
Fala pessoal! Tudo bem com vocês?
Hoje o assunto será dos mais interessantes: Expressões regulares!
Introdução
Quem me acompanha há mais tempo sabe que eu sempre bati na tecla de que o suporte a expressões regulares no SQL Server era uma lacuna imensa. Em 2018, eu escrevi o artigo SQL Server – Como utilizar expressões regulares (RegExp) no seu banco de dados, detalhando como contornar essa limitação usando o LIKE do WHERE (funciona, mas é limitado), SQLCLR, criando uma DLL em C# e embarcando dentro do banco de dados para termos o poder do Regex ou utilizando OLE Automation.
Funcionou por anos, mas sempre com aquele “overhead” de contexto entre o motor do SQL e o CLR, além das restrições de segurança (PERMISSION_SET) que muitas vezes barravam a implementação em ambientes mais restritos, como o Azure SQL Database.
Com a chegada do SQL Server 2025 e as atualizações de maio de 2024 no Azure SQL Database, a Microsoft finalmente ouviu a comunidade e trouxe o suporte nativo para expressões regulares. Estamos falando de funções integradas diretamente no motor, otimizadas e prontas para o uso sem a necessidade de configurações externas.
Neste post, vou demonstrar essas novas funções, entender a sintaxe e, claro, comparar com o nosso antigo método via SQLCLR para ver o que realmente muda na vida do DBA e do Desenvolvedor.
Vídeo sobre expressões regulares:
As Novas Funções de Expressão Regular
Diferente do antigo LIKE (que é extremamente limitado), as novas funções utilizam o padrão RE2, desenvolvido pelo Google, permitindo buscas complexas, extrações e substituições de strings de forma muito mais performática.
As funções introduzidas, conforme podemos observar na documentação oficial, são:
Funções Escalares:
- REGEXP_LIKE: Valida se a string bate com o padrão (Retorna BIT).
- REGEXP_COUNT: Conta as ocorrências do padrão.
- REGEXP_INSTR: Localiza a posição de um padrão.
- REGEXP_REPLACE: Substitui padrões por novos textos.
- REGEXP_SUBSTR: Extrai uma parte da string.
Funções de Tabela (Rowsets):
- REGEXP_MATCHES: Extrai todas as ocorrências de um padrão e as retorna como linhas de uma tabela, inclusive separando os grupos de captura.
- REGEXP_SPLIT_TO_TABLE: Divide uma string em várias linhas usando um padrão Regex como delimitador (o STRING_SPLIT dos sonhos).
Tabela de Comparação de Funcionalidades
Abaixo, preparei uma tabela comparativa para facilitar a visualização de como cada função se comporta em relação aos parâmetros comuns:
| Função | Tipo | Objetivo Principal | Retorno Principal |
|---|---|---|---|
| REGEXP_LIKE | Escalar | Validar se um texto segue um padrão (Email, CPF, etc.) | Boolean (1 ou 0) |
| REGEXP_COUNT | Escalar | Contar quantas vezes um padrão ocorre em um texto | Integer |
| REGEXP_INSTR | Escalar | Localizar a posição inicial/final de um padrão | Integer (Posição) |
| REGEXP_REPLACE | Escalar | Substituir ocorrências de um padrão por um novo texto | VARCHAR / NVARCHAR |
| REGEXP_SUBSTR | Escalar | Extrair uma parte específica (substring) baseada no padrão | VARCHAR / NVARCHAR |
| REGEXP_MATCHES | Tabular | Extrair todas as ocorrências e seus grupos de captura | Table (Rowset) |
| REGEXP_SPLIT_TO_TABLE | Tabular | Dividir uma string em várias linhas usando Regex como delimitador | Table (Rowset) |
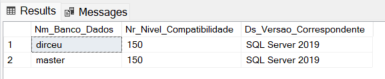
Para verificar qual o nível de compatibilidade das suas bases de dados, você pode utilizar o script T-SQL abaixo:
-- CONSULTA DE COMPATIBILIDADE DAS BASES DE DADOS
SELECT
[A].[name] AS [Nm_Banco_Dados],
[A].[compatibility_level] AS [Nr_Nivel_Compatibilidade],
CASE [A].[compatibility_level]
WHEN 100 THEN 'SQL Server 2008 / 2008 R2'
WHEN 110 THEN 'SQL Server 2012'
WHEN 120 THEN 'SQL Server 2014'
WHEN 130 THEN 'SQL Server 2016'
WHEN 140 THEN 'SQL Server 2017'
WHEN 150 THEN 'SQL Server 2019'
WHEN 160 THEN 'SQL Server 2022'
WHEN 170 THEN 'SQL Server 2025'
ELSE 'Versão Desconhecida / Legacy'
END AS [Ds_Versao_Correspondente]
FROM
[sys].[databases] AS [A]
ORDER BY
[A].[compatibility_level] DESC,
[A].[name] ASC;
Caso você queira alterar o nível de compatibilidade para 170 (SQL Server 2025) e você possa utilizar as funções de expressão regular, utilize o comando abaixo:
ALTER DATABASE [SeuBanco] SET COMPATIBILITY_LEVEL = 170
Msg 19304, Level 16, State 5, Line 35
Currently, ‘REGEXP_MATCHES’ function does not support NVARCHAR(max)/VARCHAR(max) inputs.
Por que RE2 e não PCRE ou POSIX puro?
A maioria das bibliotecas de Regex (como a PCRE usada no PHP/Python ou a própria biblioteca do .NET que usamos no SQLCLR) utiliza um algoritmo de Backtracking.
Isso é poderoso, mas perigoso para um banco de dados. Se um desenvolvedor escreve uma expressão regular mal formatada, ele pode causar o que chamamos de ReDoS (Regular Expression Denial of Service). O motor de busca entra em um loop exponencial de tentativas (catastrophic backtracking), trava um núcleo de CPU em 100% e pode derrubar a performance da instância inteira.
O RE2 foi projetado para ser seguro:
- Tempo Linear: O RE2 garante que o tempo de execução seja linear em relação ao tamanho da string de entrada ($O(n)$).
- Previsibilidade: Ele não permite retrocessos (backtracking), o que significa que ele nunca vai “travar” seu servidor, não importa quão complexa seja a expressão.
- Segurança de Memória: O consumo de memória é controlado e finito, ideal para quem gerencia Buffer Pool e Memory Clerks.
Quando olhamos para os Wait Types, o uso do RE2 nativo tende a concentrar o esforço puramente em SOS_SCHEDULER_YIELD (se a consulta for muito longa) em vez de travar recursos externos ou gerar eventos de WAIT de CLR_AUTO_EVENT.
Quer mais informações?
Sintaxe básica:
| Metacaractere | Descrição |
|---|---|
| . | Corresponde a qualquer caractere único (muitas aplicações excluem quebras de linha, e exatamente quais caracteres são considerados quebras de linha é específico do “sabor” do regex, da codificação de caracteres e da plataforma, mas é seguro assumir que o caractere de avanço de linha (line feed) está incluído). Dentro de expressões de colchetes POSIX, o caractere ponto corresponde a um ponto literal. Por exemplo, a.c corresponde a “abc”, etc., mas [a.c] corresponde apenas a “a”, “.”, ou “c”. |
| [ ] | Uma expressão de colchetes. Corresponde a um único caractere contido dentro dos colchetes. Por exemplo, [abc] corresponde a “a”, “b”, ou “c”, e [a-z] especifica um intervalo que corresponde a qualquer letra minúscula de “a” a “z”. Essas formas podem ser misturadas: [abcx-z] corresponde a “a”, “b”, “c”, “x”, “y”, ou “z”, assim como [a-cx-z].
O caractere – é tratado como um caractere literal se for o último ou o primeiro caractere dentro dos colchetes: [abc-], [-abc]. O caractere ] pode ser incluído em uma expressão de colchetes se for o primeiro caractere: []abc]. A expressão de colchetes também pode conter classes de caracteres, classes de equivalência e caracteres de agrupamento (collating characters). |
| [^ ] | Corresponde a um único caractere que não está contido dentro dos colchetes. Por exemplo, [^abc] corresponde a qualquer caractere que não seja “a”, “b”, ou “c”, e [^a-z] corresponde a qualquer caractere único que não seja uma letra minúscula de “a” a “z”. Essas formas podem ser misturadas: [^abcx-z] corresponde a qualquer caractere exceto “a”, “b”, “c”, “x”, “y”, ou “z”.
