
Fala pessoal!
Nesse post, eu gostaria de compartilhar com vocês um script para identificar todos os índices ausentes (Missing indexes) de um banco de dados no SQL Server, Managed Instance ou Azure SQL Database. Lembrando que para a execução deste script, você irá precisar da permissão “View server state” na instância.
Eu já havia compartilhado esse script nos artigos Entendendo o funcionamento dos índices no SQL Server e SQL Server – Consultas úteis do dia a dia do DBA que você sempre tem que ficar procurando na Internet, mas o Google não indexava corretamente quem buscava esse script.
Uma reflexão sobre índices
Uma das tarefas do dia a dia de um DBA, é identificar índices no banco de dados que poderiam melhorar o desempenho de consultas que estejam impactando o ambiente. Esse deve ser sempre o objetivo de um índice: Melhorar o desempenho de consultas que estejam impactando o ambiente ou poderiam ter um ganho num processo crítico.
Na maioria dos ambientes, você não poderá criar índices para cobrir todas as consultas que chegam ao banco de dados. Índices possuem um custo de armazenamento (ocupam espaço, muitas vezes, os índices ocupam mais espaço até que a própria tabela) e eles diminuem o desempenho das operações de escrita, além de necessitar de processos de manutenção como reorganize/rebuild para manter a fragmentação baixa.
Por esses motivos citados acima, você não pode sair criando índices sem nenhum controle. Índices devem ser muito bem pensados para tentar ter o melhor custo benefício possível. Se um índice não está sendo utilizado, ele deve ser excluído.
Uma outra dica que eu sempre falo é: Muitas vezes, você irá precisar criar vários índices non-clustered, porque o seu índice clustered foi mal planejado. Sempre avalie se o índice clustered está otimizado para a forma com que as consultas são feitas no banco de dados. Não adianta você criar o índice clustered na coluna de autoincremento, se ela não é usada como filtro nas principais consultas.
Não se prenda somente a números e grandes reduções de tempo de execução. Se um índice está servindo para reduzir o tempo de uma consulta de 1h para 1 segundo, mas é uma consulta executada apenas 1x por dia, de madrugada, e não está trazendo nenhum grande ganho, ele não está ajudando. Teria sido melhor tentar otimizar uma consulta que demorava 5 segundos e agora ela demora 0ms, mas é executada 1 milhão de vezes por dia.
Sempre tente pensar bem no valor que o índice agregará para os processos da empresa antes de criá-lo. Como eu disse, não dá para criar índice para cada consulta que chega no banco de dados. Foque no que realmente importa e está de fato, sendo um problema, causando uma lentidão no sistema, fazendo um cliente esperar enquanto os dados são carregados, coisas desse tipo.
O que são os índices ausentes (Missing indexes)
Visando ajudar os DBAs a identificar rapidamente situações onde um índice poderia fazer a diferença, o SQL Server possui um conjunto de DMVs dm_db_missing_index_% que trazem informações sobre esses índices ausentes (Missing indexes).
Essas informações são geradas automaticamente pelo Engine do SQL Server baseado nos planos de execução em cache, ou seja, baseado nas consultas que já foram enviadas para o banco de dados, o SQL Server identifica alguns índices que poderiam cobrir essas consultas para prover um melhor desempenho, considerando os índices já existentes, colunas filtradas e as colunas retornadas.
Após essa análise, o resultado fica disponível para consulta utilizando o script que vou compartilhar com vocês, e rapidamente o DBA pode analisar as sugestões e identificar o que faz sentido criar e o que não faz.
Não saia criando índices sem analisar antes, mesmo que sejam Missing index retornandos por esse script. Nem sempre o melhor índice possível será retornado e, muitas vezes, já existe um índice muito parecido com o sugerido, onde vale mais a pena mesclar o índice existente com o índice sugerido, alterando o índice atual e só incluir as novas colunas sugeridas. Isso é muito melhor do que manter 2 índices quase iguais.
E acreditem: É muito comum ver vários e vários índices criados em clientes, onde o DBA não quis ter o trabalho nem de renomear os índices, quanto mais, analisar se existem melhores formas de criar o índice sugerido.
Como identificar todos os índices ausentes (Missing indexes) de um banco de dados
Com a consulta abaixo, você poderá visualizar as sugestões de índices do SQL Server baseado nas estatísticas de Missing Index. Para a geração desses dados, serão utilizadas o conjunto de DMV’s de Missing Index (dm_db_missing_index_%).
