E aí, galera!
Prontos para mais uma dica?
Introdução
Nesse artigo eu gostaria de demonstrar pra vocês, algumas formas de carregar dados de forma rápida e eficiente no banco de dados, utilizando o mínimo de log possível. Isso é especialmente útil para cenários de staging em processos de BI/Data warehouse, onde os dados devem ser carregados rapidamente e uma possível perda de dados é aceitável (pois o processo pode ser refeito em caso de falha).
O intuito desse artigo é comparar a performance das mais diversas formas de inserção de dados, como tabelas temporárias, variáveis do tipo tabela, combinações de recovery_model, tipos de compactação e as tabelas otimizadas para memória (In-Memory OLTP), visando provar o quanto esse recurso é eficiente.
Vale ressaltar que o recurso In-Memory OLTP está disponível desde o SQL Server 2014 e possui significativas melhorias no SQL Server 2016 e SQL Server 2017.
Testes utilizando soluções disk-based
Visualizar conteúdoScript base utilizado:
SET STATISTICS TIME OFF
SET NOCOUNT ON
IF (OBJECT_ID('dirceuresende.dbo.Staging_Sem_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Sem_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Sem_JOIN ( Contador INT, Nome VARCHAR(50), Idade INT, [Site] VARCHAR(200) )
GO
IF (OBJECT_ID('dirceuresende.dbo.Staging_Com_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Com_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Com_JOIN ( Contador INT, [Dt_Venda] datetime, [Vl_Venda] float(8), [Nome_Cliente] varchar(100), [Nome_Produto] varchar(100), [Ds_Forma_Pagamento] varchar(100) )
GO
DECLARE
@Contador INT = 1,
@Total INT = 100000,
@Dt_Log DATETIME,
@Qt_Duracao_1 INT,
@Qt_Duracao_2 INT
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste simples
INSERT INTO dirceuresende.dbo.Staging_Sem_JOIN ( Contador, Nome, Idade, [Site] )
VALUES (@Contador, 'Dirceu Resende', 31, 'https://dirceuresende.com/')
SET @Contador += 1
END
SET @Qt_Duracao_1 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SET @Total = 10000
SET @Contador = 1
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste com JOIN
INSERT INTO dirceuresende.dbo.Staging_Com_JOIN
SELECT @Contador, A.Dt_Venda, A.Vl_Venda, B.Ds_Nome AS Nome_Cliente, C.Ds_Nome AS Nome_Produto, D.Ds_Nome AS Ds_Forma_Pagamento
FROM dirceuresende.dbo.Fato_Venda A
JOIN dirceuresende.dbo.Dim_Cliente B ON A.Cod_Cliente = B.Codigo
JOIN dirceuresende.dbo.Dim_Produto C ON A.Cod_Produto = C.Codigo
JOIN dirceuresende.dbo.Dim_Forma_Pagamento D ON A.Cod_Forma_Pagamento = D.Codigo
SET @Contador += 1
END
SET @Qt_Duracao_2 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SELECT @Qt_Duracao_1 AS Duracao_Sem_JOIN, @Qt_Duracao_2 AS Duracao_Com_JOIN
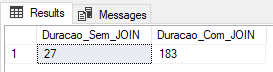
Utilizando tabela física (recovery model FULL)
Nesse teste, vou utilizar uma tabela física com o Recovery Model no FULL.
ALTER DATABASE [dirceuresende] SET RECOVERY FULL
GOResultado:
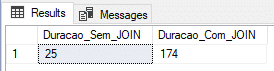
Utilizando tabela física (recovery model SIMPLE)
Nesse teste, vou utilizar uma tabela física com o Recovery Model no SIMPLE, que gera menos informações na transaction log e teoricamente, deveria entregar uma carga mais rápida.
ALTER DATABASE [dirceuresende] SET RECOVERY SIMPLE
GOResultado:
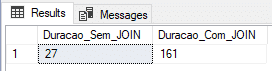
Utilizando tabela física (recovery model BULK-LOGGED)
Nesse teste, vou utilizar uma tabela física com o Recovery Model no BULK-LOGGED, que é otimizado para processos em lote e cargas de dados.