O caractere – é tratado como um caractere literal se for o último caractere ou o primeiro caractere após o ^: [^abc-], [^-abc]. O caractere ] é tratado como um caractere literal se for o primeiro caractere após o ^: [^]abc]. A expressão também pode conter classes de caracteres, classes de equivalência e caracteres de agrupamento. |
| ^ | Corresponde à posição inicial dentro da string, se for o primeiro caractere da expressão regular. |
| $ | Corresponde à posição final da string, se for o último caractere da expressão regular. |
| * | Corresponde ao elemento anterior zero ou mais vezes. Por exemplo, ab*c corresponde a “ac”, “abc”, “abbbc”, etc. [xyz]* corresponde a “”, “x”, “y”, “z”, “zx”, “zyx”, “xyzzy”, e assim por diante. |
Exemplos:
- .at corresponde a qualquer string de três caracteres terminada em “at”, incluindo “hat”, “cat” e “bat”.
- [hc]at corresponde a “hat” e “cat”.
- [^b]at corresponde a todas as strings identificadas por .at, exceto “bat”.
- ^[hc]at corresponde a “hat” e “cat”, mas apenas no início da string ou linha.
- [hc]at$ corresponde a “hat” e “cat”, mas apenas no final da string ou linha.
- \[.\] corresponde a qualquer caractere único cercado por “[” e “]” já que os colchetes estão escapados; por exemplo: “[a]” e “[b]”.
Classes POSIX:
| Classe POSIX | Similar a | Significado |
|---|---|---|
| [:upper:] | [A-Z] | Letras maiúsculas |
| [:lower:] | [a-z] | Letras minúsculas |
| [:alpha:] | [A-Za-z] | Letras maiúsculas e minúsculas |
| [:digit:] | [0-9] | Dígitos |
| [:xdigit:] | [0-9A-Fa-f] | Dígitos hexadecimais |
| [:alnum:] | [A-Za-z0-9] | Dígitos, letras maiúsculas e minúsculas |
| [:punct:] | Pontuação (todos os caracteres gráficos, exceto letras e dígitos) | |
| [:blank:] | [ \t] | Espaço e Tabulação |
| [:space:] | [ \t\n\r\f\v] | Caracteres de espaço em branco (vazio) |
| [:cntrl:] | Caracteres de controle | |
| [:graph:] | Caracteres gráficos (exclui espaços) | |
| [:print:] | [[:graph:] ] | Caracteres imprimíveis (inclui espaços) |
Exemplos práticos de cada função para expressão regular
Para facilitar o entendimento, vou demonstrar alguns exemplos de cada função para entenderem algumas aplicações úteis no dia a dia.
REGEXP_LIKE
Valida se a string bate com o padrão (Retorna BIT).
A Sintaxe é REGEXP_LIKE ( string_expression, pattern_expression [ , flags ] ), onde as valores para as flags são:
- i: Não diferencia maiúsculas de minúsculas (padrão false)
- m: Modo de várias linhas: “^” e “$” corresponder à linha de início/término, além do texto de início/término (padrão false)
- s: Permitir “.” correspondência “\n” (padrão false)
- c: Diferencia maiúsculas de minúsculas (padrão true)
Documentação oficial: REGEXP_LIKE
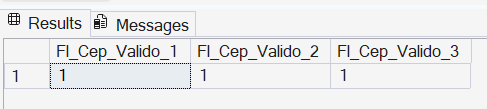
Exemplo 1: Validando máscaras de CEP
SELECT
-- Caso 1: Formato padrão 00000-000
CASE
WHEN REGEXP_LIKE('29090-270', '^[0-9]{5}-[0-9]{3}$') THEN 1
ELSE 0
END AS Fl_Cep_Valido_1,
-- Caso 2: Formato pontuado 00.000-000
-- Nota: O caractere '.' precisa de escape (\\ ou \) pois em Regex ele significa "qualquer caractere"
CASE
WHEN REGEXP_LIKE('29.090-270', '^[0-9]{2}\.[0-9]{3}-[0-9]{3}$') THEN 1
ELSE 0
END AS Fl_Cep_Valido_2,
-- Caso 3: Formato apenas números 00000000
CASE
WHEN REGEXP_LIKE('29090270', '^[0-9]{8}$') THEN 1
ELSE 0
END AS Fl_Cep_Valido_3
Exemplo 2: Validando se a máscara do CEP corresponde ao valor testado
-- Objetivo: Validar máscara de CEP no formato 99999-999.
SELECT
-- Caso 1: Válido (Atende exatamente ao padrão)
CASE
WHEN REGEXP_LIKE('29090-270', '^[0-9]{5}-[0-9]{3}$') THEN 1
ELSE 0
END AS Fl_Cep_Valido1,
-- Caso 2: Inválido (Possui ponto extra)
CASE
WHEN REGEXP_LIKE('29.090-270', '^[0-9]{5}-[0-9]{3}$') THEN 1
ELSE 0
END AS Fl_Cep_Valido2,
-- Caso 3: Inválido (Apenas números, sem o traço)
CASE
WHEN REGEXP_LIKE('29090270', '^[0-9]{5}-[0-9]{3}$') THEN 1
ELSE 0
END AS Fl_Cep_Valido3;
-- Dica: Se você não estiver no SQL Server 2022, a alternativa nativa é o LIKE:
-- WHERE coluna LIKE '[0-9][0-9][0-9][0-9][0-9]-[0-9][0-9][0-9]'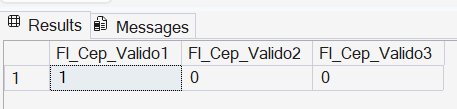
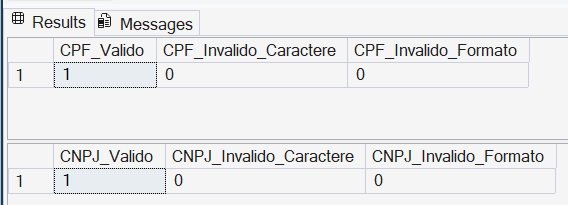
Exemplo 3: Validando CPF e CNPJ
-- 1. VALIDAÇÃO DE CPF (999.999.999-99)
SELECT
-- Exemplo 1: Formato Válido
CASE
WHEN REGEXP_LIKE('123.456.789-09', '^\d{3}\.\d{3}\.\d{3}\-\d{2}$') THEN 1
ELSE 0
END AS CPF_Valido,
-- Exemplo 2: Inválido (Letra X presente)
CASE
WHEN REGEXP_LIKE('12X.456.789-09', '^\d{3}\.\d{3}\.\d{3}\-\d{2}$') THEN 1
ELSE 0
END AS CPF_Invalido_Caractere,
-- Exemplo 3: Inválido (Sem máscara/apenas números)
CASE
WHEN REGEXP_LIKE('12345678909', '^\d{3}\.\d{3}\.\d{3}\-\d{2}$') THEN 1
ELSE 0
END AS CPF_Invalido_Formato;
-- 2. VALIDAÇÃO DE CNPJ (99.999.999/9999-99)
SELECT
-- Exemplo 1: Formato Válido
CASE
WHEN REGEXP_LIKE('12.345.678/1234-09', '^\d{2}\.\d{3}\.\d{3}\/\d{4}\-\d{2}$') THEN 1
ELSE 0
END AS CNPJ_Valido,
-- Exemplo 2: Inválido (Letra X presente)
CASE
WHEN REGEXP_LIKE('12.3X5.678/1234-09', '^\d{2}\.\d{3}\.\d{3}\/\d{4}\-\d{2}$') THEN 1
ELSE 0
END AS CNPJ_Invalido_Caractere,
-- Exemplo 3: Inválido (Sem máscara/apenas números)
CASE
WHEN REGEXP_LIKE('12345678123409', '^\d{2}\.\d{3}\.\d{3}\/\d{4}\-\d{2}$') THEN 1
ELSE 0
END AS CNPJ_Invalido_Formato;
Exemplo 4: Buscando palavras repetidas
Aqui encontramos uma barreira do dialeto RE2, que é a ausência de Backtracking. Com a função do SQLCLR, que utiliza o dialeto .NET, eu poderia utilizar expressões regulares para buscar palavras repetidas através da expressão \1, como no exemplo abaixo:
-- Identificando palavras repetidas
SELECT
CLR.dbo.fncRegex_Match('Essa frase frase contém palavras repetidas', '\b(\w+)\s+\1\b'),
CLR.dbo.fncRegex_Match('Essa frase NÃO contém palavras repetidas', '\b(\w+)\s+\1\b')
Se tentarmos adaptar esse código para expressão regular nativa, ficaria algo como:
-- Identificando palavras repetidas
SELECT
CASE WHEN REGEXP_LIKE('Essa frase frase contém palavras repetidas', '\b(\w+)\s+\1\b') THEN 1 ELSE 0 END,
CASE WHEN REGEXP_LIKE('Essa frase NÃO contém palavras repetidas', '\b(\w+)\s+\1\b') THEN 1 ELSE 0 END
E tentar fazer isso, vai gerar uma mensagem de erro como essa:
An invalid Pattern ‘\b(\w+)\s+\1\b’ was provided. Error ‘invalid escape sequence: \1’ occurred during evaluation of the Pattern.
