
Fala pessoal!
Nesse artigo eu quero compartilhar com vocês uma dica que a maioria das pessoas que trabalha com Analysis Services não sabe dessa possibilidade, embora sempre quiseram ter algo assim, que é monitorar o andamento/progresso do processamento dos cubos pelo SQL Server.
Atualmente, a maioria dos profissionais de BI apenas monitora quanto tempo demorou para processar o cubo/database como um todo, mas não sabe quanto tempo demorou cada dimensão, cada fato e cada cubo dentro de um database e é isso que vou mostrá-los como fazer nesse post.
A primeira coisa que iremos fazer, é abrir o SQL Server Profiler para monitorar o processamento do cubo:
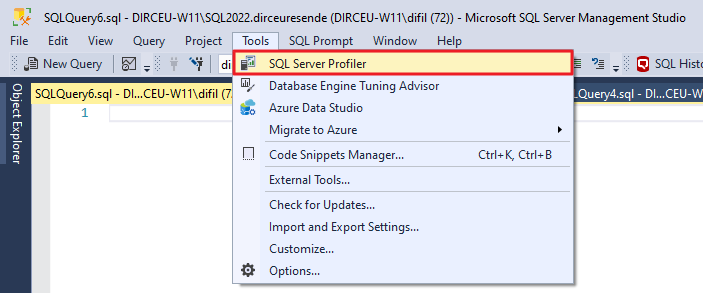
Na tela de login, lembre-se de alterar o tipo de conexão para “Analysis Services”, digitar o nome da instância que você irá conectar e configurar os dados de autenticação
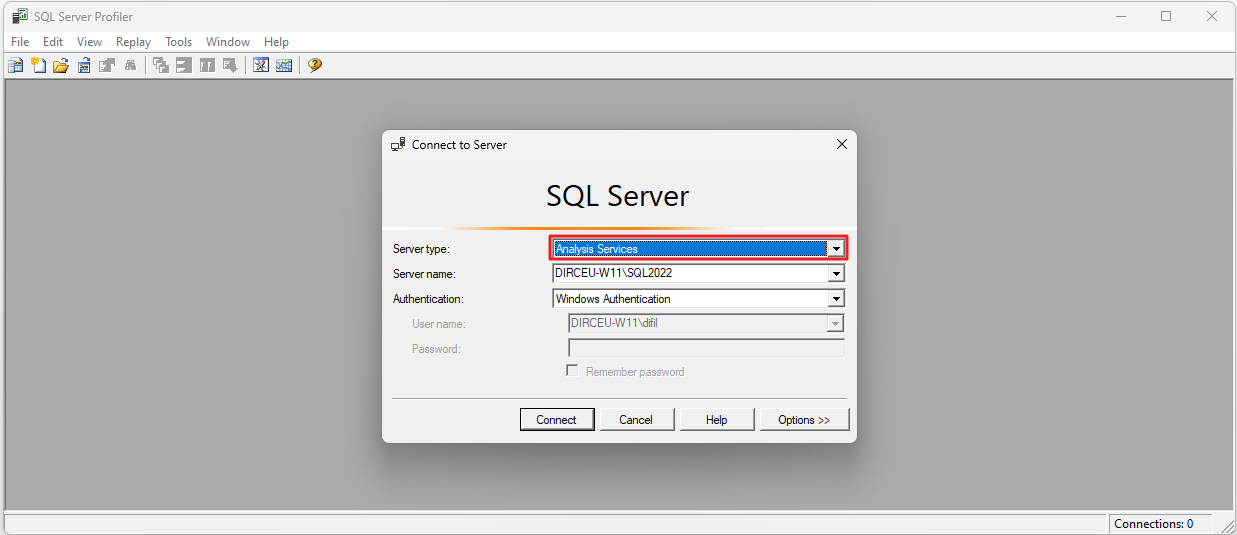
Lembre-se que o Analysis Services aceita apenas autenticação Windows (Active Directory local) ou Azure Active Directory.
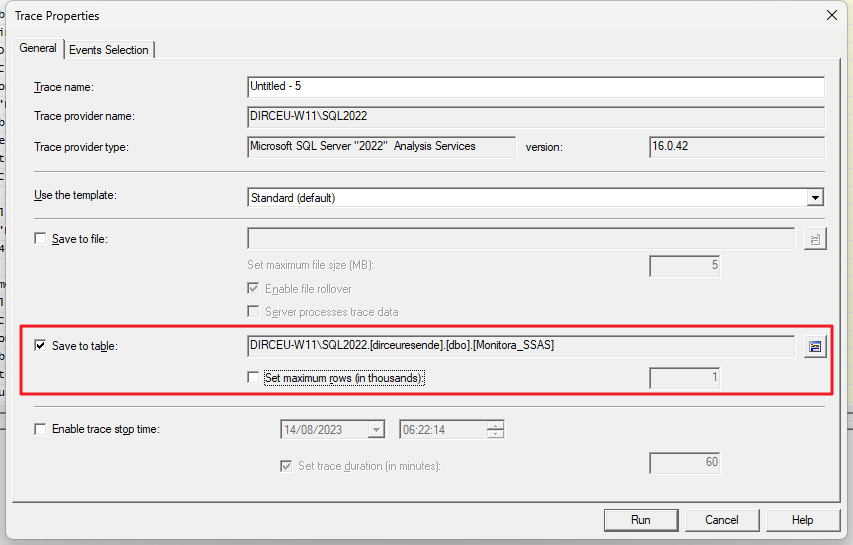
Após conectar, você poderá definir um nome pro monitoramento e onde irá armazenar (tabela do banco ou arquivo físico)
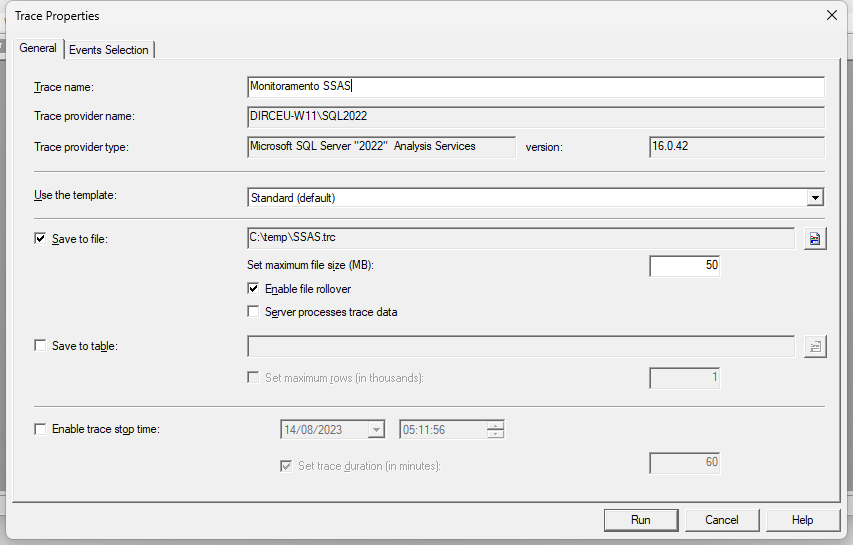
