Neste post irei falar um pouco sobre o método de compressão de dados do SQL Server e como podemos utilizar esse recurso para compactar todos os objetos de um database. A compressão de dados pode ser configurada para os seguintes objetos de banco de dados:
- Para uma tabela que é armazenada como um heap.
- Para uma tabela que é armazenada como um índice clustered.
- Para um índice nonclustered.
- Para uma view indexada.
- Para tabelas e índices particionados, a opção de compressão pode ser configurada para cada partição, e as várias partições de um objeto podem conter diferentes tem configurações de compressão.
Lembrando que a compressão não está disponível para objetos de sistema e a configuração de compressão não é aplicada automaticamente a índices nonclustered. Sendo assim, cada índice nonclustered deve ser configurado individual e manualmente.
ROW COMPRESSION LEVEL
Esta característica de compressão leva em conta o tipo de estruturas de dados variáveis que definem uma coluna. Row Compression Level é um nível de compressão que não utiliza nenhum algoritmo de compressão.
O principal objetivo da Row Compression Level é reduzir o armazenamento de dados do tipo fixos, ou seja, quando você está permitindo Row Level Compression você está apenas mudando o formato de armazenamento físico dos dados que estão associados a um tipo de dados.
Row Level Compression estende o formato de armazenamento vardecimal por armazenar dados de todos os tipos de comprimento fixo em um formato de armazenamento de comprimento variável. Este tipo de compressão irá remover quaisquer bytes extras no tipo de dados fixo. Não há absolutamente nenhuma mudança necessária no aplicativo.
Por exemplo, temos uma coluna CHAR (100) que está usando o Row Compression Level só usará a quantidade de armazenamento definida pelos dados. Como assim? Vamos armazenar a frase “SQL Server 2008″ na coluna, a frase contem apenas 15 caracteres e apenas esses 15 caracteres são armazenados ao contrario dos 100 que foram definidos pela coluna, portanto, você tem uma economia de 85% no espaço de armazenamento.
PAGE COMPRESSION LEVEL
Nas versões anteriores do SQL Server cada valor era armazenado na página, independentemente se o mesmo valor já havia aparecido na mesma coluna para algumas outras linhas dentro de uma página. No SQL Server 2008, o valor redundante ou duplicado será armazenado apenas uma vez dentro da página e o será referenciado em todas as outras ocorrências, dessa forma temos o Page Compression Level.
Basicamente, o Page Compression Level é um superconjunto de compressão ROW e leva em conta os dados redundantes em uma ou mais linhas em uma determinada página. Ele também usa a compactação de prefixo e dicionário.
O método Page Compression Level é mais vital, pois permite que os dados comuns sejam compartilhados entre as linhas de uma determinada página.
Esse tipo de compressão utiliza as seguintes técnicas:
- ROW COMPRESSION: Já visto acima.
- PREFIX COMPRESSION: Para cada coluna em uma página os prefixos duplicados são identificados. Estes prefixos são armazenados nos cabeçalhos de Compressão de Informação (CI), que residem após o cabeçalho da página. Um número de referência é atribuído a esses prefixos e esse número de referência é utilizado onde quer que esses prefixos estejam sendo usados, diminuindo a quantidade de bytes utilizados.
- DICTIONARY COMPRESSION: Pesquisas por valores duplicados por fora da página e as armazena no CI. A principal diferença entre o Prefix Compression e Dictionary Compression é que o Prefix se restringe apenas a uma coluna enquanto Dictionary é aplicável para a página completa.
Depois que a Prefix Compression foi concluída, a Dictionary Compression é aplicada e pesquisas valores repetidos em qualquer lugar da página e os armazena na área de CI. Ao contrário da Prefix Compression, a Dictionary Compression não está restrita a uma coluna e pode substituir valores repetidos, que ocorrem em qualquer lugar em uma página.
