_id = B.[object_id]
JOIN sys.schemas AS C ON B.[schema_id] = C.[schema_id]
JOIN #Tabelas AS D ON B.[object_id] = D.table_object_id
SELECT
@CmdCreateFK += N'ALTER TABLE ' + QUOTENAME(H.[name]) + '.' + QUOTENAME(G.[name]) + ' ADD CONSTRAINT ' + QUOTENAME(D.[name]) + ' FOREIGN KEY (' +
STUFF((
SELECT
',' + QUOTENAME(A.[name])
FROM
sys.columns AS A
INNER JOIN sys.foreign_key_columns AS B ON B.parent_column_id = A.column_id AND B.parent_object_id = A.[object_id]
WHERE
B.constraint_object_id = D.[object_id]
ORDER BY
B.constraint_column_id
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 1, N'') + ') REFERENCES ' + QUOTENAME(F.[name]) + '.' + QUOTENAME(E.[name]) + '(' +
STUFF((
SELECT
',' + QUOTENAME(C.[name])
FROM
sys.columns AS C
INNER JOIN sys.foreign_key_columns AS fkc ON fkc.referenced_column_id = C.column_id AND fkc.referenced_object_id = C.[object_id]
WHERE
fkc.constraint_object_id = D.[object_id]
ORDER BY
fkc.constraint_column_id
FOR XML PATH(N''), TYPE
).value(N'.[1]', N'nvarchar(max)'), 1, 1, N''
) + ');'
FROM
sys.foreign_keys AS D
JOIN sys.tables AS E ON D.referenced_object_id = E.[object_id]
JOIN sys.schemas AS F ON E.[schema_id] = F.[schema_id]
JOIN sys.tables AS G ON D.parent_object_id = G.[object_id]
JOIN sys.schemas AS H ON G.[schema_id] = H.[schema_id]
JOIN #Tabelas AS I ON G.[object_id] = I.table_object_id
WHERE
E.is_ms_shipped = 0
AND G.is_ms_shipped = 0
SELECT
@CmdCreateIndex += (CASE WHEN B.is_unique_constraint = 0 AND B.is_primary_key = 0 THEN 'CREATE ' + (CASE WHEN B.is_unique = 1 THEN 'UNIQUE ' ELSE '' END) + B.[type_desc] COLLATE DATABASE_DEFAULT + ' INDEX [' + B.[name] + '] ON [' + SCHEMA_NAME(C.[schema_id]) + '].[' + C.[name] + '] (' + E.KeyColumns + ')' + ISNULL(' INCLUDE (' + I.IncludedColumns + ')', '') + ISNULL(' WHERE ' + B.filter_definition, '') + ' WITH (' + CASE WHEN B.is_padded = 1 THEN 'PAD_INDEX = ON' ELSE 'PAD_INDEX = OFF' END + ', ' + 'FILLFACTOR = ' + CONVERT(VARCHAR(5), CASE WHEN B.fill_factor = 0 THEN 100 ELSE B.fill_factor END) + ', ' +
'SORT_IN_TEMPDB = OFF, ' + (CASE WHEN B.[ignore_dup_key] = 1 THEN 'IGNORE_DUP_KEY = ON' ELSE 'IGNORE_DUP_KEY = OFF' END) + ', ' + (CASE WHEN F.no_recompute = 0 THEN 'STATISTICS_NORECOMPUTE = OFF' ELSE 'STATISTICS_NORECOMPUTE = ON' END) + ', ' +
'ONLINE = OFF, DATA_COMPRESSION = PAGE, ' + (CASE WHEN B.[allow_row_locks] = 1 THEN 'ALLOW_ROW_LOCKS = ON' ELSE 'ALLOW_ROW_LOCKS = OFF' END) + ', ' + (CASE WHEN B.[allow_page_locks] = 1 THEN 'ALLOW_PAGE_LOCKS = ON' ELSE 'ALLOW_PAGE_LOCKS = OFF' END) + ') ON [' + G.[name] + ']; ' ELSE '' END),