ALTER DATABASE [dirceuresende] SET RECOVERY BULK_LOGGED
GOResultado:
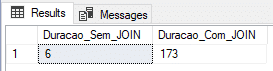
Utilizando tabela física e DELAYED_DURABILITY (recovery model BULK-LOGGED)
Nesse teste, vou utilizar uma tabela física com o Recovery Model no BULK-LOGGED, que é otimizado para processos em lote e cargas de dados e também o parâmetro DELAYED_DURABILITY = FORCED, que faz com que os eventos de log sejam gravados de força assíncrona (saiba mais sobre esse recurso acessando este link ou esse post aqui).
ALTER DATABASE [dirceuresende] SET RECOVERY BULK_LOGGED
GO
ALTER DATABASE dirceuresende SET DELAYED_DURABILITY = FORCED
GOResultado:
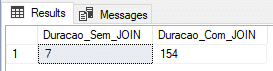
Utilizando tabela temporária (recovery model SIMPLE)
Muito utilizada para tabelas geradas dinamicamente e processos rápidos, vou realizar o teste inserindo os dados numa tabela #temporária (#Staging_Sem_JOIN e #Staging_Com_JOIN). A minha tempdb está utilizando o Recovery Model SIMPLE.
Resultado:
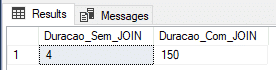
Utilizando variável do tipo tabela
Muito utilizada para tabelas geradas dinamicamente e processos rápidos, assim como a tabela #temporária, vou realizar o teste inserindo os dados em uma variável do tipo @tabela (@Staging_Sem_JOIN e @Staging_Com_JOIN).
Resultado:
In-Memory OLTP (IMO)
Visualizar conteúdoImplementando o In-Memory OLTP
Visualizar conteúdoAdicionando suporte ao In-Memory no seu database
Visando testar o quão rápido o In-Memory OLTP pode ser em comparação aos outros métodos utilizados, precisamos antes, adicionar um filegroup ao nosso database otimizado para dados em memória. Isso é um pré-requisito para utilizar o In-Memory.
Para adicionar esse filegroup “especial”, você pode utilizar a interface do SQL Server Management Studio:
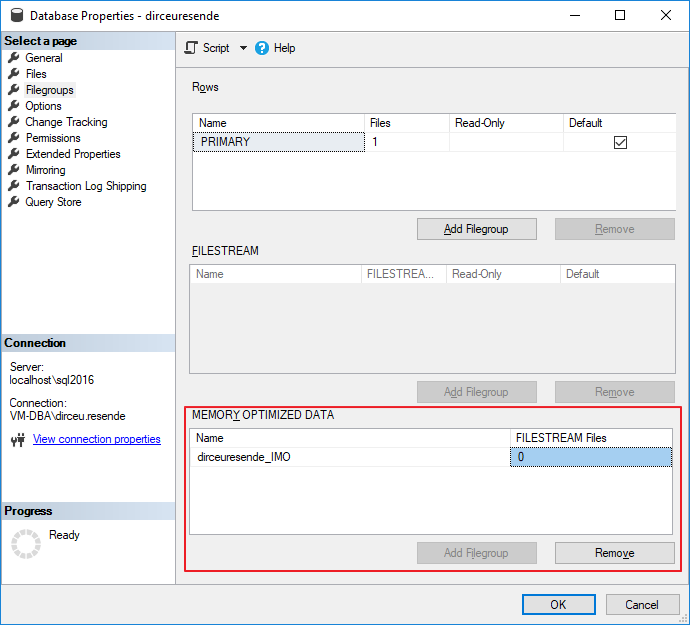
Mas na hora de adicionar um arquivo ao filegroup, a interface do SSMS (versão 17.5) não possui suporte a isso ainda, não me mostrando o filegroup de In-Memory que já havia criado, tendo que adicionar o arquivo utilizando comandos T-SQL.