Utilizando o dialeto RE2, não é possível fazer a mesma coisa utilizanos apenas expressão regular. Nesse caso, esbarramos em uma limitação técnica do motor de processamento das expressões regulares do SQL Server 2025 e Azure SQL Database.
Uma alternativa para resolver esse problema, é utilizando o STRING_SPLIT:
DECLARE @exemplo2 VARCHAR(2000) = 'nesse exemplo exemplo eu gostaria de eu demonstrar como identificar palavras palavras repetidas repetidas eu';
WITH Palavras AS (
-- O parâmetro '1' habilita a coluna [value] e [ordinal] (posição)
SELECT
value AS Palavra,
ordinal AS Posicao
FROM
STRING_SPLIT(@exemplo2, ' ', 1)
)
SELECT
p1.Palavra
FROM
Palavras p1
JOIN Palavras p2 ON p1.Posicao = p2.Posicao - 1 -- Compara com a próxima palavra
WHERE
p1.Palavra = p2.Palavra
AND p1.Palavra <> ''; -- Evita espaços vazios se houver espaços duplos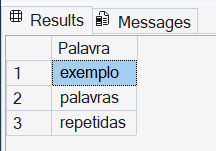
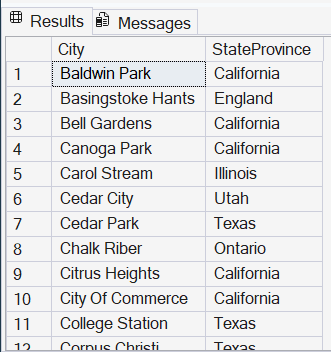
Exemplo 5: Busca nomes que contenham pelo menos um espaço entre caracteres alfabéticos
SELECT
City,
StateProvince
FROM
SalesLT.Address
WHERE
REGEXP_LIKE(City, '[[:alpha:]]+[[:space:]]+[[:alpha:]]+')
ORDER BY
City;
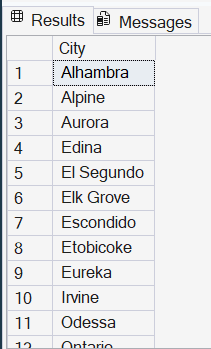
Exemplo 6: Cidades que começam ou terminam com vogais
SELECT DISTINCT
City
FROM
SalesLT.Address
WHERE
REGEXP_LIKE(City, '^[AEIOU].*[aeiou]$');
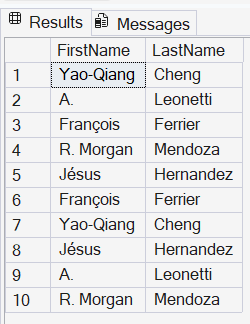
Exemplo 7: Pessoas cujo primeiro nome possuem acentos ou caracteres especiais
SELECT
FirstName,
LastName
FROM
SalesLT.Customer
WHERE
REGEXP_LIKE(FirstName, '[^a-zA-Z ]')
Exemplo 8: Case sensitive e insensitive
Por padrão, as expressões regulares são sempre case sensitive por padrão, mas você pode controlar esse comportamento usando flags.
Forçar consulta com case sensitive e pesquisa por “mountain”:
SELECT
Name,
ProductNumber
FROM
SalesLT.Product
WHERE
REGEXP_LIKE(Name, 'mountain', 'c'); -- 'c' força Case Sensitivity
Forçar consulta com case INsensitive e pesquisa por “mountain”:
SELECT
Name,
ProductNumber
FROM
SalesLT.Product
WHERE
REGEXP_LIKE(Name, 'mountain', 'i'); -- 'i' força Case IN-Sensitivity
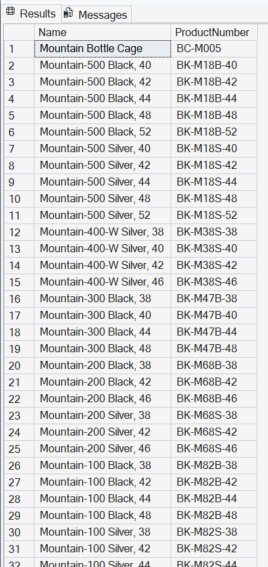
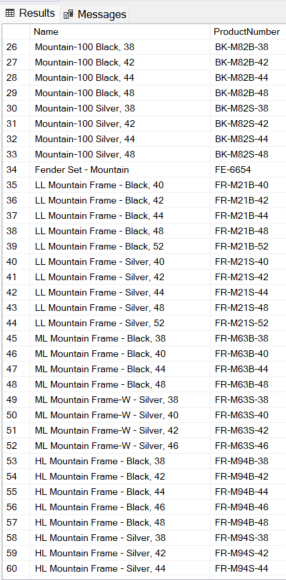
Vale lembrar que o REGEXP_LIKE pesquisa em qualquer trecho da string, não apenas no começo:
REGEXP_INSTR
Retorna a posição inicial ou final da subcadeia de caracteres correspondente, dependendo do valor do argumento return_option.
A sintaxe é REGEXP_INSTR ( string_expression, pattern_expression [ , start [ , occurrence [ , return_option [ , flags [ , group ] ] ] ] ] ).
Documentação oficial: REGEXP_INSTR
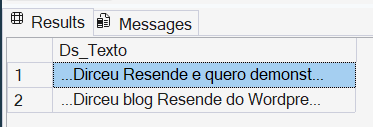
Exemplo 1: Recuperar trechos onde a palavra “Dirceu” aparece no texto
DECLARE @exemplo1 VARCHAR(2000) = 'Olá pessoal! Meu nome é Dirceu Resende e quero demonstrar como o Regexp é útil nesse artigo do Dirceu blog Resende do Wordpress';
WITH Trechos AS (
-- Localiza a primeira ocorrência
SELECT
REGEXP_INSTR(@exemplo1, 'Dirceu', 1, 1) AS Posicao,
1 AS Ocorrencia
UNION ALL
-- Busca as próximas ocorrências recursivamente
SELECT
REGEXP_INSTR(@exemplo1, 'Dirceu', Posicao + 1, 1),
Ocorrencia + 1
FROM Trechos
WHERE REGEXP_INSTR(@exemplo1, 'Dirceu', Posicao + 1, 1) > 0
)
SELECT
-- Como não temos SUBSTR nativo com Regex, usamos SUBSTRING tradicional
-- Pegando "Dirceu" + 25 caracteres para simular o contexto dos próximos termos
'...' + SUBSTRING(@exemplo1, Posicao, 30) + '...' AS Ds_Texto
FROM Trechos;
Exemplo 2: Localizar o número no final da string composto por 2 algarismos (Ex: “42”, “58”, “70”)
-- O CHARINDEX não consegue achar "a posição do primeiro número que tenha exatamente 2 dígitos".