@CmdCreateIndexConstraint += (CASE WHEN B.is_unique_constraint = 1 OR B.is_primary_key = 1 THEN 'ALTER TABLE [' + A.[schema_name] + '].[' + A.table_name + '] ADD CONSTRAINT [' + A.index_name + '] ' + (CASE WHEN B.is_primary_key = 1 THEN 'PRIMARY KEY ' ELSE '' END) + (CASE WHEN B.is_unique = 1 AND B.is_primary_key = 0 THEN 'UNIQUE ' ELSE '' END) + B.[type_desc] COLLATE DATABASE_DEFAULT + ' (' + E.KeyColumns + ')' + ISNULL(' INCLUDE (' + I.IncludedColumns + ')', '') + ISNULL(' WHERE ' + B.filter_definition, '') + ' WITH (' + CASE WHEN B.is_padded = 1 THEN 'PAD_INDEX = ON' ELSE 'PAD_INDEX = OFF' END + ', ' + 'FILLFACTOR = ' + CONVERT(VARCHAR(5), CASE WHEN B.fill_factor = 0 THEN 100 ELSE B.fill_factor END) + ', ' +
'SORT_IN_TEMPDB = OFF, ' + (CASE WHEN B.[ignore_dup_key] = 1 THEN 'IGNORE_DUP_KEY = ON' ELSE 'IGNORE_DUP_KEY = OFF' END) + ', ' + (CASE WHEN F.no_recompute = 0 THEN 'STATISTICS_NORECOMPUTE = OFF' ELSE 'STATISTICS_NORECOMPUTE = ON' END) + ', ' +
'ONLINE = OFF, DATA_COMPRESSION = PAGE, ' + (CASE WHEN B.[allow_row_locks] = 1 THEN 'ALLOW_ROW_LOCKS = ON' ELSE 'ALLOW_ROW_LOCKS = OFF' END) + ', ' + (CASE WHEN B.[allow_page_locks] = 1 THEN 'ALLOW_PAGE_LOCKS = ON' ELSE 'ALLOW_PAGE_LOCKS = OFF' END) + ') ON [' + G.[name] + ']; ' ELSE '' END)
FROM
#Indices_Alteracao AS A
JOIN sys.indexes AS B ON A.table_object_id = B.[object_id] AND A.index_name = B.[name] COLLATE DATABASE_DEFAULT
JOIN sys.tables AS C ON C.[object_id] = B.[object_id]
JOIN sys.indexes AS D ON B.[object_id] = D.[object_id] AND B.index_id = D.index_id
JOIN
(
SELECT
*
FROM
(
SELECT
X3.[object_id],
X3.index_id,
STUFF((
SELECT
', [' + X2.[name] + ']' + CASE WHEN MAX(CONVERT(INT, X1.is_descending_key)) = 1 THEN ' DESC' ELSE '' END
FROM
sys.index_columns AS X1
JOIN sys.columns AS X2 ON X2.[object_id] = X1.[object_id] AND X2.column_id = X1.column_id AND X1.is_included_column = 0
WHERE
X1.[object_id] = X3.[object_id]
AND X1.index_id = X3.index_id
GROUP BY
X1.[object_id],
X2.[name],
X1.index_id
ORDER BY
MAX(X1.key_ordinal)
FOR XML PATH('')
), 1, 2, ''
) AS KeyColumns
FROM
sys.index_columns AS X3
GROUP BY
X3.[object_id],
X3.index_id
) AS X4
) AS E ON B.[object_id] = E.[object_id] AND B.index_id = E.index_id
JOIN sys.stats AS F ON F.[object_id] = B.[object_id] AND F.stats_id = B.index_id
JOIN sys.data_spaces AS G ON B.data_space_id = G.data_space_id
JOIN sys.filegroups AS H ON B.data_space_id = H.data_space_id
LEFT JOIN
(
SELECT
*
FROM
