
Fala pessoal!
Nesse artigo, quero explicar a vocês exatamente o que significa a mensagem “String or binary data would be truncated”, como podemos identificar qual a string que está causando o erro, como ocultar essa mensagem de erro (se você quiser), o que a mudança na sys.messages impactou nesse tema a partir do SQL Server 2016+ e muito mais!
Então se você tem dificuldades de identificar e corrigir ocorrências dessa mensagem de erro, hoje será a última vez que isso ainda será um problema pra você.
O que é “String or binary data would be truncated”
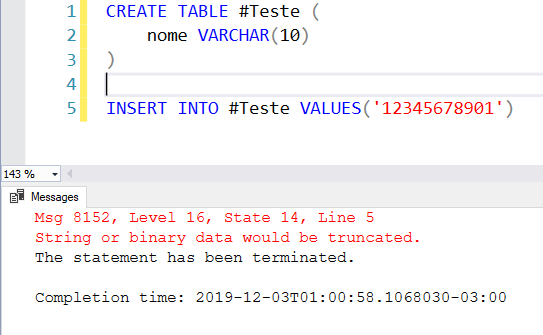
Um dos erros mais comuns do SQL Server, a mensagem “String or binary data would be truncated” ocorre quando um valor está tentando ser inserido ou atualizado em uma tabela e ele é maior que o tamanho máximo do campo.
Exemplo 1 – Tamanho máximo do campo com 10 caracteres, string com 10:
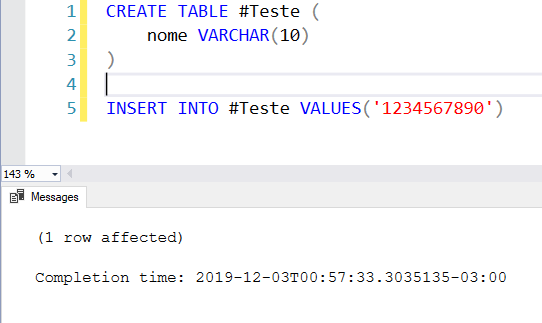
Exemplo 2 – Tamanho máximo do campo com 10 caracteres, string com 11:
Exemplo 3 – Difícil identificar o erro
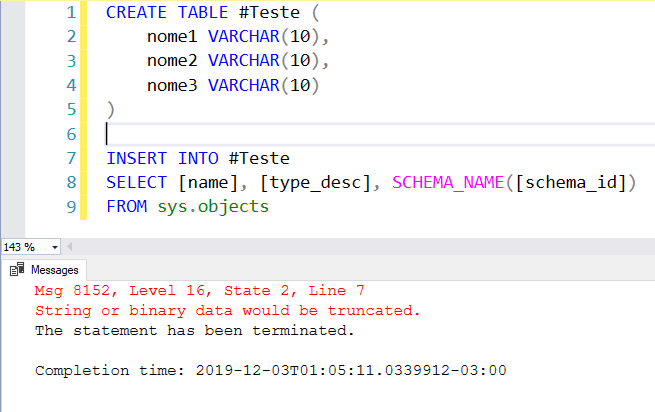
Reparem no exemplo 3. Não estou mais inserindo um valor fixo e sim de uma outra tabela. Esse tipo de situação pode parecer simples num cenário como o dos exemplos 1 e 2, mas quando você está inserindo vários registros, ainda mais levando dados de várias colunas, é difícil identificar qual registro e de qual coluna que está causando essa mensagem de erro e essa tarefa pode acabar gastando mais tempo do que você gostaria.
Como ignorar o truncamento de strings
Caso você queira ignorar o truncamento de strings em um determinado momento ou operação, você tem a opção de fazer isso no SQL Server, conforme já havia demonstrado no artigo SQL Server – Porque NÃO utilizar SET ANSI_WARNINGS OFF. Eu não recomendo utilizar essa técnica de forma alguma, pois é uma solução que está apenas mascarando o problema e não corrigindo, mas eu gostaria de mostrar que isso existe e que é possível fazê-lo.