-- Ele acharia o '2' em '2005' ou o '1' em 'Road-150'.
SELECT
[Name],
REGEXP_INSTR([Name], '\b[0-9]{2}\b') AS Pos_Dimensao_Exata
FROM
SalesLT.[Product]
WHERE
REGEXP_INSTR([Name], '\b[0-9]{2}\b') > 0
ORDER BY
NEWID()
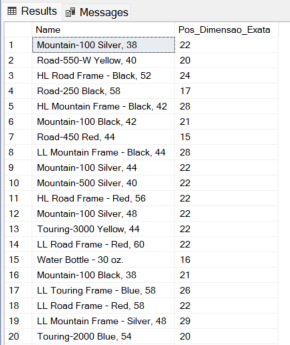
Exemplo 3: Posição de múltiplos sufixos em endereços
-- Queremos a posição de 'Drive', 'Court' ou 'Avenue', mas apenas se forem a última palavra.
-- Fazer isso com CHARINDEX exige inverter a string ou cálculos complexos de LEN.
SELECT
AddressLine1,
REGEXP_INSTR(AddressLine1, '\b(Drive|Court|Avenue|St|St\.)\b$') AS Pos_Sufixo_Final
FROM
SalesLT.Address
WHERE
REGEXP_INSTR(AddressLine1, '\b(Drive|Court|Avenue|St|St\.)\b$') > 0;
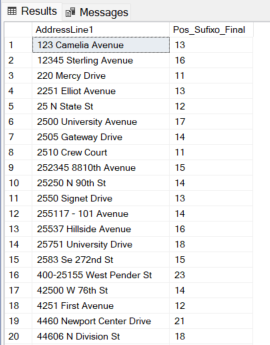
Exemplo 4: Recuperar o nome da rua e ignorar o número
-- Localiza a posição da primeira LETRA que aparece após uma sequência de NÚMEROS.
-- Essencial para separar '1234 Main St' em '1234' e 'Main St'.
SELECT
AddressLine1,
REGEXP_INSTR(AddressLine1, '[a-zA-Z]', 1, 1) AS Pos_Inicio_Nome_Rua,
SUBSTRING(AddressLine1, REGEXP_INSTR(AddressLine1, '[a-zA-Z]', 1, 1), LEN(AddressLine1)) AS NomeRua
FROM
SalesLT.Address
WHERE
REGEXP_INSTR(AddressLine1, '^[0-9]+') > 0;
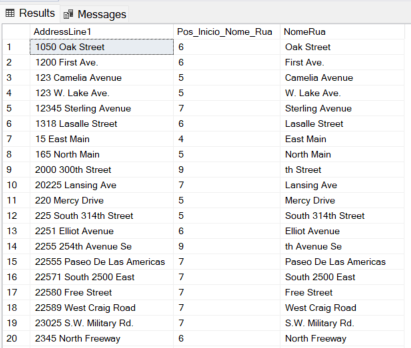
Exemplo 5: Identificando apartamentos ou unidades
-- Localiza a posição de qualquer marcador de unidade (Apt, Unit, #, Ste)
-- O CHARINDEX precisaria de 4 buscas separadas com OR.
SELECT
AddressLine1,
REGEXP_INSTR(AddressLine1, '\b(Apt|Unit|#|Ste|Suite)\b', 1, 1, 0, 'i') AS Pos_Marcador_Unidade
FROM
SalesLT.Address
WHERE
REGEXP_INSTR(AddressLine1, '\b(Apt|Unit|#|Ste|Suite)\b', 1, 1, 0, 'i') > 0;
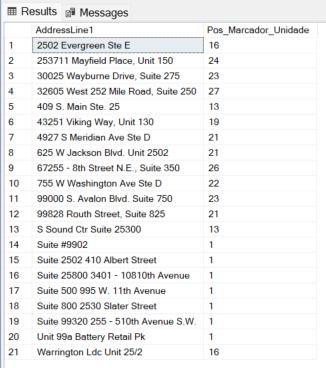
REGEXP_COUNT
Conta o número de vezes que um padrão de expressão regular é correspondido em uma cadeia de caracteres.
A sintaxe é REGEXP_COUNT ( string_expression, pattern_expression [ , start [ , flags ] ] ), onde as valores para as flags são:
- i: Não diferencia maiúsculas de minúsculas (padrão false)
- m: Modo de várias linhas: “^” e “$” corresponder à linha de início/término, além do texto de início/término (padrão false)
- s: Permitir “.” correspondência “\n” (padrão false)
- c: Diferencia maiúsculas de minúsculas (padrão true)
Documentação oficial: https://learn.microsoft.com/pt-br/sql/t-sql/functions/regexp-count-transact-sql
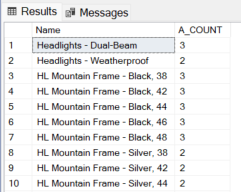
Exemplo 1: Conte quantas vezes a letra a aparece em cada nome do produto.
SELECT
Name,
REGEXP_COUNT( Name, 'a' ) AS A_COUNT
FROM
SalesLT.Product
WHERE
REGEXP_COUNT( Name, 'a' ) > 1;
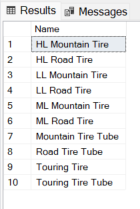
Exemplo 2: Retorna os produtos que terminam com “tire” ou “ube”, ignorando maiúsculo e minúsculo.
SELECT
Name
FROM
SalesLT.Product
WHERE
REGEXP_COUNT(Name, 'tire|ube$', 1, 'i') > 0;
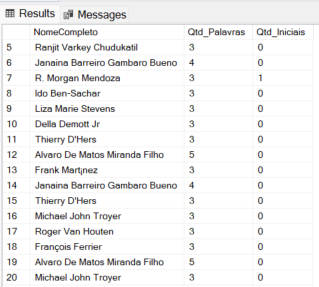
Exemplo 3: Contando quantidade de palavras e nomes com iniciais
SELECT
FirstName + ' ' + LastName AS NomeCompleto,
REGEXP_COUNT( FirstName + ' ' + LastName, '\w+' ) AS Qtd_Palavras,
-- Conta quantas iniciais seguidas de ponto existem (Ex: "J. R. R. Tolkien")
REGEXP_COUNT( FirstName + ' ' + LastName, '\b[A-Z]\.' ) AS Qtd_Iniciais
FROM
SalesLT.Customer
WHERE
REGEXP_COUNT( FirstName + ' ' + LastName, '\w+' ) > 2
REGEXP_REPLACE
Retorna uma string modificada, em que a ocorrência do padrão de expressão regular foi encontrada. Se nenhuma correspondência for encontrada, a função retornará a string original.
A sintaxe é REGEXP_REPLACE( string_expression, pattern_expression [ , string_replacement [ , start [ , occurrence [ , flags ] ] ] ] ), onde as valores para as flags são:
- i: Não diferencia maiúsculas de minúsculas (padrão false)
- m: Modo de várias linhas: “^” e “$” corresponder à linha de início/término, além do texto de início/término (padrão false)
- s: Permitir “.” correspondência “\n” (padrão false)
- c: Diferencia maiúsculas de minúsculas (padrão true)
Documentação oficial: https://learn.microsoft.com/pt-br/sql/t-sql/functions/regexp-replace-transact-sql
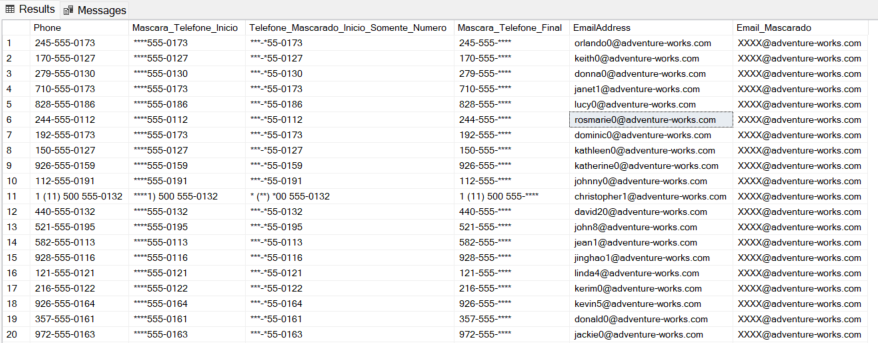
Exemplo 1: Mascarando telefones e emails
SELECT
Phone,
-- Mascarar exatamente os primeiros 4 caracteres
-- ^.{4} -> O início da string (^) seguido de qualquer caractere (.) repedido 4 vezes {4}
REGEXP_REPLACE(Phone, '^.{4}', '****') AS Mascara_Telefone_Inicio,
-- Mascarar exatamente os primeiros 4 NÚMEROS, mantendo formatação
REGEXP_REPLACE(
REGEXP_REPLACE(
REGEXP_REPLACE(
REGEXP_REPLACE(Phone, '\d', '*', 1, 1), -- Mascara o 1º número
'\d', '*', 1, 1), -- Mascara o novo 1º número
'\d', '*', 1, 1), -- E assim por diante...