(
SELECT
X3.[object_id],
X3.index_id,
STUFF((
SELECT
', [' + X2.[name] + ']'
FROM
sys.index_columns AS X1
JOIN sys.columns AS X2 ON X2.[object_id] = X1.[object_id] AND X2.column_id = X1.column_id AND X1.is_included_column = 1
WHERE
X1.[object_id] = X3.[object_id]
AND X1.index_id = X3.index_id
GROUP BY
X1.[object_id],
X2.[name],
X1.index_id
FOR XML PATH('')
), 1, 2, ''
) AS IncludedColumns
FROM
sys.index_columns AS X3
GROUP BY
X3.[object_id],
X3.index_id
) AS tmp1
WHERE
IncludedColumns IS NOT NULL
) AS I ON I.[object_id] = B.[object_id] AND I.index_id = B.index_id
SELECT
@CmdAlterTable += 'ALTER TABLE [' + [schema_name] + '].[' + table_name + '] ALTER COLUMN [' + [name] + '] ' + UPPER([type_name]) + (CASE WHEN UPPER([type_name]) <> 'SYSNAME' THEN '(' + (CASE WHEN A.max_length > 0 THEN CAST(A.max_length AS VARCHAR(10)) ELSE 'MAX' END) + ')' ELSE '' END) + ' COLLATE ' + @Collation_Desejado + ' ' + (CASE WHEN A.is_sparse = 1 THEN 'SPARSE ' ELSE '' END) + (CASE WHEN A.is_nullable = 1 THEN 'NULL' ELSE 'NOT NULL' END) + ';'
FROM
#Colunas A
-------------------------------------------------------------------------
-- Executa os scripts
-------------------------------------------------------------------------
PRINT '---------- Dropando as contraints FK'
IF (NULLIF(LTRIM(RTRIM(@CmdDropFK)), '') IS NOT NULL) PRINT @CmdDropFK
IF (@Fl_Debug = 0) EXEC(@CmdDropFK)
PRINT '---------- Desativando as Check Contraints'
IF (NULLIF(LTRIM(RTRIM(@CmdDisableCK)), '') IS NOT NULL) PRINT @CmdDisableCK
IF (@Fl_Debug = 0) EXEC(@CmdDisableCK)
PRINT '---------- Dropando os índices'
IF (NULLIF(LTRIM(RTRIM(@CmdDropIndex)), '') IS NOT NULL) PRINT @CmdDropIndex
IF (@Fl_Debug = 0) EXEC(@CmdDropIndex)
PRINT '---------- Dropando os índices em constraints'
IF (NULLIF(LTRIM(RTRIM(@CmdDropIndexConstraint)), '') IS NOT NULL) PRINT @CmdDropIndexConstraint
IF (@Fl_Debug = 0) EXEC(@CmdDropIndexConstraint)
PRINT '---------- Alterando a tabela'
IF (NULLIF(LTRIM(RTRIM(@CmdAlterTable)), '') IS NOT NULL) PRINT @CmdAlterTable
IF (@Fl_Debug = 0) EXEC(@CmdAlterTable)
PRINT '---------- Reativando as constraints'
IF (NULLIF(LTRIM(RTRIM(@CmdEnableCK)), '') IS NOT NULL) PRINT @CmdEnableCK
IF (@Fl_Debug = 0) EXEC(@CmdEnableCK)
PRINT '---------- Recriando os índices'
IF (NULLIF(LTRIM(RTRIM(@CmdCreateIndex)), '') IS NOT NULL) PRINT @CmdCreateIndex
IF (@Fl_Debug = 0) EXEC(@CmdCreateIndex)
PRINT '---------- Recriando os índices em constraints'
IF (NULLIF(LTRIM(RTRIM(@CmdCreateIndexConstraint)), '') IS NOT NULL) PRINT @CmdCreateIndexConstraint