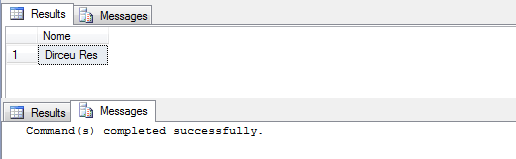
Quando você utiliza o comando SET ANSI_WARNINGS OFF, você faz com que o motor do SQL Server não gere mais esse erro na execução, fazendo com que o seu texto de 14 caracteres seja truncado e armazenado na coluna de 10 caracteres. Os caracteres excedentes serão silenciosamente descartados, ignorando e mascarando um problema na gravação dos dados do seu sistema, sem que ninguém fique sabendo.
Exemplo:
SET NOCOUNT ON
SET ANSI_WARNINGS OFF
IF ((@@OPTIONS & 8) > 0) PRINT 'SET ANSI_WARNINGS is ON'
IF (OBJECT_ID('tempdb..#Teste') IS NOT NULL) DROP TABLE #Teste
CREATE TABLE #Teste ( Nome VARCHAR(10) )
INSERT INTO #Teste
VALUES ('Dirceu Resende') -- 14 caracteres
SELECT * FROM #Teste
Retorno com SET ANSI_WARNINGS ON (Padrão):

Retorno com SET ANSI_WARNINGS OFF:
String or binary data would be truncated no SQL Server 2019
O SQL Server 2019 foi lançado no dia 04 de novembro de 2019, durante o Microsoft Ignite, e com ele, uma gama enorme de novos recursos foram lançados oficialmente.
Um desses novos recursos, são as novas mensagens disponíveis na sys.messages, que eu já havia compartilhado com vocês no meu artigo SQL Server 2019 – Lista de novidades e novos recursos desde o final de agosto de 2018:

Com essa mudança, agora ficou muito mais fácil identificar exatamente onde está ocorrendo o truncamento dos valores:
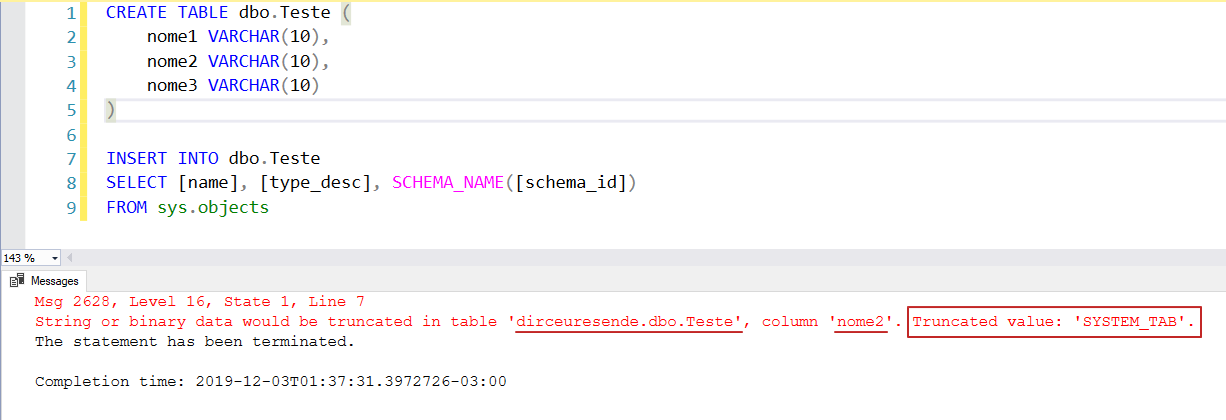
Ou seja, esse novo comportamento só funcionará automaticamente no SQL Server 2019, se o banco de dados da conexão estiver no modo de compatibilidade 150 em diante.