'\d', '*', 1, 1) AS Telefone_Mascarado_Inicio_Somente_Numero,
REGEXP_REPLACE(Phone, '\d{4}$', '****') AS Mascara_Telefone_Final,
EmailAddress,
REGEXP_REPLACE(EmailAddress, '^[^@]+', 'XXXX') AS Email_Mascarado
FROM
SalesLT.Customer
Exemplo 2: Retornar apenas os números de uma string
-- Remove parênteses, traços e espaços de uma só vez para deixar apenas os dígitos.
-- Tente fazer isso com REPLACE comum e veja o tamanho do código!
SELECT
Phone,
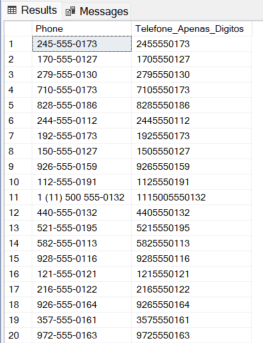
REGEXP_REPLACE(Phone, '[^0-9]', '') AS Telefone_Apenas_Digitos
FROM
SalesLT.Customer
Exemplo 3: Substituindo várias expressões para normalizar um nome
-- Exemplo 2: Substituindo múltiplos "ruídos" por um nome de categoria único
DECLARE @Descricao VARCHAR(100) = 'Este item é uma Bicycle, também chamada de Cycle ou Velo';
SELECT
@Descricao AS Original,
-- Substitui qualquer uma das palavras no grupo por 'Bike'
REGEXP_REPLACE(@Descricao, '\b(Bicycle|Cycle|Velo)\b', 'Bike', 1, 0, 'i') AS Descricao_Limpa;

Exemplo 4: Transformações diversas
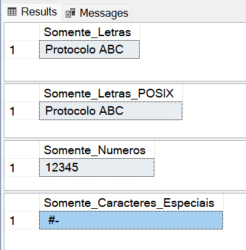
-- 1. REGEXP_REPLACE substituirá tudo que NÃO é letra ([^A-Za-z]) por nada ('')
SELECT REGEXP_REPLACE('Protocolo #12345-ABC', '[^A-Za-z ]', '') AS Somente_Letras
-- 2. Usando classes POSIX para maior elegância e suporte a acentos (se necessário)
SELECT REGEXP_REPLACE('Protocolo #12345-ABC', '[^[:alpha:] ]', '') AS Somente_Letras_POSIX
-- 3. Retornando apenas números
SELECT REGEXP_REPLACE('Protocolo #12345-ABC', '[^0-9]', '') AS Somente_Numeros
-- 4. Retornando apenas os caracteres especiais
SELECT REGEXP_REPLACE('Protocolo #12345-ABC', '[[:alnum:]]', '') AS Somente_Caracteres_Especiais
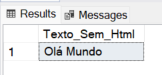
Exemplo 5: Retornar texto sem as tags HTML
SELECT
REGEXP_REPLACE('<div><p>Olá</p> <span>Mundo</span></div>', '<[^>]+>', '') AS Texto_Sem_Html
REGEXP_SUBSTR
Retorna uma ocorrência de uma string que corresponde ao padrão de expressão regular. Se nenhuma correspondência for encontrada, ela retornará NULL.
A sintaxe é REGEXP_SUBSTR( string_expression, pattern_expression [ , string_replacement [ , start [ , occurrence [ , flags ] ] ] ] ), onde as valores para as flags são:
- i: Não diferencia maiúsculas de minúsculas (padrão false)
- m: Modo de várias linhas: “^” e “$” corresponder à linha de início/término, além do texto de início/término (padrão false)
- s: Permitir “.” correspondência “\n” (padrão false)
- c: Diferencia maiúsculas de minúsculas (padrão true)
Documentação oficial: https://learn.microsoft.com/pt-br/sql/t-sql/functions/regexp-substr-transact-sql
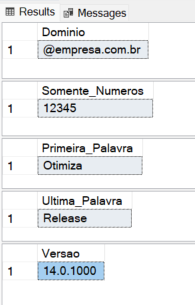
Exemplo 1: Recuperar partes de uma string
-- 1. Extraindo o domínio de um e-mail (Tudo após o @)
DECLARE @email VARCHAR(100) = '[email protected]'
SELECT REGEXP_SUBSTR(@email, '@[a-z0-9.-]+') AS Dominio
-- 2. Extraindo apenas os números de uma string suja
SELECT REGEXP_SUBSTR('Protocolo #12345-ABC', '[0-9]+') AS Somente_Numeros
-- 3. Extraindo a primeira palavra de uma frase
SELECT REGEXP_SUBSTR('Otimização de Performance SQL', '^\w+') AS Primeira_Palavra
-- 4. Extraindo a última palavra de uma frase
SELECT REGEXP_SUBSTR('SQL Server 2022 Release', '\w+$') AS Ultima_Palavra
-- 5. Extraindo versão de software (Padrão X.X.X)
DECLARE @log VARCHAR(100) = 'Build version 14.0.1000 patch applied'
SELECT REGEXP_SUBSTR(@log, '[0-9]+\.[0-9]+\.[0-9]+') AS Versao
Resultado:
Exemplo 2: Retornar um número formado por 2 algarismos na string
SELECT
Name,
REGEXP_SUBSTR(Name, '\b[0-9]{2}\b') AS Tamanho_Extraido
FROM
SalesLT.Product
WHERE
REGEXP_LIKE(Name, '\b[0-9]{2}\b')
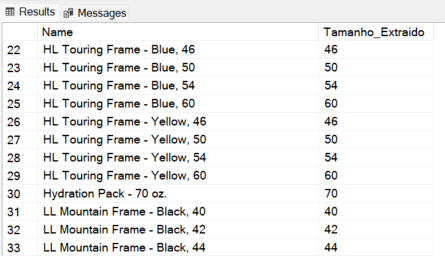
Exemplo 3: Extraindo apenas o nome do Usuário do Email
-- Usamos o 6º parâmetro para retornar apenas o que está dentro do primeiro parêntese
SELECT
EmailAddress,
REGEXP_SUBSTR(EmailAddress, '^([^@]+)', 1, 1, 'i', 1) AS Usuario_Email
FROM
SalesLT.Customer;
Diferente do SUBSTRING tradicional, que pode retornar uma string vazia ou erro se os índices estiverem errados, o REGEXP_SUBSTR retornará NULL se o padrão não for encontrado. Use isso a seu favor em suas queries de limpeza: WHERE REGEXP_SUBSTR(coluna, padrao) IS NOT NULL
Isso garante que sua extração seja limpa e que você não tente realizar operações matemáticas ou de JOIN em valores inexistentes.
REGEXP_MATCHES
Retorna uma tabela de substrings capturadas que correspondem a um padrão de expressão regular a uma string. Se nenhuma correspondência for encontrada, a função não retornará nenhuma linha.