Para adicionar o filegroup e também os arquivos, você pode utilizar o seguinte comando T-SQL:
USE [master]
GO
ALTER DATABASE [dirceuresende] ADD FILEGROUP [dirceuresende_IMO] CONTAINS MEMORY_OPTIMIZED_DATA
GO
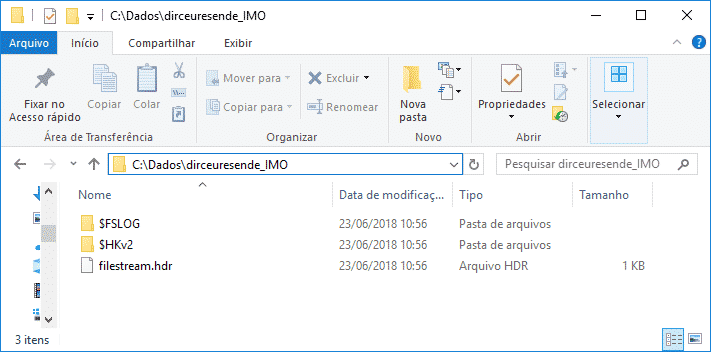
ALTER DATABASE [dirceuresende] ADD FILE ( NAME = [dirceuresende_dados_IMO], FILENAME = 'C:\Dados\dirceuresende_IMO\' ) TO FILEGROUP [dirceuresende_IMO]
GO
Reparem que no In-Memory, diferente de um filegroup comum, você não especifica a extensão do arquivo, porque, na verdade, um diretório é criado com vários arquivos hospedados nele.
IMPORTANTE: Até a versão atual (2017), não é possível remover um filegroup do tipo MEMORY_OPTIMIZED_DATA, ou seja, uma vez criado, ele só poderá ser apagado se o banco inteiro for dropado. Por isso, recomendo a criação de um novo database só para as tabelas In-Memory.
In-Memory OLTP: Durable vs Non-durable
Agora que criamos nosso filegroup e adicionamos pelo menos 1 arquivo nele, podemos começar a criar nossas tabelas In-Memory. Antes de começarmos, preciso explicar que existem 2 tipos de tabelas In-Memory:
– Durable (DURABILITY = SCHEMA_AND_DATA): Dados e estruturas persistidos no disco. Isso quer dizer que se o servidor ou serviço do SQL for reiniciado, os dados da sua tabela em memória continuarão disponíveis para consulta. Esse é o comportamento padrão das tabelas In-Memory.
– Non-durable (DURABILITY = SCHEMA_ONLY): Apenas a estrutura da tabela é persistida no disco e operações de LOG não são geradas. Isso quer dizer que as operações de escrita nesse tipo de tabelas são MUITO mais rápidas. Entretanto, se o servidor ou serviço do SQL for reiniciado, a sua tabela continuará disponível para consultas, para ela estará vazia, pois os dados ficam disponíveis apenas em memória e foram perdidos durante o crash/restart.
Restrições do In-Memory OLTP
Visualizar conteúdoTestes com tabelas In-Memory OLTP
Visualizar conteúdoSET STATISTICS TIME OFF
SET NOCOUNT ON
IF (OBJECT_ID('dirceuresende.dbo.Staging_Sem_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Sem_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Sem_JOIN
(
Contador INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH(BUCKET_COUNT = 100000),
Nome VARCHAR(50),
Idade INT,
[Site] VARCHAR(200)
)
WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
IF (OBJECT_ID('dirceuresende.dbo.Staging_Com_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Com_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Com_JOIN
(
Contador INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH(BUCKET_COUNT = 10000000),
[Dt_Venda] DATETIME,
[Vl_Venda] FLOAT(8),
[Nome_Cliente] VARCHAR(100),
[Nome_Produto] VARCHAR(100),
[Ds_Forma_Pagamento] VARCHAR(100)
)
WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
DECLARE
@Contador INT = 1,
@Total INT = 100000,
@Dt_Log DATETIME,
@Qt_Duracao_1 INT,
@Qt_Duracao_2 INT
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste simples
INSERT INTO dirceuresende.dbo.Staging_Sem_JOIN ( Contador, Nome, Idade, [Site] )
VALUES (@Contador, 'Dirceu Resende', 31, 'https://dirceuresende.com/')
SET @Contador += 1
END
SET @Qt_Duracao_1 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SET @Total = 10000
SET @Contador = 1
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste com JOIN
INSERT INTO dirceuresende.dbo.Staging_Com_JOIN
SELECT A.Dt_Venda, A.Vl_Venda, B.Ds_Nome AS Nome_Cliente, C.Ds_Nome AS Nome_Produto, D.Ds_Nome AS Ds_Forma_Pagamento
FROM dirceuresende.dbo.Fato_Venda A
JOIN dirceuresende.dbo.Dim_Cliente B ON A.Cod_Cliente = B.Codigo
JOIN dirceuresende.dbo.Dim_Produto C ON A.Cod_Produto = C.Codigo
JOIN dirceuresende.dbo.Dim_Forma_Pagamento D ON A.Cod_Forma_Pagamento = D.Codigo
SET @Contador += 1
END
SET @Qt_Duracao_2 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SELECT @Qt_Duracao_1 AS Duracao_Sem_JOIN, @Qt_Duracao_2 AS Duracao_Com_JOIN
Notem que especifiquei o BUCKET_COUNT da Primary Key HASH do mesmo tamanho da quantidade de registros. Essa informação é importante para avaliar a quantidade de memória necessária para alocar uma tabela, conforme podemos aprender mais no artigo desse link aqui. O número ideal é igual a quantidade registros distintos da tabela original para processos temporários de carga (ETL) ou de 2x a 5x esse número para tabelas transacionais.