O que mudou a partir do SQL Server 2016+
Com as alterações necessárias para essa implementação no SQL Server 2019, a Microsoft acabou liberando essa nova mensagem também nas versões 2016 (a partir do SP2 Cumulative Update 6) e 2017 (A partir do Cumulative Update 12). E para conseguir utilizar esse nova mensagem, podemos utilizar 2 formas diferentes:
Forma 1: Utilizando parâmetro de inicialização -T460
A primeira forma e mais prática, é habilitando a traceflag 460 em toda a instância utilizando o parâmetro de inicialização -T460 no serviço do SQL Server:
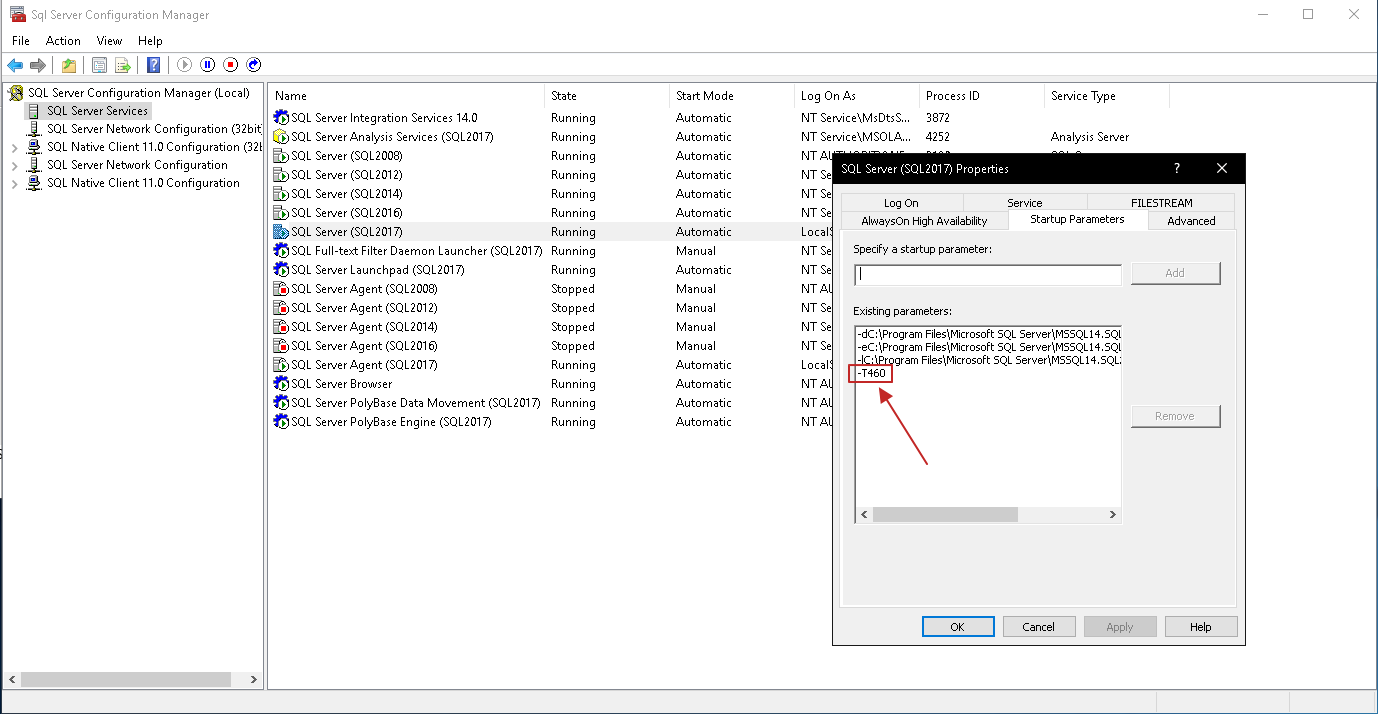
Uma vez adicionado, será necessário reiniciar o serviço e a partir de então, a nova mensagem já estará funcionando por padrão, sem precisar fazer nenhuma alteração em query:
