Fala pessoal!
Nesse artigo que gostaria de compartilhar com vocês uma consulta que permite identificar quais as consultas que estão utilizando um determinado índice. Esse tipo de análise pode ser especialmente útil para identificar quais as consultas que estão fazendo um índice ter mais operações de scans que seeks, por exemplo.
A ideia desse post veio de uma dúvida a partir de um grupo do Whatsapp que participo.
Esse post faz parte de uma série de artigos relacionados a performance, que contém os posts abaixo:
– Entendendo o funcionamento dos índices no SQL Server
– SQL Server – Comparação de performance entre Scalar Function e CLR Scalar Function
– SQL Server – Introdução ao estudo de Performance Tuning
– SQL Server – Como identificar uma query lenta ou pesada no seu banco de dados
– SQL Server – Como identificar as consultas que utilizam um determinado índice através do plan cache
Criando dados para os testes
Para demonstrar como essa query retorna os dados, vou criar uma nova tabela, inserir alguns registros e realizar algumas consultas simples para que as estatísticas do banco capturem essas operações e eu consiga verificar quais utilizaram quais índices:
IF (OBJECT_ID('dbo.Teste') IS NOT NULL) DROP TABLE dbo.Teste
GO
CREATE TABLE dbo.Teste (
Id INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, -- Índice clustered no ID
Nome VARCHAR(100) NOT NULL
) WITH(DATA_COMPRESSION=PAGE)
-- Índice non-clustered no nome
CREATE NONCLUSTERED INDEX SK01_Teste ON dbo.Teste(Nome) WITH(DATA_COMPRESSION=PAGE)
INSERT INTO dbo.Teste(Nome)
VALUES
('Dirceu'), ('Resende'),
('Tiago'), ('Neves'),
('Fabricio'), ('Lima'),
('Luiz'), ('Lima'),
('Alan'), ('Mairink'),
('Arthur'), ('Luz'),
('Fabiano'), ('Amorim'),
('Rodrigo'), ('Ribeiro')
SELECT * FROM dbo.Teste WHERE Id = 2 -- Deve utilizar o índice clustered (seek)
SELECT * FROM dbo.Teste WHERE Id = 99 -- Deve utilizar o índice clustered (seek)
SELECT * FROM dbo.Teste WHERE Nome = 'Dirceu' -- Deve utilizar o índice non-clustered "SK01_Teste" (seek)
SELECT * FROM dbo.Teste WHERE Nome = 'Resende' -- Deve utilizar o índice non-clustered "SK01_Teste" (seek)
SELECT * FROM dbo.Teste -- Deve utilizar o índice non-clustered (scan)Identificando o uso dos índices
Uma vez que criamos os dados para testes e fizemos algumas consultas, vamos identificar quais as consultas utilizaram o índice clustered. Antes disso, preciso identificar o nome desse índice:
SELECT *
FROM sys.indexes
WHERE [object_id] = OBJECT_ID('dbo.Teste')
Agora, vamos consultar as consultas que utilizaram esse índice clustered (PK__Teste__3214EC075F9CA38E):
SELECT
SUBSTRING(C.[text], ( A.statement_start_offset / 2 ) + 1, ( CASE A.statement_end_offset WHEN -1 THEN DATALENGTH(C.[text]) ELSE A.statement_end_offset END - A.statement_start_offset ) / 2 + 1) AS sqltext,
A.execution_count,
A.total_logical_reads / execution_count AS avg_logical_reads,
A.total_logical_writes / execution_count AS avg_logical_writes,
A.total_worker_time / execution_count AS avg_cpu_time,
A.last_elapsed_time / execution_count AS avg_elapsed_time,
A.total_rows / execution_count AS avg_rows,
A.creation_time,
A.last_execution_time,
CAST(query_plan AS XML) AS plan_xml,
B.query_plan,
C.[text]
FROM
sys.dm_exec_query_stats AS A
CROSS APPLY sys.dm_exec_text_query_plan(A.plan_handle, A.statement_start_offset, A.statement_end_offset) AS B
CROSS APPLY sys.dm_exec_sql_text(A.[sql_handle]) AS C
WHERE
B.query_plan LIKE '%PK__Teste__3214EC075F9CA38E%'
AND B.query_plan NOT LIKE '%dm_exec_text_query_plan%'
ORDER BY
A.last_execution_time DESC
OPTION(RECOMPILE)
Resultado:

Vamos também consultar as consultas que utilizaram o índice non-clustered SK01_Teste:
SELECT
SUBSTRING(C.[text], ( A.statement_start_offset / 2 ) + 1, ( CASE A.statement_end_offset WHEN -1 THEN DATALENGTH(C.[text]) ELSE A.statement_end_offset END - A.statement_start_offset ) / 2 + 1) AS sqltext,
A.execution_count,
A.total_logical_reads / execution_count AS avg_logical_reads,
A.total_logical_writes / execution_count AS avg_logical_writes,
A.total_worker_time / execution_count AS avg_cpu_time,
A.last_elapsed_time / execution_count AS avg_elapsed_time,
A.total_rows / execution_count AS avg_rows,
A.creation_time,
A.last_execution_time,
CAST(query_plan AS XML) AS plan_xml,
B.query_plan,
C.[text]
FROM
sys.dm_exec_query_stats AS A
CROSS APPLY sys.dm_exec_text_query_plan(A.plan_handle, A.statement_start_offset, A.statement_end_offset) AS B
CROSS APPLY sys.dm_exec_sql_text(A.[sql_handle]) AS C
WHERE
B.query_plan LIKE '%SK01_Teste%'
AND B.query_plan NOT LIKE '%dm_exec_text_query_plan%'
ORDER BY
A.last_execution_time DESC
OPTION(RECOMPILE)
Resultado:

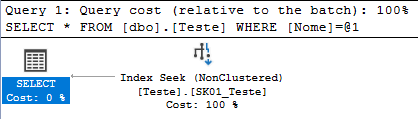
Clicando na coluna “plan_xml”, podemos visualizar o plano de execução dessa consulta e analisar como o índice apareceu no plan cache:
Algumas observações
É importante sempre relembrar que o plan cache é “perdido” quando o serviço do SQL Server é reiniciado ou feito um failover, ou seja, você não conseguirá ter um histórico muito longo das consultas que utilizam determinado índice.
Outro ponto legal que eu gostaria de destacar, é que o plan cache possui uma quantidade de memória que ele pode utilizar para armazenar os planos. O SQL Server não pode (e nem deve) guardar todos os planos de todas as consultas, então ele deve otimizar para guardar apenas os planos que ele julga serem os mais importantes. Sendo assim, nem sempre você conseguirá recuperar informações de uma determinada consulta na plan cache, pois o plano já pode ter sido descartado por questões de memória e limite de armazenamento, mesmo que o SQL não tenha sido reiniciado.
Para finalizar, é legal observar e confirmar que operações de INSERT/DELETE/UPDATE acabam “utilizando” todos os índices da tabela. Qualquer índice específico que você consulte com a query acima, terão registros de INSERT/UPDATE/DELETE entre os comandos que utilizaram o índice (desde que esses planos ainda estejam no plan cache), já que os índices precisam ser atualizados em operações de escrita na tabela.
Bom pessoal, é isso! Espero que vocês tenham gostado desse artigo.
Um abraço e até mais!

Comentários (0)
Carregando comentários...