Estimando o ganho de espaço
No SQL Server 2008 existem duas maneiras de estimar a economia de espaço para armazenamento de tabelas e índices. O primeiro método é usar uma SP de sistema chamada sp_estimate_data_compression_savings e o segundo método é usar o Assistente de Compactação de Dados.
Primeiro vamos usar a sp_estimate_data_compression_savings onde:
1º parâmetro é o nome do schema;
2º parâmetro é o nome do objeto;
3º parâmetro é o ID do índice;
4º parâmetro é o ID da Partição
5º parâmetro é o tipo de compressão;
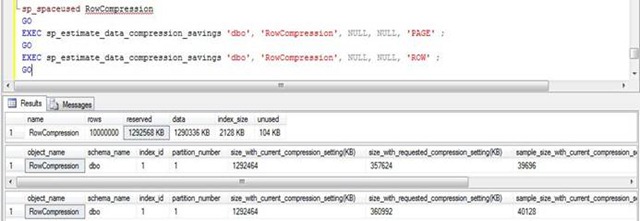
Notem as colunas size_with_current_compression_setting(KB) e size_with_requested_compression_setting(KB), essas colunas mostras o valor atual e o valor após a compressão. Dessa forma podemos saber quanto de espaço iremos ganhar com a aplicação da compressão.
Agora vamos utilizar o assistente.
Clique com o botão direito em cima da tabela escolha a opção Storege -> Manage Compression
Será aberta a tela do assistente de compressão
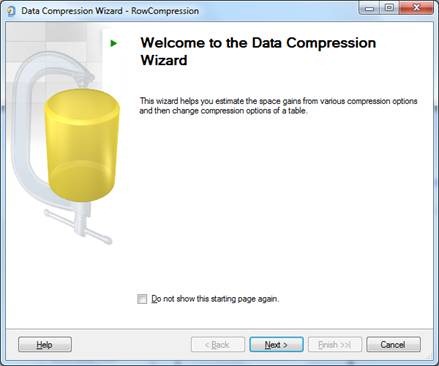
Na próxima tela do assiste, você pode testar o tipo de compressão e antes de aplicar você pode calcular o espaço para verificar qual obteve a maior taxa de compressão de dados.
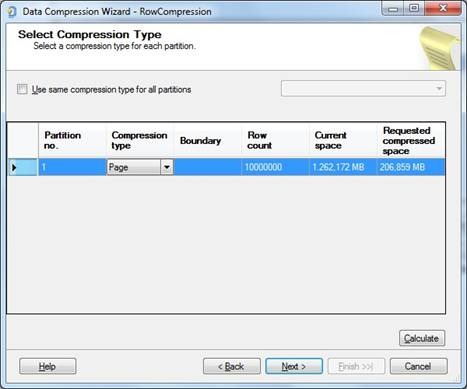
Seguindo com o assistente de compressão, escolhi a opção PAGE, que geralmente obtém o melhor resultado, e em seguida irá perguntar o que fazer: Apenas gerar o script, executar a compactação ou agendar a alteração para ativar a compactação.