A sintaxe é REGEXP_MATCHES( string_expression, pattern_expression [ , flags ] ), onde as valores para as flags são:
- i: Não diferencia maiúsculas de minúsculas (padrão false)
- m: Modo de várias linhas: “^” e “$” corresponder à linha de início/término, além do texto de início/término (padrão false)
- s: Permitir “.” correspondência “\n” (padrão false)
- c: Diferencia maiúsculas de minúsculas (padrão true)
Documentação oficial: https://learn.microsoft.com/pt-br/sql/t-sql/functions/regexp-matches-transact-sql
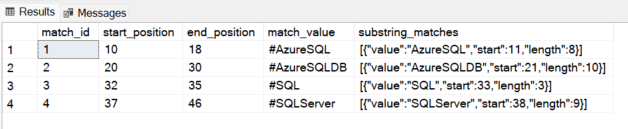
Exemplo 1: Retornando uma tabela com as hashtags de uma frase.
-- Opção 1: Especificando manualmente o conjunto de caracteres
SELECT * FROM REGEXP_MATCHES ('Learning #AzureSQL #AzureSQLDB #SQL #SQLServer', '#([A-Za-z0-9_]+)');
-- Opção 2: Utilizando o padrão \w+ para capturar a palavra após o #
SELECT * FROM REGEXP_MATCHES('Learning #AzureSQL #AzureSQLDB #SQL #SQLServer', '#(\w+)');
Exemplo 2: Retornando uma tabela de protocolos na string
-- 2. Localizando todos os protocolos (Formato: 3 letras - 4 números)
-- Ex: ABC-1234, XYZ-9999
SELECT * FROM REGEXP_MATCHES('Protocolos: ABC-1234 e XYZ-9999', '[A-Z]{3}-[0-9]{4}');

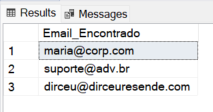
Exemplo 3: Recuperando todos os emails de uma string
SELECT
m.match_value AS Email_Encontrado
FROM (VALUES ('Contatos: [email protected]; [email protected]. Email do Dirceu: [email protected]')) AS t(Texto)
CROSS APPLY REGEXP_MATCHES(t.Texto, '[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,}', 'i') m;
Exemplo 4: Consultas variadas
-- 1. IDENTIFICANDO TODOS OS VALORES MONETÁRIOS (R$, $)
SELECT
m.match_value AS Preco_Detectado
FROM (VALUES ('Item A: R$ 150,00 | Item B: $ 20.00')) AS t(Texto)
CROSS APPLY REGEXP_MATCHES(t.Texto, '(R\$|\$)\s?[0-9,.]+') m;
-- 2. EXTRAINDO TODAS AS TAGS HTML (Nome da Tag)
-- Usamos grupos de captura para pegar apenas o que está dentro de < >
SELECT
m.match_value AS Tag_Nome
FROM (VALUES ('<div><p>Texto</p><span>Item</span></div>')) AS t(Html)
CROSS APPLY REGEXP_MATCHES(t.Html, '<([a-z1-6]+)>') m;
-- 3. LOCALIZANDO TODAS AS DATAS EM FORMATOS VARIADOS
SELECT
m.match_value AS Data_Encontrada
FROM (VALUES ('Início: 29/12/2025 - Fim: 2026-01-15')) AS t(Texto)
CROSS APPLY REGEXP_MATCHES(t.Texto, '\b(\d{2}/\d{2}/\d{4}|\d{4}-\d{2}-\d{2})\b') m;
-- 4. EXTRAINDO MENÇÕES DE USUÁRIOS (@usuario)
SELECT
m.match_value AS Usuario
FROM (VALUES ('Relatório enviado por @dirceu e revisado por @resende')) AS t(Msg)
CROSS APPLY REGEXP_MATCHES(t.Msg, '@(\w+)') m;
-- 5. ISOLANDO ENDEREÇOS IP DE UM LOG ESCALAR
DECLARE @log VARCHAR(100) = 'Erro de rede nos IPs 192.168.0.1 e 10.0.0.254';
SELECT match_value FROM REGEXP_MATCHES(@log, '\b(?:\d{1,3}\.){3}\d{1,3}\b');
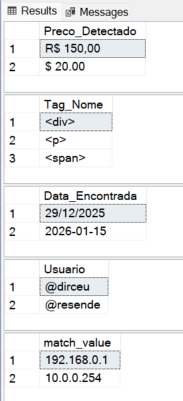
Exemplo 5: Extrai as cores a partir de uma string
SELECT
p.ProductID,
p.Name AS NomeOriginal,
m.match_value AS CorExtraida
FROM
SalesLT.Product p
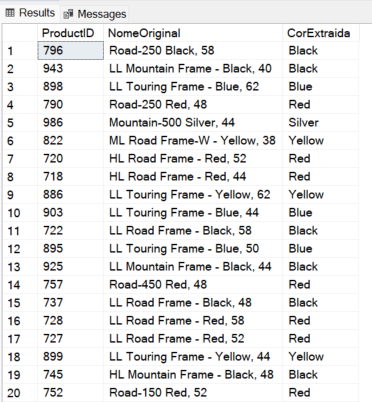
CROSS APPLY REGEXP_MATCHES(p.Name, '\b(Black|Silver|Red|Blue|Yellow|White|Grey|Multi)\b', 'i') m;
REGEXP_SPLIT_TO_TABLE
Retorna uma tabela de strings dividida, delimitada pelo padrão regex. Se não houver correspondência com o padrão, a função retornará a string.
A sintaxe é REGEXP_SPLIT_TO_TABLE( string_expression, pattern_expression [ , flags ] ), onde as valores para as flags são:
- i: Não diferencia maiúsculas de minúsculas (padrão false)
- m: Modo de várias linhas: “^” e “$” corresponder à linha de início/término, além do texto de início/término (padrão false)
- s: Permitir “.” correspondência “\n” (padrão false)
- c: Diferencia maiúsculas de minúsculas (padrão true)
Documentação oficial: https://learn.microsoft.com/pt-br/sql/t-sql/functions/regexp-split-to-table-transact-sql
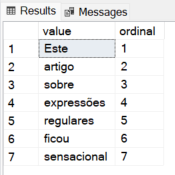
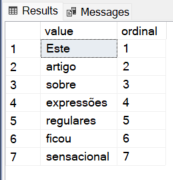
Exemplo 1: Retornando uma tabela com cada palavra do texto como uma linha
SELECT *
FROM REGEXP_SPLIT_TO_TABLE ('Este artigo sobre expressões regulares ficou sensacional', '\s+');
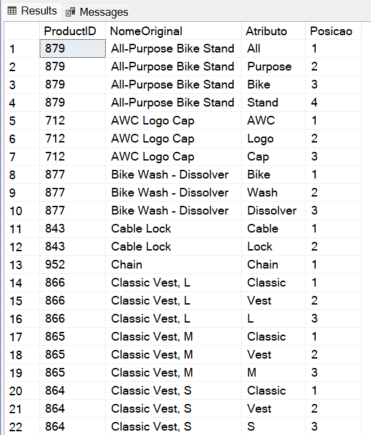
Exemplo 2: Quebra o texto em várias linhas com múltiplos delimitadores
SELECT
p.ProductID,
p.Name AS NomeOriginal,
s.value AS Atributo,
s.ordinal AS Posicao
FROM
SalesLT.Product p
CROSS APPLY REGEXP_SPLIT_TO_TABLE(p.Name, '[- ,/]+') s;
Essa função se parece bastante com a STRING_SPLIT:
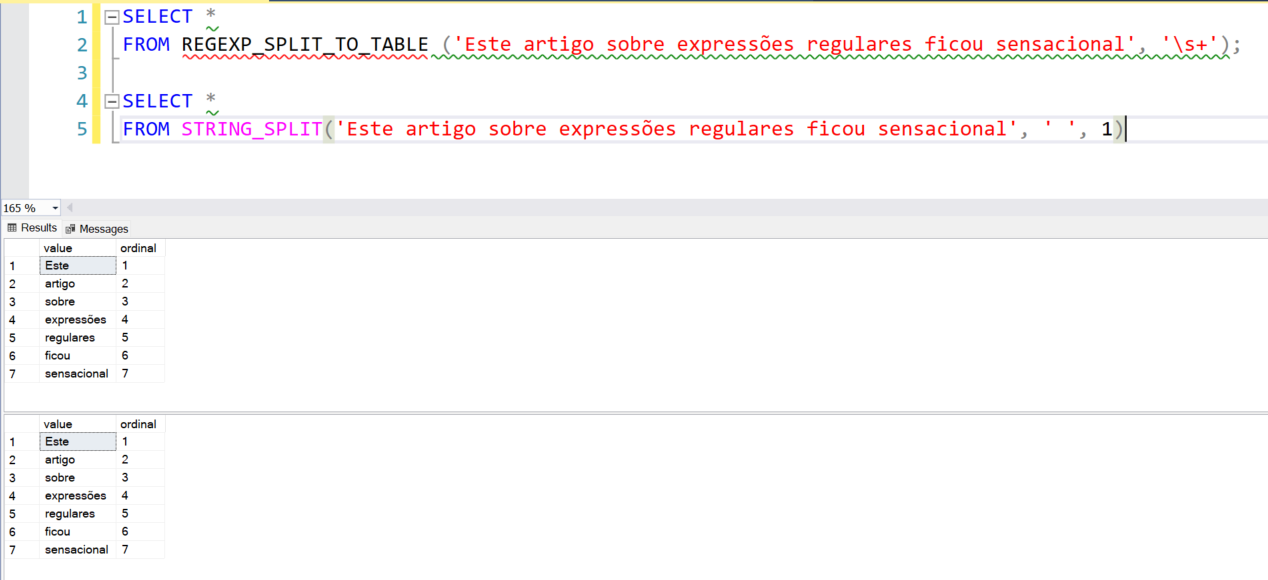
Entretanto, ela tem uma diferença sutil, que é o fato da função STRING_SPLIT aceitar somente 1 caractere separador, enquanto a REGEXP_SPLIT_TO_TABLE não tem esse limite.