SELECT
db.[name] AS [DatabaseName],
id.[object_id] AS [ObjectID],
OBJECT_NAME(id.[object_id], db.[database_id]) AS [ObjectName],
gs.avg_total_user_cost * ( gs.avg_user_impact / 100.0 ) * ( gs.user_seeks + gs.user_scans ) AS ImprovementMeasure,
gs.[user_seeks] * gs.[avg_total_user_cost] * ( gs.[avg_user_impact] * 0.01 ) AS [IndexAdvantage],
'CREATE INDEX [IX_' + OBJECT_NAME(id.[object_id], db.[database_id]) + '_' + REPLACE(REPLACE(REPLACE(ISNULL(id.[equality_columns], ''), ', ', '_'), '[', ''), ']', '') + CASE WHEN id.[equality_columns] IS NOT NULL AND id.[inequality_columns] IS NOT NULL THEN '_' ELSE '' END + REPLACE(REPLACE(REPLACE(ISNULL(id.[inequality_columns], ''), ', ', '_'), '[', ''), ']', '') + '_' + LEFT(CAST(NEWID() AS [NVARCHAR](64)), 5) + ']' + ' ON ' + id.[statement] + ' (' + ISNULL(id.[equality_columns], '') + CASE WHEN id.[equality_columns] IS NOT NULL AND id.[inequality_columns] IS NOT NULL THEN ',' ELSE '' END + ISNULL(id.[inequality_columns], '') + ')' + ISNULL(' INCLUDE (' + id.[included_columns] + ')', '') AS [ProposedIndex],
id.[statement] AS [FullyQualifiedObjectName],
id.[equality_columns] AS [EqualityColumns],
id.[inequality_columns] AS [InEqualityColumns],
id.[included_columns] AS [IncludedColumns],
gs.[unique_compiles] AS [UniqueCompiles],
gs.[user_seeks] AS [UserSeeks],
gs.[user_scans] AS [UserScans],
gs.[last_user_seek] AS [LastUserSeekTime],
gs.[last_user_scan] AS [LastUserScanTime],
gs.[avg_total_user_cost] AS [AvgTotalUserCost],
gs.[avg_user_impact] AS [AvgUserImpact],
gs.[system_seeks] AS [SystemSeeks],
gs.[system_scans] AS [SystemScans],
gs.[last_system_seek] AS [LastSystemSeekTime],
gs.[last_system_scan] AS [LastSystemScanTime],
gs.[avg_total_system_cost] AS [AvgTotalSystemCost],
gs.[avg_system_impact] AS [AvgSystemImpact],
CAST(CURRENT_TIMESTAMP AS [SMALLDATETIME]) AS [CollectionDate]
FROM
[sys].[dm_db_missing_index_group_stats] gs WITH ( NOLOCK )
JOIN [sys].[dm_db_missing_index_groups] ig WITH ( NOLOCK ) ON gs.[group_handle] = ig.[index_group_handle]
JOIN [sys].[dm_db_missing_index_details] id WITH ( NOLOCK ) ON ig.[index_handle] = id.[index_handle]
JOIN [sys].[databases] db WITH ( NOLOCK ) ON db.[database_id] = id.[database_id]
WHERE
db.[database_id] = DB_ID()
--AND gs.avg_total_user_cost * ( gs.avg_user_impact / 100.0 ) * ( gs.user_seeks + gs.user_scans ) > 10
ORDER BY
[IndexAdvantage] DESC
OPTION ( RECOMPILE );Resultado:
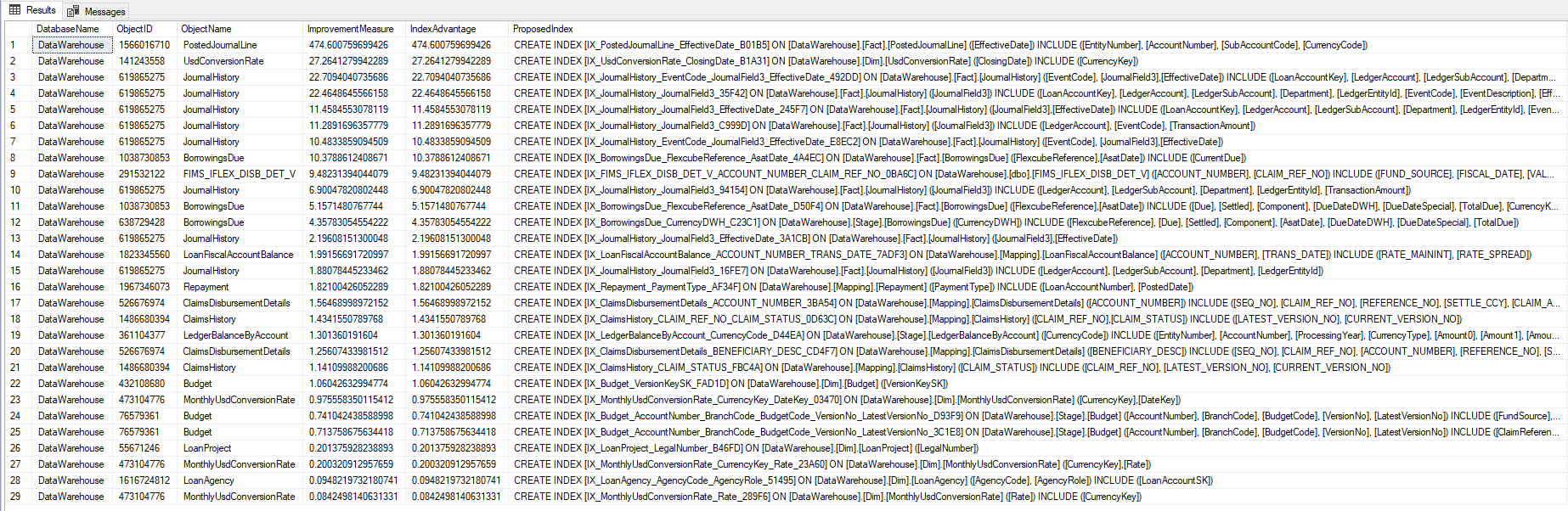
Como você viram, no script acima, utilizamos as DMV’s do SQL Server para identificar os índices ausentes na base. Uma outra alternativa, que até nos permite ver o plano de execução, é ir direto nas DMV’s da plancache, e extrair esses dados do XML do plano de execução.