Por fim, será mostrado na tela uma mensagem de sucesso na compressão dos dados
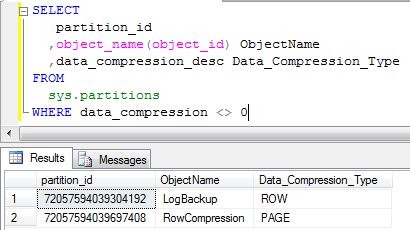
Você pode verificar todos os seus objetos e quais níveis de compressão eles estão clicando com o botão direito em cima do objeto, na guia Storage, a opção Compression informa o tipo de compressão ou utilizando o comando:
SELECT
A.[partition_id],
A.[object_id],
object_name(A.[object_id]) AS [object_name],
data_compression_desc
FROM
sys.partitions A
join sys.objects B on A.[object_id] = B.[object_id]
WHERE
B.is_ms_shipped = 0
Aplicando compressão em um banco de dados inteiro
Nesse post já vimos o quão benéfica é a compressão de dados, principalmente para o storage. Pois bem, vamos colocar isso em prática. Criei uma procedure que permite compactar todos os objetos de um database, de forma fácil e rápida. O código da procedure está disponível aqui:
CREATE PROCEDURE [dbo].[stpCompacta_Database] (
@Ds_Database SYSNAME,
@Fl_Rodar_Shrink BIT = 1,
@Fl_Parar_Se_Falhar BIT = 1,
@Fl_Exibe_Comparacao_Tamanho BIT = 1,
@Fl_Metodo_Compressao_Page BIT = 1
)
AS
BEGIN
SET NOCOUNT ON
DECLARE
@Ds_Query VARCHAR(MAX),
@Ds_Comando_Compactacao VARCHAR(MAX),
@Ds_Metodo_Compressao VARCHAR(20) = (CASE WHEN @Fl_Metodo_Compressao_Page = 1 THEN 'PAGE' ELSE 'ROW' END),
@Nr_Metodo_Compressao VARCHAR(20) = (CASE WHEN @Fl_Metodo_Compressao_Page = 1 THEN 2 ELSE 1 END)
IF (OBJECT_ID('tempdb..#Comandos_Compactacao') IS NOT NULL) DROP TABLE #Comandos_Compactacao
CREATE TABLE #Comandos_Compactacao
(
Id BIGINT IDENTITY(1, 1),
Tabela SYSNAME,
Indice SYSNAME NULL,
Comando VARCHAR(MAX)
)
IF (@Fl_Exibe_Comparacao_Tamanho = 1)
BEGIN
SET @Ds_Query = '
SELECT
(SUM(a.total_pages) / 128) AS Vl_Tamanho_Tabelas_Antes_Compactacao
FROM
[' + @Ds_Database + '].sys.tables t WITH(NOLOCK)
INNER JOIN [' + @Ds_Database + '].sys.indexes i WITH(NOLOCK) ON t.OBJECT_ID = i.object_id
INNER JOIN [' + @Ds_Database + '].sys.partitions p WITH(NOLOCK) ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN [' + @Ds_Database + '].sys.allocation_units a WITH(NOLOCK) ON p.partition_id = a.container_id
WHERE
i.OBJECT_ID > 255
'
EXEC(@Ds_Query)
END
SET @Ds_Query =
'INSERT INTO #Comandos_Compactacao( Tabela, Indice, Comando )
SELECT DISTINCT
A.name AS Tabela,
NULL AS Indice,
''ALTER TABLE ['' + ''' + @Ds_Database + ''' + ''].['' + C.name + ''].['' + A.name + ''] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = ' + @Ds_Metodo_Compressao + ')'' AS Comando
FROM
[' + @Ds_Database + '].sys.tables A
INNER JOIN [' + @Ds_Database + '].sys.partitions B ON A.object_id = B.object_id
INNER JOIN [' + @Ds_Database + '].sys.schemas C ON A.schema_id = C.schema_id
WHERE
B.data_compression <> ' + @Nr_Metodo_Compressao + ' -- NONE
AND B.data_compression_desc NOT LIKE ''COLUMNSTORE%''
AND B.index_id = 0
AND A.type = ''U''
UNION
SELECT DISTINCT
B.name AS Tabela,
A.name AS Indice,