IF (@Fl_Debug = 0) EXEC(@CmdCreateIndexConstraint)
PRINT '---------- Recriando as FKs'
IF (NULLIF(LTRIM(RTRIM(@CmdCreateFK)), '') IS NOT NULL) PRINT @CmdCreateFK
IF (@Fl_Debug = 0) EXEC(@CmdCreateFK)
-------------------------------------------------------------------------
-- Executa os scripts
-------------------------------------------------------------------------
PRINT '---------- Dropando as contraints FK'
IF (NULLIF(LTRIM(RTRIM(@CmdDropFK)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdDropFK, ';')
IF (@Fl_Debug = 0) EXEC(@CmdDropFK)
PRINT '---------- Desativando as Check Contraints'
IF (NULLIF(LTRIM(RTRIM(@CmdDisableCK)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdDisableCK, ';')
IF (@Fl_Debug = 0) EXEC(@CmdDisableCK)
PRINT '---------- Dropando os índices'
IF (NULLIF(LTRIM(RTRIM(@CmdDropIndex)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdDropIndex, ';')
IF (@Fl_Debug = 0) EXEC(@CmdDropIndex)
PRINT '---------- Dropando os índices em constraints'
IF (NULLIF(LTRIM(RTRIM(@CmdDropIndexConstraint)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdDropIndexConstraint, ';')
IF (@Fl_Debug = 0) EXEC(@CmdDropIndexConstraint)
PRINT '---------- Alterando a tabela'
IF (NULLIF(LTRIM(RTRIM(@CmdAlterTable)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdAlterTable, ';')
IF (@Fl_Debug = 0) EXEC(@CmdAlterTable)
PRINT '---------- Reativando as constraints'
IF (NULLIF(LTRIM(RTRIM(@CmdEnableCK)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdEnableCK, ';')
IF (@Fl_Debug = 0) EXEC(@CmdEnableCK)
PRINT '---------- Recriando os índices'
IF (NULLIF(LTRIM(RTRIM(@CmdCreateIndex)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdCreateIndex, ';')
IF (@Fl_Debug = 0) EXEC(@CmdCreateIndex)
PRINT '---------- Recriando os índices em constraints'
IF (NULLIF(LTRIM(RTRIM(@CmdCreateIndexConstraint)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdCreateIndexConstraint, ';')
IF (@Fl_Debug = 0) EXEC(@CmdCreateIndexConstraint)
PRINT '---------- Recriando as FKs'
IF (NULLIF(LTRIM(RTRIM(@CmdCreateFK)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdCreateFK, ';')
IF (@Fl_Debug = 0) EXEC(@CmdCreateFK)
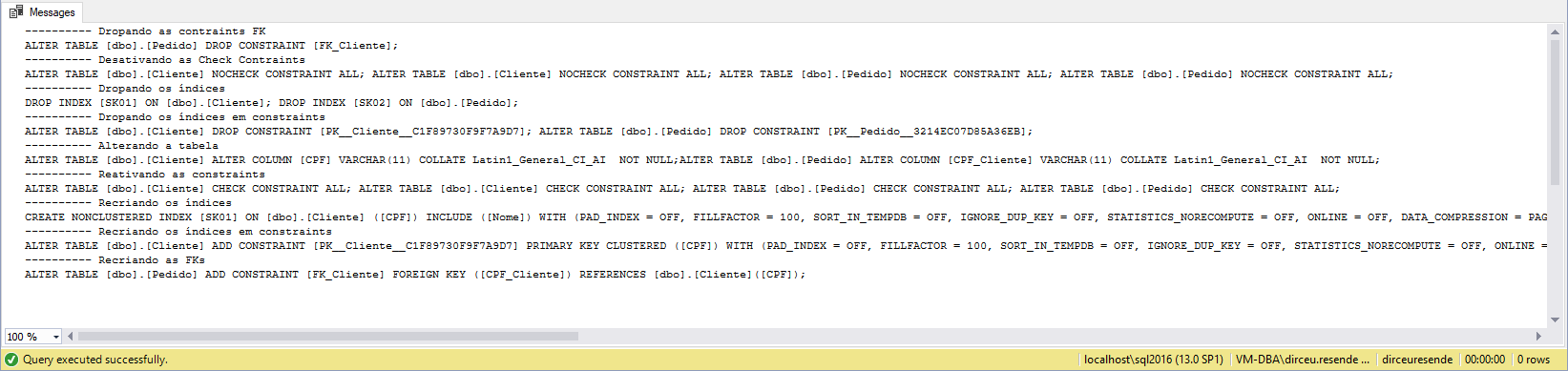
Resultado:
Espero que tenham gostado desse post e até a próxima! PS: Lembre de fazer o backup e testar BASTANTE se você planeja aplicar esse script em Produção.
Em caso de dúvidas ou problemas, deixe aqui nos comentários.


Comentários (0)
Carregando comentários...