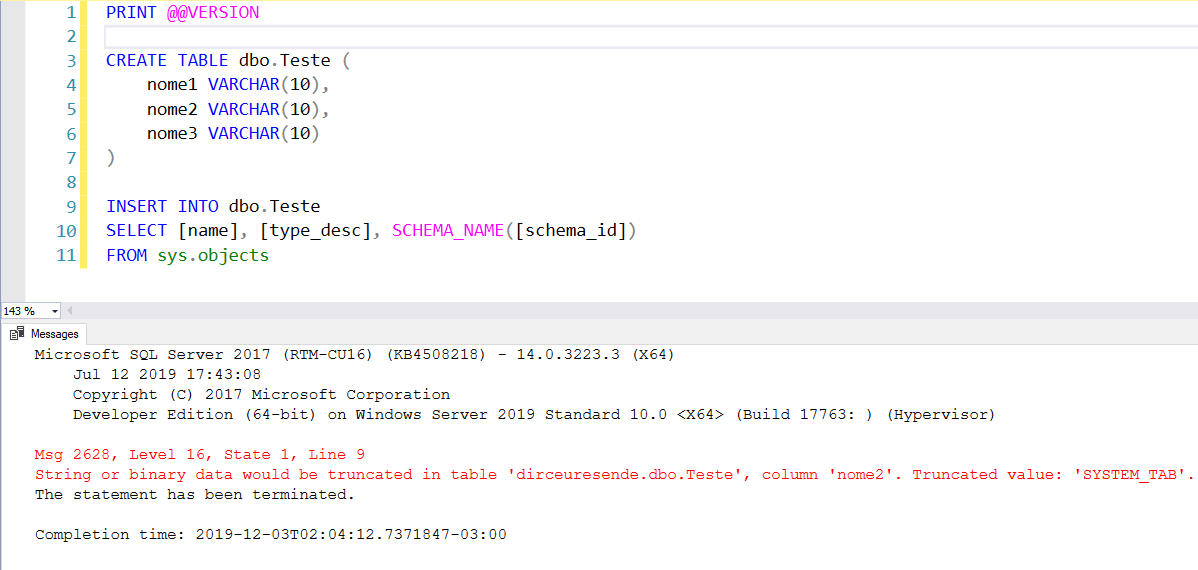
Forma 2: Utilizando traceflag 460
Uma forma que não exige reiniciar o serviço do SQL Server e também não exige alterar código, é utilizando o comando DBCC TRACEON, que permite ativar essa traceflag a nível de sessão e a nível de instância (global):
Nível de sessão (só afeta a sua sessão):
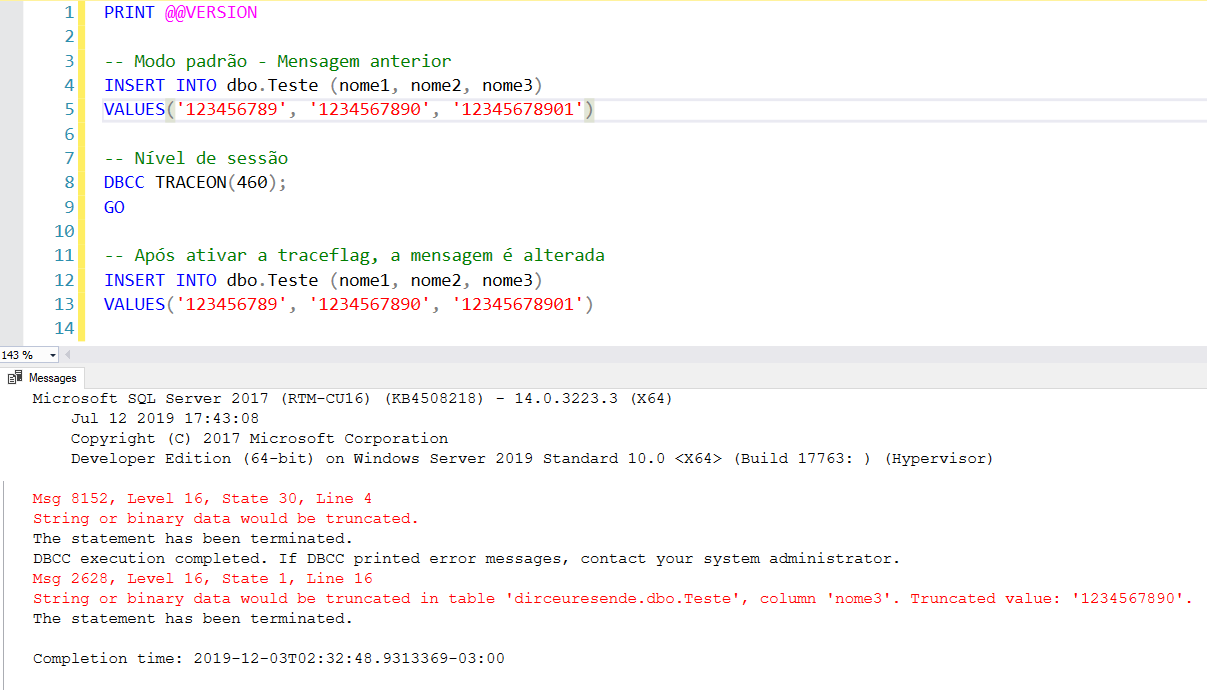
Nível de instância (global – afeta todas as sessões):
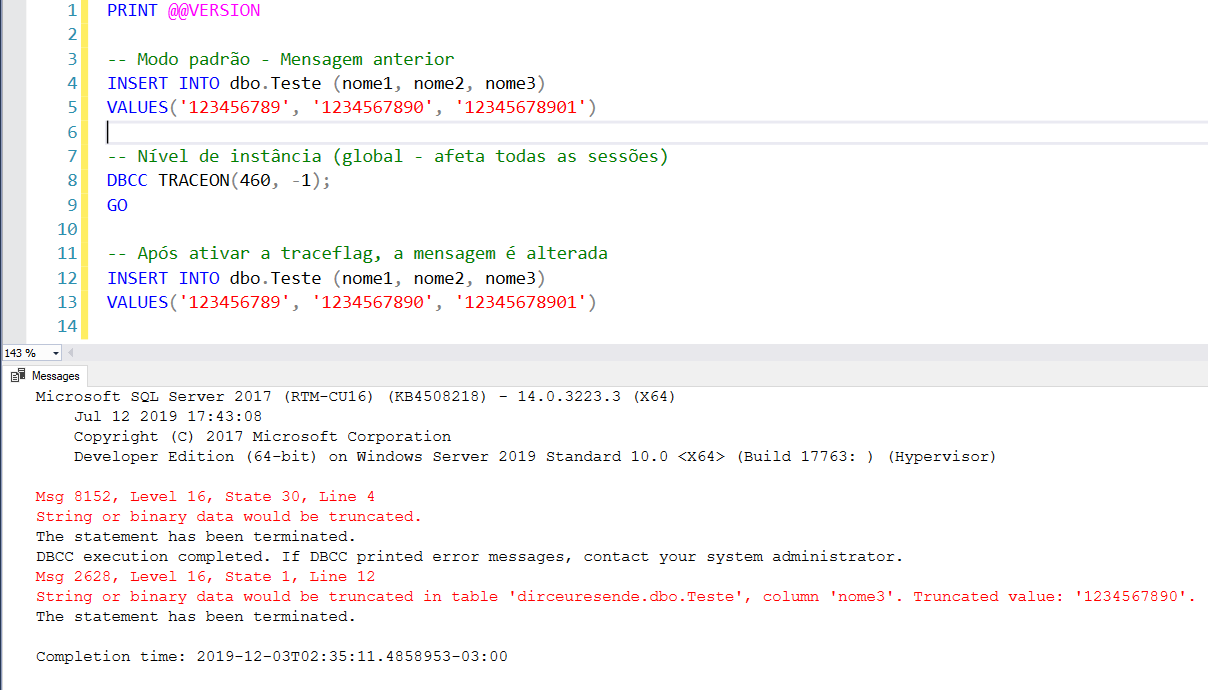
Script utilizado:
PRINT @@VERSION
CREATE TABLE dbo.Teste (
nome1 VARCHAR(10),
nome2 VARCHAR(10),
nome3 VARCHAR(10)
)
-- Modo padrão - Mensagem anterior
INSERT INTO dbo.Teste (nome1, nome2, nome3)
VALUES('123456789', '1234567890', '12345678901')
-- Nível de instância (global - afeta todas as sessões)