Consigo separar minha string utilizando 3 caracteres como separador (-=-):
SELECT *
FROM REGEXP_SPLIT_TO_TABLE ('Este-=-artigo-=-sobre-=-expressões-=-regulares-=-ficou-=-sensacional', '-=-');
Mas ao tentar fazer a mesma coisa utilizando o STRING_SPLIT, nos deparamos com essa mensagem de erro:
SELECT *
FROM STRING_SPLIT('Este-=-artigo-=-sobre-=-expressões-=-regulares-=-ficou-=-sensacional', '-=-', 1)
Procedure expects parameter ‘separator’ of type ‘nchar(1)/nvarchar(1)’.
Comparativo: Nativo vs SQLCLR
Agora chegamos no ponto que todos queriam saber: Vale a pena migrar o que já temos em SQLCLR para as funções nativas?
Sintaxe e Manutenção
No SQLCLR, cada função precisava ser mapeada para um método C#. Se você precisasse de um comportamento novo, precisava recompilar a DLL, fazer o deploy no servidor (muitas vezes dependendo de privilégios de sysadmin) e torcer para não haver problemas de versão do .NET Framework. Com as funções nativas, a sintaxe é padrão T-SQL. Qualquer desenvolvedor SQL consegue ler e entender o que está acontecendo sem precisar abrir um projeto no Visual Studio.
Performance e Resource Wait Types
Quando utilizamos SQLCLR, o SQL Server precisa gerenciar o AppDomain e realizar o “Marshaling” de dados entre o motor relacional e a CLR. Isso gera esperas de processamento que muitas vezes se traduzem em CLR_AUTO_EVENT ou CLR_MANUAL_EVENT.
Com as funções nativas:
- CPU: O processamento ocorre dentro do próprio motor de execução do SQL, permitindo melhor paralelismo.
- Memória: Não há necessidade de reservar memória adicional para o Garbage Collector da CLR.
- IOPS: Embora o impacto direto em IO seja menor, a eficiência na leitura de colunas LOB (VARCHAR(MAX)) com Regex nativo é superior por não exigir a cópia do dado para o ambiente gerenciado.
Um ponto de atenção: Tanto o SQLCLR quanto o Regex Nativo não são SARGABLE. Ou seja, se você colocar um WHERE REGEXP_LIKE(…) em uma coluna, o SQL Server provavelmente fará um Index Scan ou Table Scan. O regex é processado linha a linha.
Além disso, ao usar REGEXP_MATCHES ou REGEXP_SPLIT_TO_TABLE, o SQL Server não precisa realizar o “Marshaling” (cópia de dados) para o ambiente .NET do SQLCLR e isso melhora significamente a performance da função nativa.
Comparação de performance entre SQLCLR e as funções nativas:

Se quiser criar as funções no seu ambiente, é só executar o script abaixo:
CREATE ASSEMBLY [Regexp]
FROM 0x4D5A90000300000004000000FFFF0000B800000000000000400000000000000000000000000000000000000000000000000000000000000000000000800000000E1FBA0E00B409CD21B8014CCD21546869732070726F6772616D2063616E6E6F742062652072756E20696E20444F53206D6F64652E0D0D0A2400000000000000504500004C0103008C57115B0000000000000000E00022200B013000000E00000006000000000000BE2C00000020000000400000000000100020000000020000040000000000000006000000000000000080000000020000000000000300608500001000001000000000100000100000000000001000000000000000000000006C2C00004F00000000400000A002000000000000000000000000000000000000006000000C000000342B00001C0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000200000080000000000000000000000082000004800000000000000000000002E74657874000000C40C000000200000000E000000020000000000000000000000000000200000602E72737263000000A0020000004000000004000000100000000000000000000000000000400000402E72656C6F6300000C0000000060000000020000001400000000000000000000000000004000004200000000000000000000000000000000A02C00000000000048000000020005004C220000E808000001000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001B3002006A00000001000011000F00280500000A2D090F01280500000A2B01170A062C087E0600000A0B2B4800000F00280700000A0F01280700000A280800000A0C086F0900000A2D077E0600000A2B16086F0A00000A166F0B00000A6F0C00000A280D00000A0BDE0A0D007E0600000A0BDE00072A000001100000000021003D5E000A090000011B3003005900000002000011000F00280500000A2D120F01280500000A2D090F02280500000A2B01170A062C087E0600000A0B2B2E00000F00280700000A0F01280700000A0F02280700000A280E00000A280D00000A0BDE0A0C007E0600000A0BDE00072A0000000110000000002A00234D000A090000011B3003008D0000000300001100730F00000A0A02281000000A2D0803281000000A2B01170D092C050613042B69170B020316281100000A0C00086F1200000A13052B2D11056F1300000A1306000607281400000A11066F1500000A280D00000A73060000066F1600000A260717580B0011056F1700000A2DCADE1611057510000001130711072C0811076F1800000A00DC0613042B0011042A00000001100000020035003A6F001600000000133002002100000004000011000274030000020A03067B01000004811100000104067B0200000481070000012A2202281900000A002A5E02281900000A000002037D0100000402047D020000042A000042534A4201000100000000000C00000076342E302E33303331390000000005006C000000C8020000237E0000340300002403000023537472696E6773000000005806000004000000235553005C0600001000000023475549440000006C0600007C02000023426C6F620000000000000002000001571502000902000000FA01330016000001000000170000000300000002000000060000000C00000019000000060000000400000001000000030000000100000000005A010100000000000600F00024020600100124020600C70011020F00440200000600DB0279010A00DB00C8010A0038015B020E00540170020600A00179010A007F00C8010A007900C80106009F008F020600FA028F020E00800170020600F1018F020600AB0079010A0001005B020E000D0370020E00BB0170020E00900170020E00B70070020600440179010E00B7027002000000000A00000000000100010001001000A2020000150001000100030010006E000000150001000600060013008D000600AA011E0050200000000096004B0191000100D8200000000096008E009A00030050210000000096005C00A5000600FC210000000094004800AC00080029220000000086180B0206000B0032220000000086180B02B7000B0000000100AA0100000200240000000100AA0100000200240000000300E30100000100AA01000002002400000001006B00020002001C0002000300B301000001001C0000000200B30109000B02010011000B02060019000B020A0031000B020600390065011A0039006B011E0039002E0122009100540126009900CF021A004100C4022D00A10070013200A9002E0122003900E202380091009700460069000B020600B10013035D009100530262007100FD016B007900EE0270008900E2027400290042012200690044007A00790004031A008100BF00060029000B02060020002300F0002E000B00BF002E001300C8002E001B00E70040002300F00060002300F50010003E004D007F00048000000000000000000000000000000000C101000004000000000000000000000084003B000000000004000000000000000000000084002F000000000004000000000000000000000084007901000000000300020000000053716C496E743332003C4D6F64756C653E004E725F4C696E6861006E724C696E68610044735F4D6173636172610053797374656D2E44617461006D73636F726C6962004164640046696C6C526F775F5265676578705F46696E6400666E635265676578705F46696E64006F626A52656765787046696E640053797374656D446174614163636573734B696E6400666E6352656765785F5265706C6163650049456E756D657261626C650049446973706F7361626C65004361707475726500446973706F73650044656275676761626C654174747269627574650053716