Eu geralmente salvo no disco e depois crio uma rotina de leitura via Job, apenas para não ficar gravando dados no banco o tempo todo, mas para traces vindos do Analysis Services, a função ::fn_trace_gettable, que é utilizada para ler os arquivos gerados, não funciona:
File ‘C:\temp\SSAS.trc’ is not a recognizable trace file.
Então recomendo já configurar o monitoramento para salvar os dados numa tabela de banco diretamente.
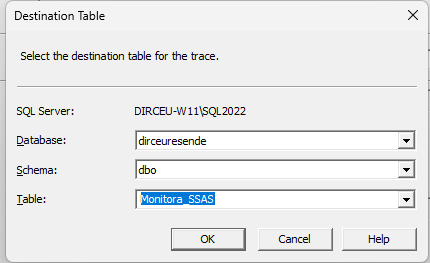
A tabela de exportação dos dados está configurada:
Agora clique na aba “Event Selection” para selecionar os eventos que irá monitorar.
Geralmente eu marco somente os eventos de “Error” e “End” das categorias abaixo:
- Command Events
- Errors and Warnings
- Progress Reports
- Queries Events
- Query Processing
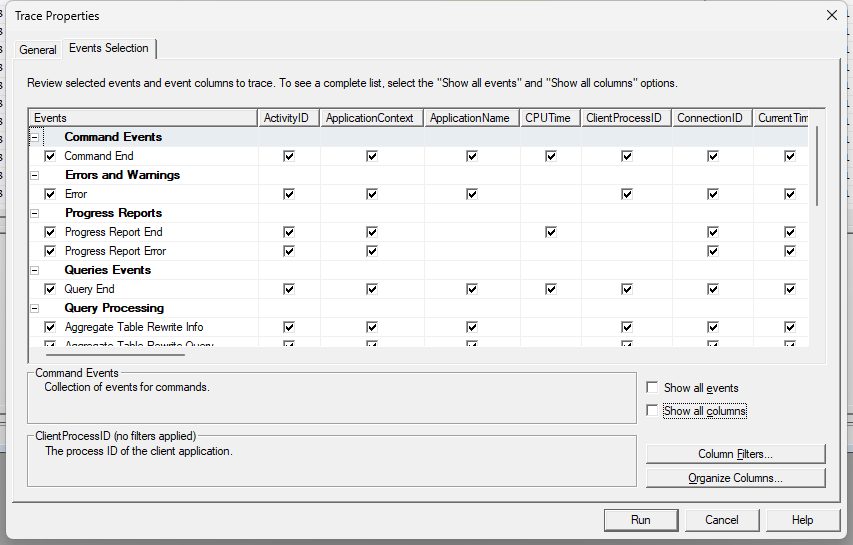
Você pode alterar esses eventos capturados conforme o nível de detalhe que quer monitorar.
Clicando no botão “Column filters”, você pode aplicar filtros como nome do usuário, nome do software, hostname, ID da sessão, etc.
No caso abaixo, vou aplicar um filtro para retornar apenas as consultas feitas pelo meu usuário. Isso é útil para evitar capturar eventos de outros usuários acessando o cubo enquanto você está processando e acabar confundindo os resultados.
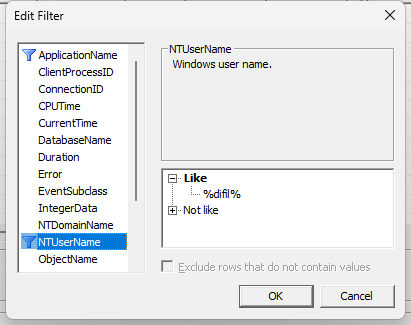
Clico em “Run” para iniciar o monitoramento e agora inicio o processamento do cubo.
Você irá ver uma tela como essa abaixo, mostrando o resultado do monitoramento.