In-Memory OLTP: Durable
Nesse exemplo, vou criar as tabelas utilizando o tipo Durable (DURABILITY = SCHEMA_AND_DATA) e veremos se o ganho de performance na inserção dos dados é tão eficiente assim.
Resultado:
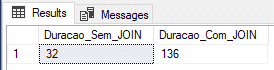
No print acima, ficou demonstrado que o tempo medido para o insert sem join não foi muito satisfatório, ficando bem atrás do insert em tabela @variavel e tabela #temporaria, enquanto o tempo com os JOINS foi o melhor medido até agora, mas não foi nada surpreendente.
In-Memory OLTP: Non-Durable
Nesse exemplo, vou criar as tabelas utilizando o tipo Non-Durable (DURABILITY = SCHEMA_ONLY) e veremos se o ganho de performance na inserção dos dados é tão eficiente assim.
Resultado:
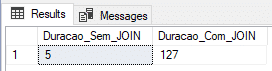
Aqui conseguimos encontrar um resultado bem interessante, com o menor tempo com o JOIN e o 2º menor tempo sem o JOIN.
In-Memory OLTP: Non-Durable (tudo em memória)
Por fim, vou tentar diminuir o tempo da carga com os joins, criando todas as tabelas envolvidas para memória e testar se isso vai nos dar um bom ganho de performance.
Script utilizado:
SET STATISTICS TIME OFF
SET NOCOUNT ON
--------------------------------------------------------
-- Migrando tabelas em disco para In-Memory OLTP
--------------------------------------------------------
SET IDENTITY_INSERT dbo.Dim_Cliente_IMO OFF
GO
SET IDENTITY_INSERT dbo.Dim_Produto_IMO OFF
GO
SET IDENTITY_INSERT dbo.Dim_Forma_Pagamento_IMO OFF
GO
IF (OBJECT_ID('dirceuresende.dbo.Fato_Venda_IMO') IS NOT NULL) DROP TABLE dirceuresende.dbo.Fato_Venda_IMO
CREATE TABLE [dbo].[Fato_Venda_IMO]
(
[Codigo] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED,
[Cod_Cliente] [int] NULL,
[Cod_Produto] [int] NULL,
[Cod_Forma_Pagamento] [int] NULL,
[Dt_Venda] [datetime] NULL,
[Vl_Venda] [float] NULL
) WITH( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
INSERT INTO dbo.Fato_Venda_IMO
SELECT * FROM dbo.Fato_Venda
------------------------------------------------------
IF (OBJECT_ID('dirceuresende.dbo.Dim_Cliente_IMO') IS NOT NULL) DROP TABLE dirceuresende.dbo.Dim_Cliente_IMO
CREATE TABLE [dbo].[Dim_Cliente_IMO]
(
[Codigo] [int] NOT NULL IDENTITY(1, 1) PRIMARY KEY NONCLUSTERED,
[Ds_Nome] [varchar] (100) COLLATE Latin1_General_CI_AI NULL,
[Dt_Nascimento] [datetime] NULL,
[Sg_Sexo] [varchar] (20) COLLATE Latin1_General_CI_AI NULL,
[Sg_UF] [varchar] (2) COLLATE Latin1_General_CI_AI NULL
) WITH( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
SET IDENTITY_INSERT dbo.Dim_Cliente_IMO ON
INSERT INTO dbo.Dim_Cliente_IMO
(
Codigo,
Ds_Nome,
Dt_Nascimento,
Sg_Sexo,
Sg_UF
)
SELECT * FROM dbo.Dim_Cliente
SET IDENTITY_INSERT dbo.Dim_Cliente_IMO OFF
------------------------------------------------------
IF (OBJECT_ID('dirceuresende.dbo.Dim_Produto_IMO') IS NOT NULL) DROP TABLE dirceuresende.dbo.Dim_Produto_IMO
CREATE TABLE [dbo].[Dim_Produto_IMO]
(
[Codigo] [int] NOT NULL IDENTITY(1, 1) PRIMARY KEY NONCLUSTERED,
[Ds_Nome] [varchar] (100) COLLATE Latin1_General_CI_AI NULL,
[Peso] [int] NULL,
[Categoria] [varchar] (50) COLLATE Latin1_General_CI_AI NULL,
[Preco] [float] NULL
) WITH( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