C46756E6374696F6E41747472696275746500436F6D70696C6174696F6E52656C61786174696F6E734174747269627574650052756E74696D65436F6D7061746962696C697479417474726962757465006765745F56616C75650053716C537472696E6700546F537472696E6700666E6352656765785F4D61746368005265676578702E646C6C006765745F49734E756C6C006765745F4974656D0053797374656D004D61746368436F6C6C656374696F6E0047726F7570436F6C6C656374696F6E00457863657074696F6E0044735F546578746F006473546578746F0047726F757000526567657870004D6963726F736F66742E53716C5365727665722E5365727665720044735F537562737469747569720049456E756D657261746F7200476574456E756D657261746F72002E63746F720053797374656D2E446961676E6F73746963730053797374656D2E52756E74696D652E436F6D70696C6572536572766963657300446562756767696E674D6F646573004D6174636865730053797374656D2E446174612E53716C54797065730053797374656D2E546578742E526567756C617245787072657373696F6E730053797374656D2E436F6C6C656374696F6E730055736572446566696E656446756E6374696F6E730052656765784F7074696F6E73006765745F47726F757073006765745F53756363657373004F626A656374006F705F496D706C69636974006765745F43757272656E740041727261794C697374004D6F76654E6578740052656765780049734E756C6C4F72456D70747900000000000000000C14EAF7F46A2245B903BE327055CEBE0004200101080320000105200101111109070402111D12211225032000020306111D0320000E06000212210E0E0420001251052001124D08050001111D0E07070302111D12250600030E0E0E0E0F07081235081239021231123D1C1241040001020E08000312390E0E115D042000123D0320001C050001114508042001081C040701120C08B77A5C561934E08903061145080002111D111D111D0A0003111D111D111D111D06000212310E0E0A0003011C10114510111D072002011145111D0801000800000000001E01000100540216577261704E6F6E457863657074696F6E5468726F7773010801000701000000000401000000818501000400540E1146696C6C526F774D6574686F644E616D651346696C6C526F775F5265676578705F46696E64540E0F5461626C65446566696E6974696F6E244E725F4C696E686120494E542C2044735F546578746F204E56415243484152284D4158295455794D6963726F736F66742E53716C5365727665722E5365727665722E446174614163636573734B696E642C2053797374656D2E446174612C2056657273696F6E3D342E302E302E302C2043756C747572653D6E65757472616C2C205075626C69634B6579546F6B656E3D623737613563353631393334653038390A446174614163636573730100000054557F4D6963726F736F66742E53716C5365727665722E5365727665722E53797374656D446174614163636573734B696E642C2053797374656D2E446174612C2056657273696F6E3D342E302E302E302C2043756C747572653D6E65757472616C2C205075626C69634B6579546F6B656E3D623737613563353631393334653038391053797374656D4461746141636365737301000000000000008C57115B00000000020000001C010000502B0000500D000052534453A6F053CD17E4E94A923D821619E3D25F01000000433A5C55736572735C646966696C5C446F63756D656E74735C56697375616C2053747564696F20323031375C50726F6A656374735C5265676578705C5265676578705C6F626A5C44656275675C5265676578702E7064620000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000942C00000000000000000000AE2C0000002000000000000000000000000000000000000000000000A02C0000000000000000000000005F436F72446C6C4D61696E006D73636F7265652E646C6C0000000000FF25002000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000100100000001800008000000000000000000000000000000100010000003000008000000000000000000000000000000100000000004800000058400000440200000000000000000000440234000000560053005F00560045005200530049004F004E005F0049004E0046004F0000000000BD04EFFE00000100000000000000000000000000000000003F000000000000000400000002000000000000000000000000000000440000000100560061007200460069006C00650049006E0066006F00000000002400040000005400720061006E0073006C006100740069006F006E00000000000000B004A4010000010053007400720069006E006700460069006C00650049006E0066006F0000008001000001003000300030003000300034006200300000002C0002000100460069006C0065004400650073006300720069007000740069006F006E000000000020000000300008000100460069006C006500560065007200730069006F006E000000000030002E0030002E0030002E003000000036000B00010049006E007400650072006E0061006C004E0061006D00650000005200650067006500780070002E0064006C006C00000000002800020001004C006500670061006C0043006F0070007900720069006700680074000000200000003E000B0001004F0072006900670069006E0061006C00460069006C0065006E0061006D00650000005200650067006500780070002E0064006C006C0000000000340008000100500072006F006400750063007400560065007200730069006F006E00000030002E0030002E0030002E003000000038000800010041007300730065006D0062006C0079002000560065007200730069006F006E00000030002E0030002E0030002E00300000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000002000000C000000C03C00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
WITH PERMISSION_SET = SAFE
GO
CREATE FUNCTION [dbo].[fncRegex_Match] (@Ds_Texto [nvarchar](MAX), @Ds_Mascara [nvarchar](MAX))
RETURNS [nvarchar](MAX)
AS EXTERNAL NAME [Regexp].[UserDefinedFunctions].[fncRegex_Match];
GO
CREATE FUNCTION [dbo].[fncRegex_Replace] (@Ds_Texto [nvarchar](MAX), @Ds_Mascara [nvarchar](MAX), @Ds_Substituir [nvarchar](MAX))
RETURNS [nvarchar](MAX)
AS EXTERNAL NAME [Regexp].[UserDefinedFunctions].[fncRegex_Replace];
GO
CREATE FUNCTION [dbo].[fncRegexp_Find](@Ds_Texto [nvarchar](max), @Ds_Mascara [nvarchar](max))
RETURNS TABLE (
[Nr_Linha] [int] NULL,
[Ds_Texto] [nvarchar](max) NULL
) WITH EXECUTE AS CALLER
AS
EXTERNAL NAME [Regexp].[UserDefinedFunctions].[fncRegexp_Find]
GO
Por exemplo: WHERE [Coluna] LIKE ‘192%’ AND REGEXP_LIKE([Coluna], ‘padrão_complexo’). O LIKE simples faz o primeiro filtro usando índice, e o Regex processa apenas o que sobrar.
Para demonstrar que o LIKE é mais rápido que REGEXP, mesmo utilizando LIKE ‘%texto%’, podemos utilizar o script abaixo:
SELECT
Name,
ProductNumber
FROM
SalesLT.Product
WHERE
REGEXP_LIKE(Name, 'mountain', 'i'); -- 'c' força Case In-Sensitivity
SELECT
Name,
ProductNumber
FROM
SalesLT.Product
WHERE
Name LIKE '%mountain%' collate SQL_Latin1_General_CP1_CI_AI -- Forçar ser Case In-Sensitivity
Resultado:

Segurança
Este é o maior ganho. Muitas instâncias de Azure SQL Managed Instance ou ambientes On-Premise extremamente travados não permitem a execução de clr enabled. Com as funções nativas, essa barreira desaparece. Você tem o poder do Regex mantendo a instância em SURFACE AREA CONFIGURATION segura.
Conclusão
A introdução das funções de Regex nativas no SQL Server 2025 é um marco de maturidade para a plataforma. Elas eliminam a necessidade de “gambiarras” técnicas com SQLCLR para tarefas cotidianas de manipulação de strings e trazem uma performance muito mais previsível e integrada. Se você está começando um projeto novo ou planejando o upgrade para o SQL 2025, o uso dessas funções é o caminho oficial e recomendado.
Espero que tenham gostado dessa dica, um grande abraço e até a próxima!

Comentários (0)
Carregando comentários...