''ALTER INDEX ['' + A.name + ''] ON ['' + ''' + @Ds_Database + ''' + ''].['' + C.name + ''].['' + B.name + ''] REBUILD PARTITION = ALL WITH ( STATISTICS_NORECOMPUTE = OFF, ONLINE = OFF, SORT_IN_TEMPDB = OFF, DATA_COMPRESSION = ' + @Ds_Metodo_Compressao + ')''
FROM
[' + @Ds_Database + '].sys.indexes A
INNER JOIN [' + @Ds_Database + '].sys.tables B ON A.object_id = B.object_id
INNER JOIN [' + @Ds_Database + '].sys.schemas C ON B.schema_id = C.schema_id
INNER JOIN [' + @Ds_Database + '].sys.partitions D ON A.object_id = D.object_id AND A.index_id = D.index_id
WHERE
D.data_compression <> ' + @Nr_Metodo_Compressao + ' -- NONE
AND D.data_compression_desc NOT LIKE ''COLUMNSTORE%''
AND D.index_id <> 0
AND B.type = ''U''
ORDER BY
Tabela,
Indice
'
EXEC(@Ds_Query)
DECLARE
@Qt_Comandos INT = (SELECT COUNT(*) FROM #Comandos_Compactacao),
@Contador INT = 1,
@Ds_Mensagem VARCHAR(MAX),
@Nr_Codigo_Erro INT = (CASE WHEN @Fl_Parar_Se_Falhar = 1 THEN 16 ELSE 10 END)
WHILE(@Contador <= @Qt_Comandos)
BEGIN
SELECT
@Ds_Comando_Compactacao = Comando
FROM
#Comandos_Compactacao
WHERE
Id = @Contador
BEGIN TRY
SET @Ds_Mensagem = 'Executando comando "' + @Ds_Comando_Compactacao + '"... Aguarde...'
RAISERROR(@Ds_Mensagem, 10, 1) WITH NOWAIT
EXEC(@Ds_Comando_Compactacao)
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() AS ErrorState,
ERROR_PROCEDURE() AS ErrorProcedure,
ERROR_LINE() AS ErrorLine,
ERROR_MESSAGE() AS ErrorMessage;
SET @Ds_Mensagem = 'Falha ao executar o comando "' + @Ds_Comando_Compactacao + '"'
RAISERROR(@Ds_Mensagem, @Nr_Codigo_Erro, 1) WITH NOWAIT
RETURN
END CATCH
SET @Contador = @Contador + 1
END
IF (@Fl_Exibe_Comparacao_Tamanho = 1)
BEGIN
SET @Ds_Query = '
SELECT
(SUM(a.total_pages) / 128) AS Vl_Tamanho_Tabelas_Depois_Compactacao
FROM
[' + @Ds_Database + '].sys.tables t WITH(NOLOCK)
INNER JOIN [' + @Ds_Database + '].sys.indexes i WITH(NOLOCK) ON t.OBJECT_ID = i.object_id
INNER JOIN [' + @Ds_Database + '].sys.partitions p WITH(NOLOCK) ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN [' + @Ds_Database + '].sys.allocation_units a WITH(NOLOCK) ON p.partition_id = a.container_id
WHERE
i.OBJECT_ID > 255
'
EXEC(@Ds_Query)
END
IF (@Fl_Rodar_Shrink = 1)
BEGIN
SET @Ds_Query = '
USE ' + @Ds_Database + '
DBCC SHRINKFILE (' + @Ds_Database + ', 1) WITH NO_INFOMSGS
'
EXEC(@Ds_Query)
END
IF (@Qt_Comandos > 0)
PRINT 'Database "' + @Ds_Database + '" compactado com sucesso!'
ELSE
PRINT 'Nenhum objeto para compactar no database "' + @Ds_Database + '"'
ENDExemplo de utilização:
EXEC dbo.stpCompacta_Database
@Ds_Database = 'Testes', -- sysname
@Fl_Rodar_Shrink = 1, -- bit
@Fl_Parar_Se_Falhar = 0, -- bit
@Fl_Exibe_Comparacao_Tamanho = 1, -- bit
@Fl_Metodo_Compressao_Page = 1 -- bit
Obs: Não recomendo utilizar a opção @Fl_Rodar_Shrink em ambientes de produção.
sql server, compactar tabela, compactar database, comprimir, compression, compact, shrink

Comentários (0)
Carregando comentários...