SET IDENTITY_INSERT dbo.Dim_Produto_IMO ON
INSERT INTO dbo.Dim_Produto_IMO
(
Codigo,
Ds_Nome,
Peso,
Categoria,
Preco
)
SELECT * FROM dbo.Dim_Produto
SET IDENTITY_INSERT dbo.Dim_Produto_IMO OFF
------------------------------------------------------
IF (OBJECT_ID('dirceuresende.dbo.Dim_Forma_Pagamento_IMO') IS NOT NULL) DROP TABLE dirceuresende.dbo.Dim_Forma_Pagamento_IMO
CREATE TABLE [dbo].[Dim_Forma_Pagamento_IMO]
(
[Codigo] [int] NOT NULL IDENTITY(1, 1) PRIMARY KEY NONCLUSTERED,
[Ds_Nome] [varchar] (100) COLLATE Latin1_General_CI_AI NULL
) WITH( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
SET IDENTITY_INSERT dbo.Dim_Forma_Pagamento_IMO ON
INSERT INTO dbo.Dim_Forma_Pagamento_IMO
(
Codigo,
Ds_Nome
)
SELECT * FROM dbo.Dim_Forma_Pagamento
SET IDENTITY_INSERT dbo.Dim_Forma_Pagamento_IMO OFF
--------------------------------------------------------
-- Inicitando os testes
--------------------------------------------------------
IF (OBJECT_ID('dirceuresende.dbo.Staging_Sem_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Sem_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Sem_JOIN
(
Contador INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH(BUCKET_COUNT = 100000),
Nome VARCHAR(50),
Idade INT,
[Site] VARCHAR(200)
)
WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
IF (OBJECT_ID('dirceuresende.dbo.Staging_Com_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Com_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Com_JOIN
(
Contador INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH(BUCKET_COUNT = 10000000),
[Dt_Venda] DATETIME,
[Vl_Venda] FLOAT(8),
[Nome_Cliente] VARCHAR(100),
[Nome_Produto] VARCHAR(100),
[Ds_Forma_Pagamento] VARCHAR(100)
)
WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
DECLARE
@Contador INT = 1,
@Total INT = 100000,
@Dt_Log DATETIME,
@Qt_Duracao_1 INT,
@Qt_Duracao_2 INT
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste simples
INSERT INTO dirceuresende.dbo.Staging_Sem_JOIN ( Contador, Nome, Idade, [Site] )
VALUES (@Contador, 'Dirceu Resende', 31, 'https://dirceuresende.com/')
SET @Contador += 1
END
SET @Qt_Duracao_1 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SET @Total = 10000
SET @Contador = 1
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste com JOIN
INSERT INTO dirceuresende.dbo.Staging_Com_JOIN
SELECT A.Dt_Venda, A.Vl_Venda, B.Ds_Nome AS Nome_Cliente, C.Ds_Nome AS Nome_Produto, D.Ds_Nome AS Ds_Forma_Pagamento
FROM dirceuresende.dbo.Fato_Venda_IMO A
JOIN dirceuresende.dbo.Dim_Cliente_IMO B ON A.Cod_Cliente = B.Codigo
JOIN dirceuresende.dbo.Dim_Produto_IMO C ON A.Cod_Produto = C.Codigo
JOIN dirceuresende.dbo.Dim_Forma_Pagamento_IMO D ON A.Cod_Forma_Pagamento = D.Codigo
SET @Contador += 1
END
SET @Qt_Duracao_2 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SELECT @Qt_Duracao_1 AS Duracao_Sem_JOIN, @Qt_Duracao_2 AS Duracao_Com_JOIN
Resultado:
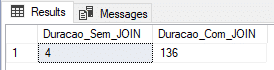
Conclusão
Nos testes acima, ficou claro que, para esse cenário, a In-Memory OLTP acaba sendo a melhor solução, tanto para o exemplo mais simples, somente inserindo os dados, quanto inserindo dados com joins.