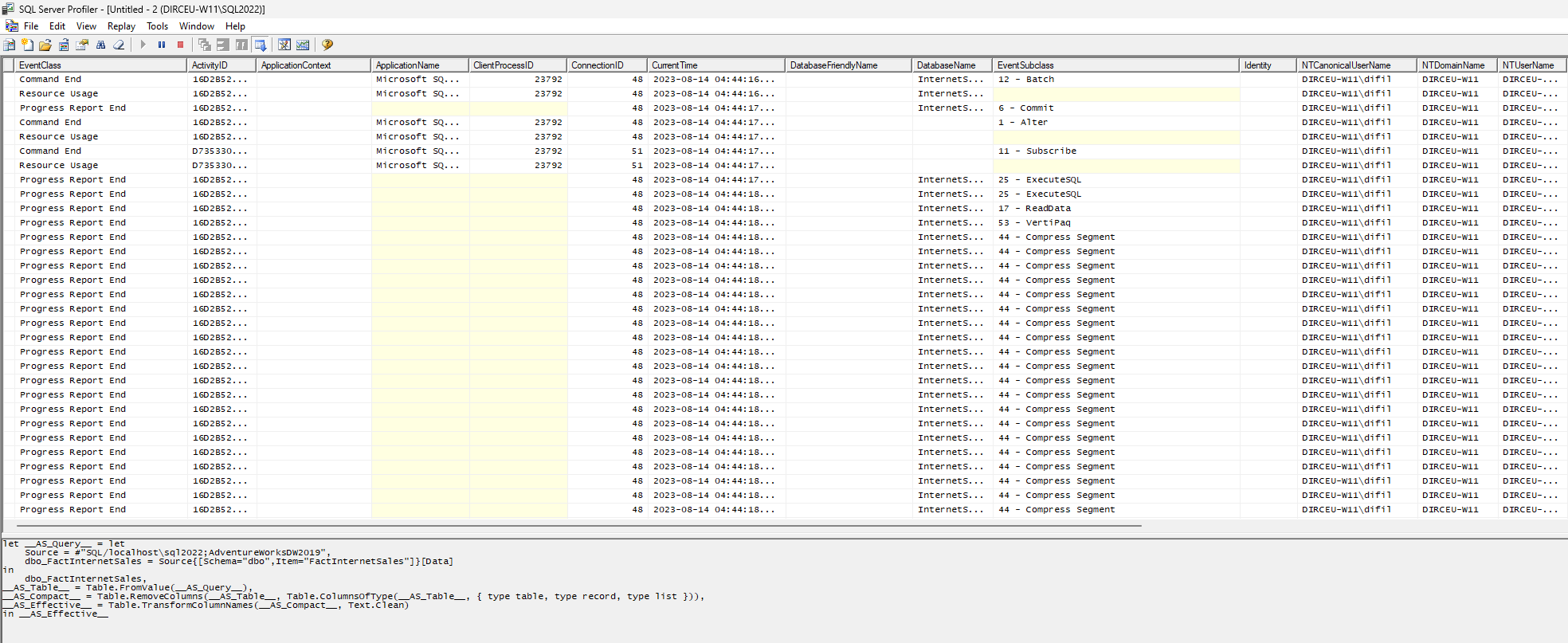
Embora seja fácil visualizar os dados, EU prefiro consultar pelo SQL Server, onde posso agrupar, somar, filtrar e transformar os dados conforme a necessidade.
Fazendo uma consulta básica na tabela criada, já conseguimos visualizar boa parte dos dados:
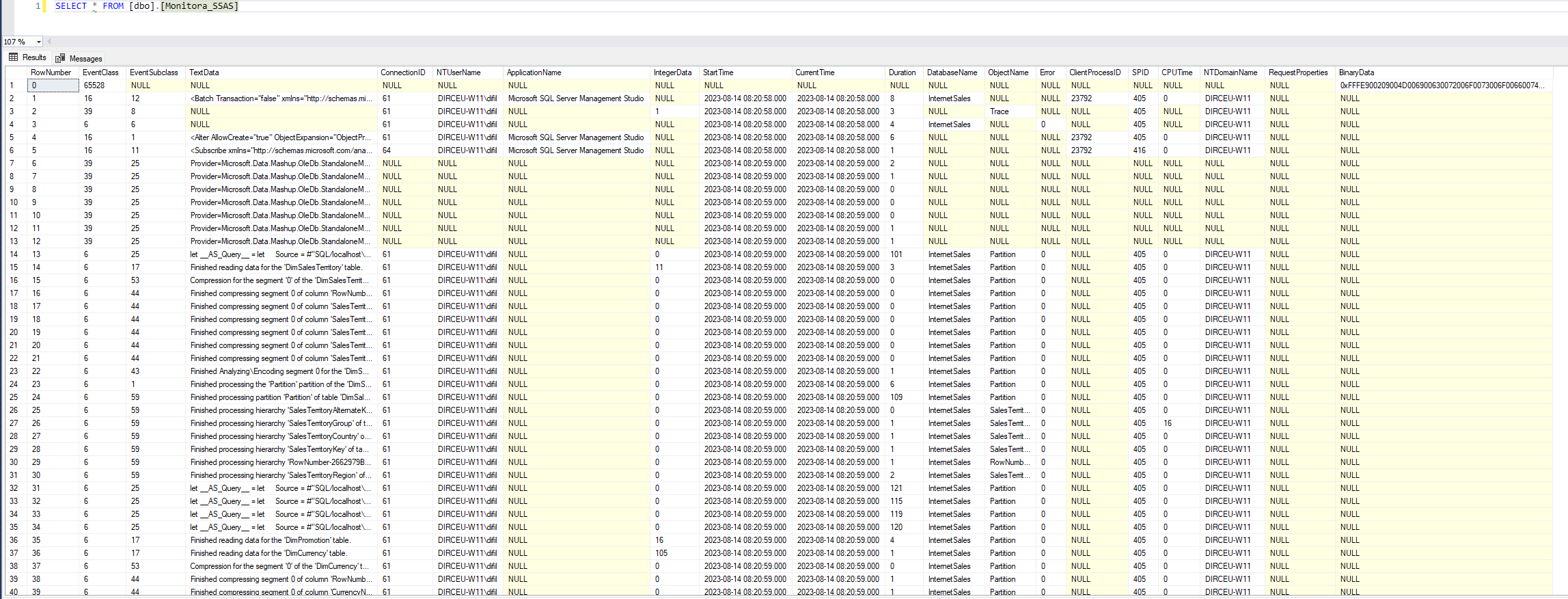
Mas agora precisamos incluir as descrições das classes e subclasses dos eventos, para facilitar o entendimento dos dados.