DBCC TRACEON(460, -1);
GO
-- Nível de sessão (afeta apenas a sua sessão)
DBCC TRACEON(460);
GO
-- Após ativar a traceflag, a mensagem é alterada
INSERT INTO dbo.Teste (nome1, nome2, nome3)
VALUES('123456789', '1234567890', '12345678901')Identificando truncamento de strings antes do SQL Server 2016
Caso você esteja utilizando uma versão anterior ao 2016 e tenha essa dificuldade em identificar quais os valores que estão estourando o limite de alguma coluna, vou compartilhar um script simples, que consegue identificar esse tipo de erro mesmo nas versões antigas do SQL Server, criando uma tabela “clone” da original, com o tamanho das colunas definido para o máximo, inserindo os dados nessa nova tabela e comparando o tamanho utilizado pelo taamnho das colunas na tabela original.
Exemplo de situação onde o script pode ser utilizado:
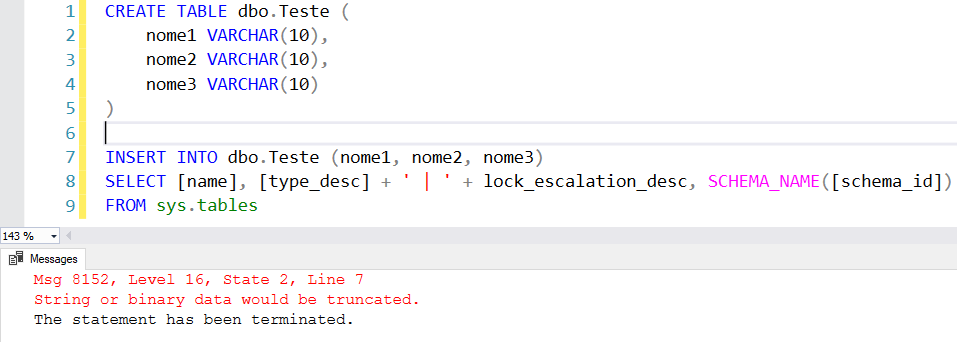
Tentei executar o meu comando de INSERT e ele deu erro em algum valor, de alguma coluna, que eu não sei qual é. Agora é o momento em que você pensa o trabalho que terá para identificar isso, especialmente se tiver umas 100 colunas ao invés de só essas 3 do exemplo.. Ter que inserir os dados numa tabela “clone” e ficar consultando e comparando o maior tamanho de cada coluna… Parece trabalhoso..
Para facilitar esse trabalho de identificação das colunas, vou compartilhar com vocês o script abaixo, que faz essa identificação para você. Lembre-se de alterar o nome da tabela origem e do script de INSERT/UPDATE na tabela clonada com o seu script original.