Resumo dos testes:
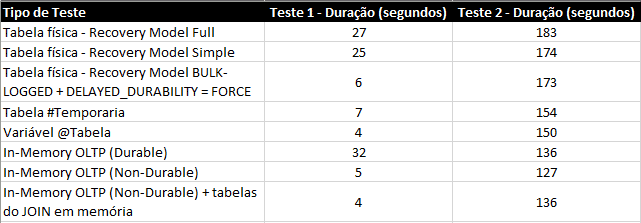
* Teste 1 = Apenas INSERT / Teste 2 = INSERT com JOINS
Se compararmos os resultados com as tabelas físicas, o resultado é bem expressivo e um grande incentivo para a sua utilização em cenários de BI, até porque, nos exemplos apresentados, as tabelas eram de apenas 100k registros numa VM com 4 cores e 8GB de RAM.
A tendência é que quanto melhor o hardware e maior o volume de dados, maior será a diferença de performance entre as tabelas físicas e tabelas em memória. Entretanto, o resultado não foi tão expressivo quando se comparado à variável do tipo tabela, por exemplo, o que até faz sentido, pois as 2 são armazenadas completamente na memória.
É claro que uma tabela In-Memory possui várias vantagens sobre a variável do tipo tabela, especialmente a vida útil, já que a variável do tipo tabela só está disponível durante a execução do batch e a tabela In-Memory fica disponível enquanto o serviço do SQL Server continuar ativo.
Como não fiquei convencido com os resultados dos testes, resolvi aumentar o volume dos dados. Ao invés de 100k, que tal inserir lotes de 20 registros, totalizando 1 milhão de registros inseridos por teste e repetindo mais 2x para cada forma de avaliação?
Vamos aos resultados:
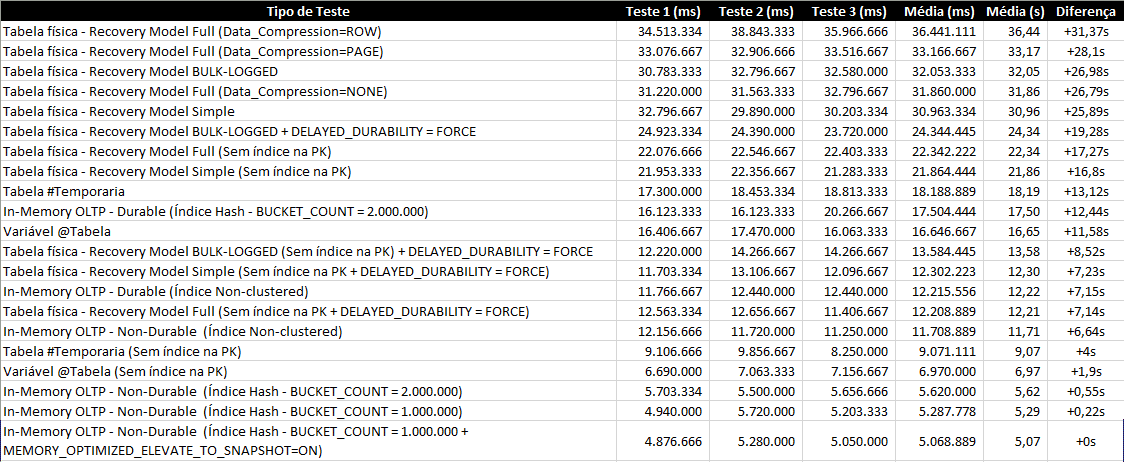
Nesse artigo, eu demonstrei apenas o seu potencial para escrita, mas o In-Memory OLTP possui uma performance muito boa para leitura também, especialmente se a tabela é muito acessada.
Espero que vocês tenham gostado desse post. Se você não conhecia o In-Memory OLTP, espero ter demonstrado um pouco do potencial dessa excelente feature do SQL Server.
Um abraço e até a próxima!

Comentários (0)
Carregando comentários...