Primeiramente, vamos criar 2 tabelas: ProfilerEventClass e ProfilerEventSubClass, que irão armazenar as descrições dos eventos que ocorrem durante o processamento de um cubo e inserir os tipos de eventos mais comuns.
Script de criação das tabelas e inserção dos dados:
/*
*************************************************************************
ProfilerEventClass Table and Data
*************************************************************************
*/
IF EXISTS(SELECT * FROM [sys].[objects] WHERE [object_id] = OBJECT_ID(N'[dbo].[ProfilerEventClass]') AND [type] IN ( N'U' ))
DROP TABLE [dbo].[ProfilerEventClass];
CREATE TABLE [dbo].[ProfilerEventClass]
(
[EventClassID] [INT] NOT NULL,
[Name] [NVARCHAR](50) NULL,
[Description] [NVARCHAR](500) NULL,
CONSTRAINT [PK_ProfilerEventClass] PRIMARY KEY CLUSTERED ([EventClassID] ASC) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
)
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (1, 'Audit Login', 'Collects all new connection events since the trace was started, such as when a client requests a connection to a server running an instance of SQL Server.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (2, 'Audit Logout', 'Collects all new disconnect events since the trace was started, such as when a client issues a disconnect command.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (4, 'Audit Server Starts And Stops', 'Records service shut down, start, and pause activities.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (18, 'Audit Object Permission Event', 'Records object permission changes.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (19, 'Audit Backup/Restore Event', 'Records server backup/restore.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (5, 'Progress Report Begin', 'Progress report begin.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (6, 'Progress Report End', 'Progress report end.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (7, 'Progress Report Current', 'Progress report current.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (8, 'Progress Report Error', 'Progress report error.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (9, 'Query Begin', 'Query begin.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (10, 'Query End', 'Query end.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (15, 'Command Begin', 'Command begin.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (16, 'Command End', 'Command end.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (17, 'Error', 'Server error.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (33, 'Server State Discover Begin', 'Start of Server State Discover.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (34, 'Server State Discover Data', 'Contents of the Server State Discover Response.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (35, 'Server State Discover End', 'End of Server State Discover.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (36, 'Discover Begin', 'Start of Discover Request.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (38, 'Discover End', 'End of Discover Request.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (39, 'Notification', 'Notification event.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (40, 'User Defined', 'User defined Event.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (41, 'Existing Connection', 'Existing user connection.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (42, 'Existing Session', 'Existing session.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (43, 'Session Initialize', 'Session Initialize.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (50, 'Deadlock', 'Metadata locks deadlock.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (51, 'Lock timeout', 'Metadata lock timeout.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (70, 'Query Cube Begin', 'Query cube begin.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (71, 'Query Cube End', 'Query cube end.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (72, 'Calculate Non Empty Begin', 'Calculate non empty begin.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (73, 'Calculate Non Empty Current', 'Calculate non empty current.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (74, 'Calculate Non Empty End', 'Calculate non empty end.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (75, 'Serialize Results Begin', 'Serialize results begin.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (76, 'Serialize Results Current', 'Serialize results current.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (77, 'Serialize Results End', 'Serialize results end.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (78, 'Execute MDX Script Begin', 'Execute MDX script begin.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (79, 'Execute MDX Script Current', 'Execute MDX script current.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (80, 'Execute MDX Script End', 'Execute MDX script end.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (81, 'Query Dimension', 'Query dimension.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (11, 'Query Subcube', 'Query subcube, for Usage Based Optimization.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (12, 'Query Subcube Verbose', 'Query subcube with detailed information. This event may have a negative impact on performance when turned on.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (60, 'Get Data From Aggregation', 'Answer query by getting data from aggregation. This event may have a negative impact on performance when turned on.')
INSERT INTO [dbo].[ProfilerEventClass] ([EventClassID],[Name],[Description]) VALUES (61, 'Get Data From Cache', 'Answer query by getting data from one of the caches. This event may have a negative impact on performance when turned on.')