DECLARE @Nome_Tabela VARCHAR(255) = 'Teste'
-- Crio uma tabela com a mesma estrutura
IF (OBJECT_ID('tempdb..#Tabela_Clonada') IS NOT NULL) DROP TABLE #Tabela_Clonada
SELECT *
INTO
#Tabela_Clonada
FROM
dbo.Teste -- Tabela original (LEMBRE-SE DE ALTERAR AQUI TAMBÉM)
WHERE
1=2 -- Não quero copiar os dados
-- Agora, vou alterar todas as colunas varchar/char/nvarchar/nchar para varchar(max)
DECLARE @Query VARCHAR(MAX) = ''
SELECT
@Query += 'ALTER TABLE #Tabela_Clonada ALTER COLUMN [' + B.[name] + '] ' + UPPER(C.[name]) + '(MAX); '
FROM
sys.tables A
JOIN sys.columns B ON B.[object_id] = A.[object_id]
JOIN sys.types C ON B.system_type_id = C.system_type_id
WHERE
A.[name] = @Nome_Tabela
AND B.system_type_id IN (167, 175, 231, 239) -- varchar/char/nvarchar/nchar
AND B.max_length > 0
EXEC(@Query)
------------------------------------------------------------------------------------------------------------------
-- Faço a inserção dos dados que estão apresentando erro na tabela temporária (LEMBRE-SE DE ALTERAR AQUI TAMBÉM)
------------------------------------------------------------------------------------------------------------------
INSERT INTO #Tabela_Clonada
-- Alterar esse SELECT aqui pelo seu
SELECT [name], [type_desc] + ' | ' + lock_escalation_desc, SCHEMA_NAME([schema_id])
FROM sys.tables
-- Crio uma tabela temporária com o tamanho máximo de caracteres de cada coluna
SET @Query = ''
SELECT
@Query = @Query + 'SELECT ' + QUOTENAME(A.[name], '''') + ' AS coluna, ' + QUOTENAME(B.[name], '''') + ' AS tipo, MAX(DATALENGTH(' + QUOTENAME(A.[name]) + ')) AS tamanho FROM #Tabela_Clonada UNION '
FROM
tempdb.sys.columns A
JOIN sys.types B on B.system_type_id = A.system_type_id and B.[name] <> 'sysname'
WHERE
A.[object_id] = OBJECT_ID('tempdb..#Tabela_Clonada')
AND B.system_type_id IN (167, 175, 231, 239) -- varchar/char/nvarchar/nchar
SET @Query = LEFT(@Query, LEN(@Query)-6)
IF (OBJECT_ID('tempdb..#Tamanho_Maximo_Coluna') IS NOT NULL) DROP TABLE #Tamanho_Maximo_Coluna
CREATE TABLE #Tamanho_Maximo_Coluna (
coluna VARCHAR(255),
tipo VARCHAR(255),
tamanho INT
)
INSERT INTO #Tamanho_Maximo_Coluna
EXEC(@Query)
-- E por fim, faço a comparação dos dados de uma tabela pela outra
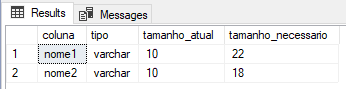
SELECT
B.[name] AS coluna,
C.[name] AS tipo,
B.max_length AS tamanho_atual,
D.tamanho AS tamanho_necessario
FROM
sys.tables A
JOIN sys.columns B ON B.[object_id] = A.[object_id]
JOIN sys.types C ON B.system_type_id = C.system_type_id
JOIN #Tamanho_Maximo_Coluna D ON B.[name] = D.coluna
WHERE
A.[name] = @Nome_Tabela
AND B.system_type_id IN (167, 175, 231, 239) -- varchar/char/nvarchar/nchar
AND B.max_length < D.tamanho
Com a execução desse script, teremos o retorno exato de quais colunas estão pequenas demais para os dados que estão recebendo e qual o tamanho ideal para conseguir armazenar esses dados.
Espero que tenham gostado desse artigo, um grande abraço e até o próximo post!
Abraços
Referências:
- SQL Server 2019 – Lista de novidades e novos recursos
- SQL Server – Porque NÃO utilizar SET ANSI_WARNINGS OFF
- Como foi a Live de Novidades do SQL Server 2019 no Canal dotNET ?
- https://www.sqlshack.com/sql-truncate-enhancement-silent-data-truncation-in-sql-server-2019/
- https://imasters.com.br/banco-de-dados/adeus-string-binary-data-truncated
- https://www.brentozar.com/archive/2019/03/how-to-fix-the-error-string-or-binary-data-would-be-truncated/

Comentários (0)
Carregando comentários...