/*
*************************************************************************
ProfilerEventSubClass Table and Data
*************************************************************************
*/
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[ProfilerEventSubClass]') AND type in (N'U'))
DROP TABLE [dbo].[ProfilerEventSubClass]
CREATE TABLE [dbo].[ProfilerEventSubClass]
(
[EventClassID] [INT] NOT NULL,
[EventSubClassID] [INT] NOT NULL,
[Name] [NVARCHAR](50) NULL,
CONSTRAINT [PK_ProfilerEventSubClass] PRIMARY KEY CLUSTERED ( [EventClassID] ASC, [EventSubClassID] ASC )
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON )
)
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (4, 1, 'Instance Shutdown')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (4, 2, 'Instance Started')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (4, 3, 'Instance Paused')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (4, 4, 'Instance Continued')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (19, 1, 'Backup')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (19, 2, 'Restore')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (19, 3, 'Synchronize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 1, 'Process')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 2, 'Merge')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 3, 'Delete')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 4, 'DeleteOldAggregations')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 5, 'Rebuild')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 6, 'Commit')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 7, 'Rollback')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 8, 'CreateIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 9, 'CreateTable')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 10, 'InsertInto')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 11, 'Transaction')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 12, 'Initialize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 13, 'Discretize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 14, 'Query')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 15, 'CreateView')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 16, 'WriteData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 17, 'ReadData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 18, 'GroupData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 19, 'GroupDataRecord')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 20, 'BuildIndex')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 21, 'Aggregate')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 22, 'BuildDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 23, 'WriteDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 24, 'BuildDMDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 25, 'ExecuteSQL')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 26, 'ExecuteModifiedSQL')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 27, 'Connecting')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 28, 'BuildAggsAndIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 29, 'MergeAggsOnDisk')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 30, 'BuildIndexForRigidAggs')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 31, 'BuildIndexForFlexibleAggs')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 32, 'WriteAggsAndIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 33, 'WriteSegment')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 34, 'DataMiningProgress')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 35, 'ReadBufferFullReport')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 36, 'ProactiveCacheConversion')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 37, 'Backup')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 38, 'Restore')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 39, 'Synchronize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (5, 40, 'Build Processing Schedule')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 1, 'Process')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 2, 'Merge')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 3, 'Delete')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 4, 'DeleteOldAggregations')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 5, 'Rebuild')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 6, 'Commit')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 7, 'Rollback')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 8, 'CreateIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 9, 'CreateTable')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 10, 'InsertInto')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 11, 'Transaction')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 12, 'Initialize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 13, 'Discretize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 14, 'Query')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 15, 'CreateView')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 16, 'WriteData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 17, 'ReadData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 18, 'GroupData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 19, 'GroupDataRecord')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 20, 'BuildIndex')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 21, 'Aggregate')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 22, 'BuildDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 23, 'WriteDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 24, 'BuildDMDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 25, 'ExecuteSQL')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 26, 'ExecuteModifiedSQL')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 27, 'Connecting')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 28, 'BuildAggsAndIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 29, 'MergeAggsOnDisk')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 30, 'BuildIndexForRigidAggs')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 31, 'BuildIndexForFlexibleAggs')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 32, 'WriteAggsAndIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 33, 'WriteSegment')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 34, 'DataMiningProgress')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 35, 'ReadBufferFullReport')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 36, 'ProactiveCacheConversion')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 37, 'Backup')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 38, 'Restore')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 39, 'Synchronize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (6, 40, 'Build Processing Schedule')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 1, 'Process')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 2, 'Merge')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 3, 'Delete')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 4, 'DeleteOldAggregations')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 5, 'Rebuild')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 6, 'Commit')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 7, 'Rollback')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 8, 'CreateIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 9, 'CreateTable')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 10, 'InsertInto')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 11, 'Transaction')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 12, 'Initialize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 13, 'Discretize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 14, 'Query')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 15, 'CreateView')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 16, 'WriteData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 17, 'ReadData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 18, 'GroupData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 19, 'GroupDataRecord')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 20, 'BuildIndex')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 21, 'Aggregate')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 22, 'BuildDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 23, 'WriteDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 24, 'BuildDMDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 25, 'ExecuteSQL')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 26, 'ExecuteModifiedSQL')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 27, 'Connecting')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 28, 'BuildAggsAndIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 29, 'MergeAggsOnDisk')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 30, 'BuildIndexForRigidAggs')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 31, 'BuildIndexForFlexibleAggs')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 32, 'WriteAggsAndIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 33, 'WriteSegment')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 34, 'DataMiningProgress')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 35, 'ReadBufferFullReport')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 36, 'ProactiveCacheConversion')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 37, 'Backup')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 38, 'Restore')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 39, 'Synchronize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (7, 40, 'Build Processing Schedule')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 1, 'Process')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 2, 'Merge')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 3, 'Delete')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 4, 'DeleteOldAggregations')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 5, 'Rebuild')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 6, 'Commit')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 7, 'Rollback')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 8, 'CreateIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 9, 'CreateTable')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 10, 'InsertInto')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 11, 'Transaction')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 12, 'Initialize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 13, 'Discretize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 14, 'Query')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 15, 'CreateView')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 16, 'WriteData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 17, 'ReadData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 18, 'GroupData')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 19, 'GroupDataRecord')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 20, 'BuildIndex')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 21, 'Aggregate')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 22, 'BuildDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 23, 'WriteDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 24, 'BuildDMDecode')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 25, 'ExecuteSQL')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 26, 'ExecuteModifiedSQL')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 27, 'Connecting')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 28, 'BuildAggsAndIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 29, 'MergeAggsOnDisk')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 30, 'BuildIndexForRigidAggs')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 31, 'BuildIndexForFlexibleAggs')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 32, 'WriteAggsAndIndexes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 33, 'WriteSegment')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 34, 'DataMiningProgress')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 35, 'ReadBufferFullReport')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 36, 'ProactiveCacheConversion')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 37, 'Backup')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 38, 'Restore')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 39, 'Synchronize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (8, 40, 'Build Processing Schedule')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (9, 0, 'MDXQuery')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (9, 1, 'DMXQuery')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (9, 2, 'SQLQuery')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (10, 0, 'MDXQuery')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (10, 1, 'DMXQuery')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (10, 2, 'SQLQuery')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 0, 'Create')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 1, 'Alter')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 2, 'Delete')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 3, 'Process')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 4, 'DesignAggregations')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 5, 'WBInsert')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 6, 'WBUpdate')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 7, 'WBDelete')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 8, 'Backup')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 9, 'Restore')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 10, 'MergePartitions')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 11, 'Subscribe')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 12, 'Batch')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 13, 'BeginTransaction')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 14, 'CommitTransaction')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 15, 'RollbackTransaction')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 16, 'GetTransactionState')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 17, 'Cancel')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 18, 'Synchronize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 19, 'Import80MiningModels')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (15, 10000, 'Other')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 0, 'Create')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 1, 'Alter')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 2, 'Delete')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 3, 'Process')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 4, 'DesignAggregations')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 5, 'WBInsert')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 6, 'WBUpdate')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 7, 'WBDelete')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 8, 'Backup')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 9, 'Restore')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 10, 'MergePartitions')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 11, 'Subscribe')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 12, 'Batch')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 13, 'BeginTransaction')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 14, 'CommitTransaction')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 15, 'RollbackTransaction')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 16, 'GetTransactionState')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 17, 'Cancel')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 18, 'Synchronize')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 19, 'Import80MiningModels')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (16, 10000, 'Other')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (33, 1, 'DISCOVER_CONNECTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (33, 2, 'DISCOVER_SESSIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (33, 3, 'DISCOVER_TRANSACTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (33, 6, 'DISCOVER_DB_CONNECTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (33, 7, 'DISCOVER_JOBS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (33, 8, 'DISCOVER_LOCKS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (33, 12, 'DISCOVER_PERFORMANCE_COUNTERS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (33, 13, 'DISCOVER_MEMORYUSAGE')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (33, 14, 'DISCOVER_JOB_PROGRESS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (33, 15, 'DISCOVER_MEMORYGRANT')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (34, 1, 'DISCOVER_CONNECTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (34, 2, 'DISCOVER_SESSIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (34, 3, 'DISCOVER_TRANSACTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (34, 6, 'DISCOVER_DB_CONNECTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (34, 7, 'DISCOVER_JOBS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (34, 8, 'DISCOVER_LOCKS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (34, 12, 'DISCOVER_PERFORMANCE_COUNTERS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (34, 13, 'DISCOVER_MEMORYUSAGE')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (34, 14, 'DISCOVER_JOB_PROGRESS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (34, 15, 'DISCOVER_MEMORYGRANT')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (35, 1, 'DISCOVER_CONNECTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (35, 2, 'DISCOVER_SESSIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (35, 3, 'DISCOVER_TRANSACTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (35, 6, 'DISCOVER_DB_CONNECTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (35, 7, 'DISCOVER_JOBS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (35, 8, 'DISCOVER_LOCKS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (35, 12, 'DISCOVER_PERFORMANCE_COUNTERS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (35, 13, 'DISCOVER_MEMORYUSAGE')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (35, 14, 'DISCOVER_JOB_PROGRESS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (35, 15, 'DISCOVER_MEMORYGRANT')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 0, 'DBSCHEMA_CATALOGS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 1, 'DBSCHEMA_TABLES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 2, 'DBSCHEMA_COLUMNS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 3, 'DBSCHEMA_PROVIDER_TYPES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 4, 'MDSCHEMA_CUBES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 5, 'MDSCHEMA_DIMENSIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 6, 'MDSCHEMA_HIERARCHIES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 7, 'MDSCHEMA_LEVELS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 8, 'MDSCHEMA_MEASURES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 9, 'MDSCHEMA_PROPERTIES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 10, 'MDSCHEMA_MEMBERS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 11, 'MDSCHEMA_FUNCTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 12, 'MDSCHEMA_ACTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 13, 'MDSCHEMA_SETS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 14, 'DISCOVER_INSTANCES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 15, 'MDSCHEMA_KPIS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 16, 'MDSCHEMA_MEASUREGROUPS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 17, 'MDSCHEMA_COMMANDS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 18, 'DMSCHEMA_MINING_SERVICES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 19, 'DMSCHEMA_MINING_SERVICE_PARAMETERS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 20, 'DMSCHEMA_MINING_FUNCTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 21, 'DMSCHEMA_MINING_MODEL_CONTENT')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 22, 'DMSCHEMA_MINING_MODEL_XML')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 23, 'DMSCHEMA_MINING_MODELS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 24, 'DMSCHEMA_MINING_COLUMNS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 25, 'DISCOVER_DATASOURCES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 26, 'DISCOVER_PROPERTIES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 27, 'DISCOVER_SCHEMA_ROWSETS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 28, 'DISCOVER_ENUMERATORS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 29, 'DISCOVER_KEYWORDS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 30, 'DISCOVER_LITERALS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 31, 'DISCOVER_XML_METADATA')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 32, 'DISCOVER_TRACES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 33, 'DISCOVER_TRACE_DEFINITION_PROVIDERINFO')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 34, 'DISCOVER_TRACE_COLUMNS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 35, 'DISCOVER_TRACE_EVENT_CATEGORIES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 36, 'DMSCHEMA_MINING_STRUCTURES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 37, 'DMSCHEMA_MINING_STRUCTURE_COLUMNS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 38, 'DISCOVER_MASTER_KEY')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 39, 'MDSCHEMA_INPUT_DATASOURCES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 40, 'DISCOVER_LOCATIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 41, 'DISCOVER_PARTITION_DIMENSION_STAT')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 42, 'DISCOVER_PARTITION_STAT')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (36, 43, 'DISCOVER_DIMENSION_STAT')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 0, 'DBSCHEMA_CATALOGS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 1, 'DBSCHEMA_TABLES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 2, 'DBSCHEMA_COLUMNS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 3, 'DBSCHEMA_PROVIDER_TYPES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 4, 'MDSCHEMA_CUBES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 5, 'MDSCHEMA_DIMENSIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 6, 'MDSCHEMA_HIERARCHIES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 7, 'MDSCHEMA_LEVELS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 8, 'MDSCHEMA_MEASURES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 9, 'MDSCHEMA_PROPERTIES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 10, 'MDSCHEMA_MEMBERS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 11, 'MDSCHEMA_FUNCTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 12, 'MDSCHEMA_ACTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 13, 'MDSCHEMA_SETS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 14, 'DISCOVER_INSTANCES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 15, 'MDSCHEMA_KPIS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 16, 'MDSCHEMA_MEASUREGROUPS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 17, 'MDSCHEMA_COMMANDS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 18, 'DMSCHEMA_MINING_SERVICES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 19, 'DMSCHEMA_MINING_SERVICE_PARAMETERS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 20, 'DMSCHEMA_MINING_FUNCTIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 21, 'DMSCHEMA_MINING_MODEL_CONTENT')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 22, 'DMSCHEMA_MINING_MODEL_XML')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 23, 'DMSCHEMA_MINING_MODELS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 24, 'DMSCHEMA_MINING_COLUMNS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 25, 'DISCOVER_DATASOURCES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 26, 'DISCOVER_PROPERTIES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 27, 'DISCOVER_SCHEMA_ROWSETS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 28, 'DISCOVER_ENUMERATORS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 29, 'DISCOVER_KEYWORDS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 30, 'DISCOVER_LITERALS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 31, 'DISCOVER_XML_METADATA')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 32, 'DISCOVER_TRACES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 33, 'DISCOVER_TRACE_DEFINITION_PROVIDERINFO')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 34, 'DISCOVER_TRACE_COLUMNS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 35, 'DISCOVER_TRACE_EVENT_CATEGORIES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 36, 'DMSCHEMA_MINING_STRUCTURES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 37, 'DMSCHEMA_MINING_STRUCTURE_COLUMNS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 38, 'DISCOVER_MASTER_KEY')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 39, 'MDSCHEMA_INPUT_DATASOURCES')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (38, 40, 'DISCOVER_LOCATIONS')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 0, 'Proactive Caching Begin')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 1, 'Proactive Caching End')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 2, 'Flight Recorder Started')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 3, 'Flight Recorder Stopped')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 4, 'Configuration Properties Updated')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 5, 'SQL Trace')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 6, 'Object Created')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 7, 'Object Deleted')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 8, 'Object Altered')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 9, 'Proactive Caching Polling Begin')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 10, 'Proactive Caching Polling End')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 11, 'Flight Recorder Snapshot Begin')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 12, 'Flight Recorder Snapshot End')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 13, 'Proactive Caching: notifiable object updated')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 14, 'Lazy Processing: start processing')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (39, 15, 'Lazy Processing: processing complete')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (73, 1, 'Get Data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (73, 2, 'Process Calculated Members')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (73, 3, 'Post Order')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (76, 1, 'Serialize Axes')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (76, 2, 'Serialize Cells')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (76, 3, 'Serialize SQL Rowset')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (76, 4, 'Serialize Flattened Rowset')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (81, 1, 'Cache data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (81, 2, 'Non-cache data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (11, 1, 'Cache data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (11, 2, 'Non-cache data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (11, 3, 'Internal data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (11, 4, 'SQL data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (11, 11, 'Measure Group Structural Change')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (11, 12, 'Measure Group Deletion')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (12, 21, 'Cache data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (12, 22, 'Non-cache data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (12, 23, 'Internal data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (12, 24, 'SQL data')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (61, 1, 'Get data from measure group cache')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (61, 2, 'Get data from flat cache')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (61, 3, 'Get data from calculation cache')
INSERT INTO [dbo].[ProfilerEventSubClass] ([EventClassID], [EventSubClassID],[Name]) VALUES (61, 4, 'Get data from persisted cache')
Agora já consigo intepretar melhor os resultados juntando os dados da minha tabela de monitoramento com essas 2 criadas, de acordo com o exemplo abaixo:
SELECT
B.[Name] AS [Class],
B.[Description] AS [ClassDescription],
C.[Name] AS [SubClass],
[A].[RowNumber],
[A].[EventClass],
[A].[EventSubclass],
[A].[TextData],
[A].[ConnectionID],
[A].[NTUserName],
[A].[ApplicationName],
[A].[IntegerData],
[A].[StartTime],
[A].[CurrentTime],
[A].[Duration],
[A].[DatabaseName],
[A].[ObjectName],
[A].[Error],
[A].[ClientProcessID],
[A].[SPID],
[A].[CPUTime],
[A].[NTDomainName]
FROM
[dbo].[Monitora_SSAS] A
JOIN [dbo].[ProfilerEventClass] B ON A.[EventClass] = B.[EventClassID]
LEFT JOIN [dbo].[ProfilerEventSubClass] C ON A.[EventSubclass] = C.[EventSubClassID] AND [B].[EventClassID] = [C].[EventClassID]
ORDER BY
[A].[RowNumber]
E me retorna uma tabela igual a essa aqui:
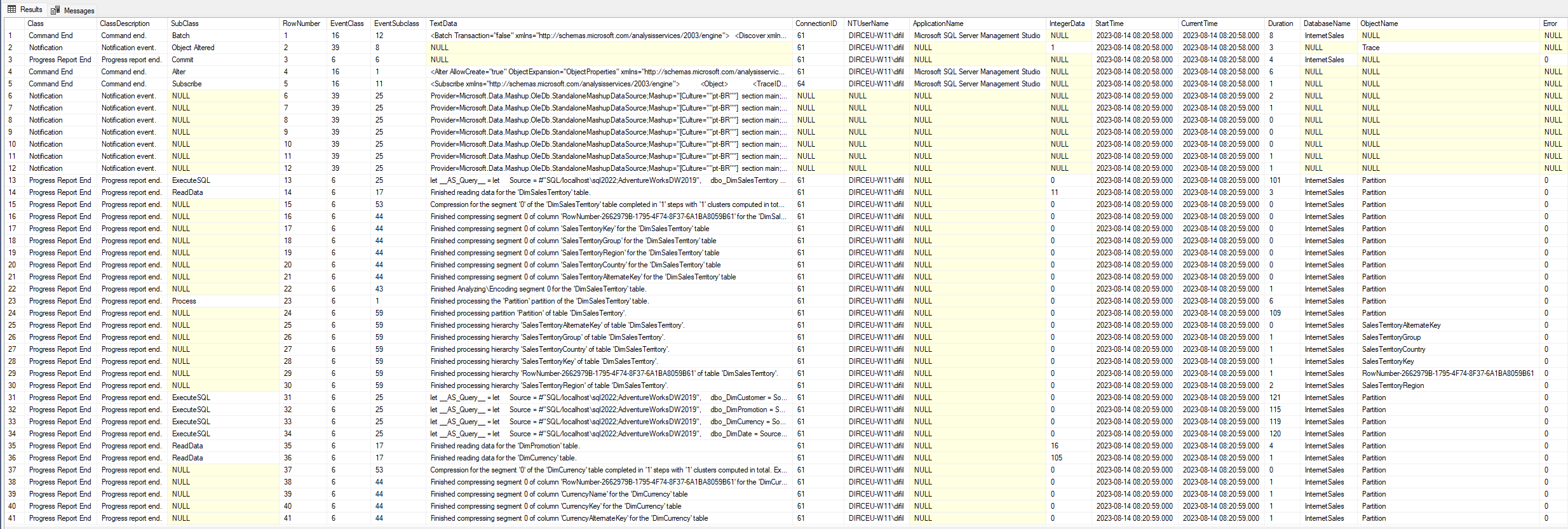
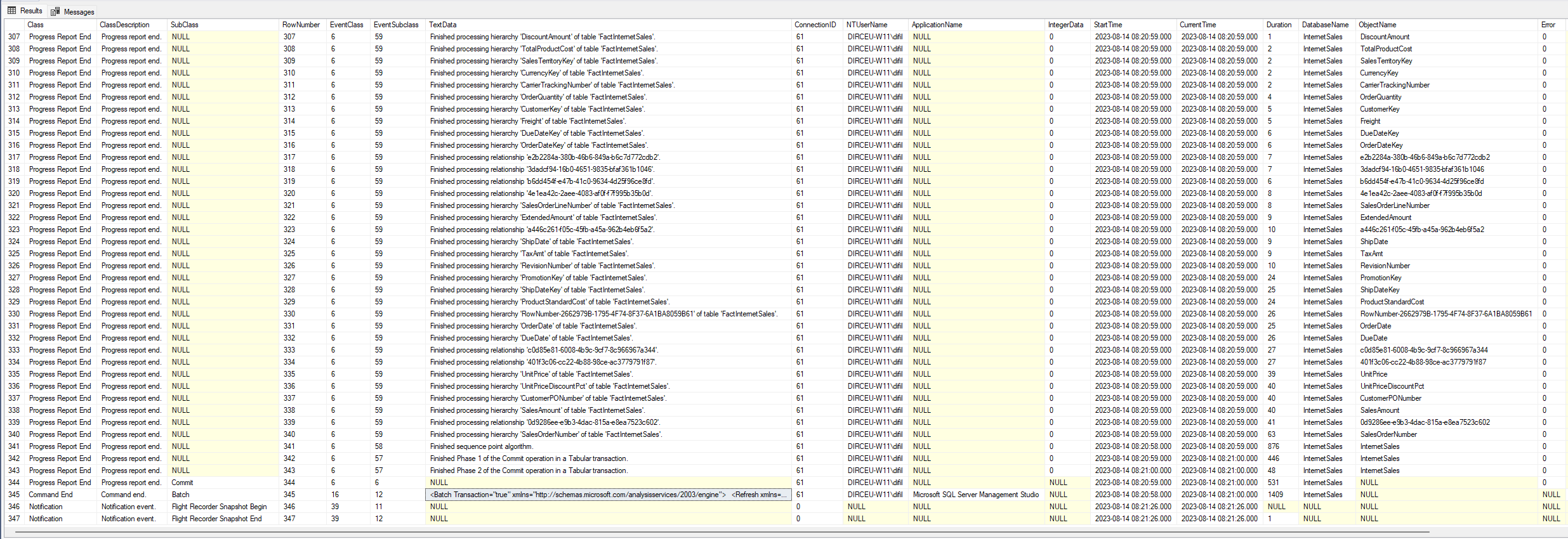
Alguns pontos importantes para destacar sobre os dados retornados:
- As colunas “Duration” e “CPU Time” são medidas em millisegundos
- A coluna “IntegerData” retorna a quantidade de linhas processadas (funciona apenas em alguns eventos, como ReadData)
- A coluna “SPID” é o ID da sessão do usuário que está executando. Ela pode ser utilizada para isolar alguma execução específica, quando existem várias operações sendo executadas ao mesmo tempo no servidor
- Não incluí os eventos de “Begin” e nem “Current”, somente os de “End”, pois somente nessa etapa que as colunas de “Duration” e “CPU Time” retornam dados
- Nos eventos de “End”, a coluna “StartTime” é quando a operação começou, e a coluna “CurrentTime” é quando ela terminou
Preste muita atenção para não consumir muito espaço em disco com esses logs e isso acabar virando um problema futuramente.
Então é isso aí, pessoal!
Espero que tenham gostado dessa dica e agora vocês consigam monitorar seus processamentos de cubo.

Comentários (0)
Carregando comentários...