IF (OBJECT_ID('tempdb..#MissingIndexInfo') IS NOT NULL) DROP TABLE #MissingIndexInfo
;WITH XMLNAMESPACES
(
DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan'
)
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(REPLACE(REPLACE(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'), '[', ''), ']', '')) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' + n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' + n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' + n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' + n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)') AS statement,
(
SELECT DISTINCT
c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM
n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE
cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
(
SELECT DISTINCT
c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM
n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE
cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
(
SELECT DISTINCT
c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM
n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE
cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
INTO
#MissingIndexInfo
FROM
(
SELECT
query_plan
FROM
(
SELECT DISTINCT
plan_handle
FROM
sys.dm_exec_query_stats WITH ( NOLOCK )
) AS qs
OUTER APPLY sys.dm_exec_query_plan(qs.plan_handle) tp
WHERE
tp.query_plan.exist('//MissingIndex') = 1
) AS tab(query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE
n.exist('QueryPlan/MissingIndexes') = 1;
-- Trim trailing comma from lists
UPDATE
#MissingIndexInfo
SET
equality_columns = LEFT(equality_columns, LEN(equality_columns) - 1),
inequality_columns = LEFT(inequality_columns, LEN(inequality_columns) - 1),
include_columns = LEFT(include_columns, LEN(include_columns) - 1);
SELECT
*
FROM
#MissingIndexInfo
ORDER BY
[impact] DESC;Resultado:
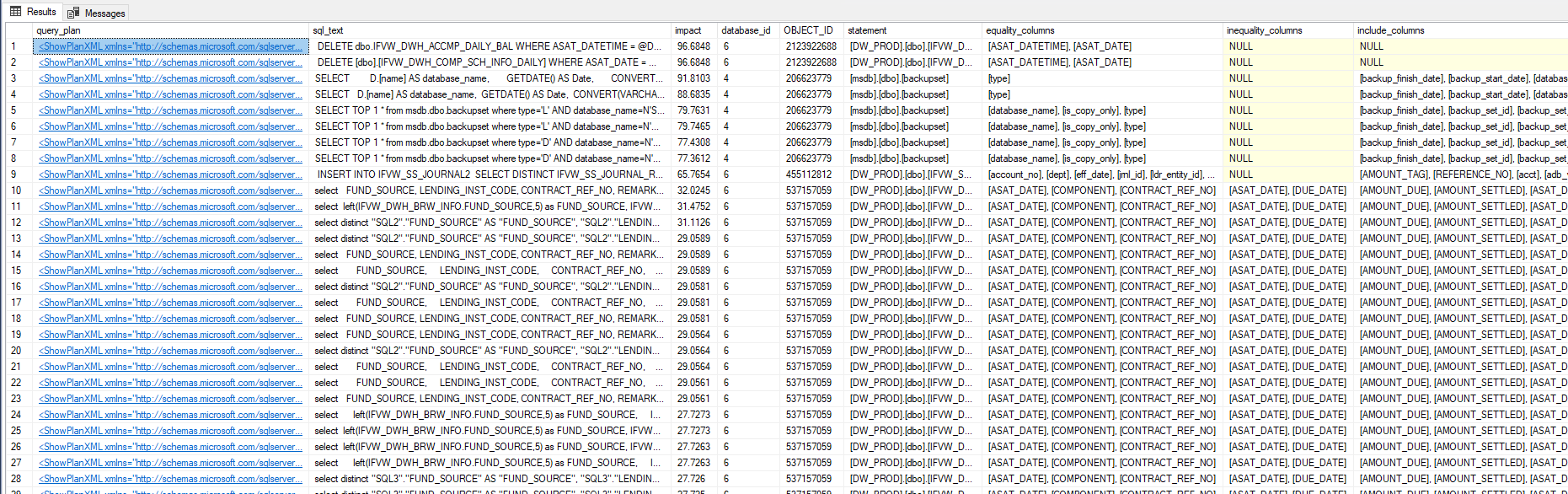
Agora é só clicar no XML (primeira coluna – query_plan) para visualizar o plano de execução (e ver o aviso do Missing index)

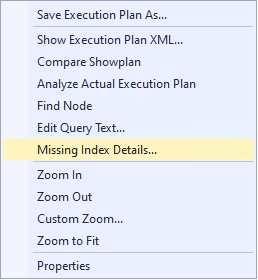
Clicar com o botão direito do mouse e selecionar a opção “Missing Index Details…”
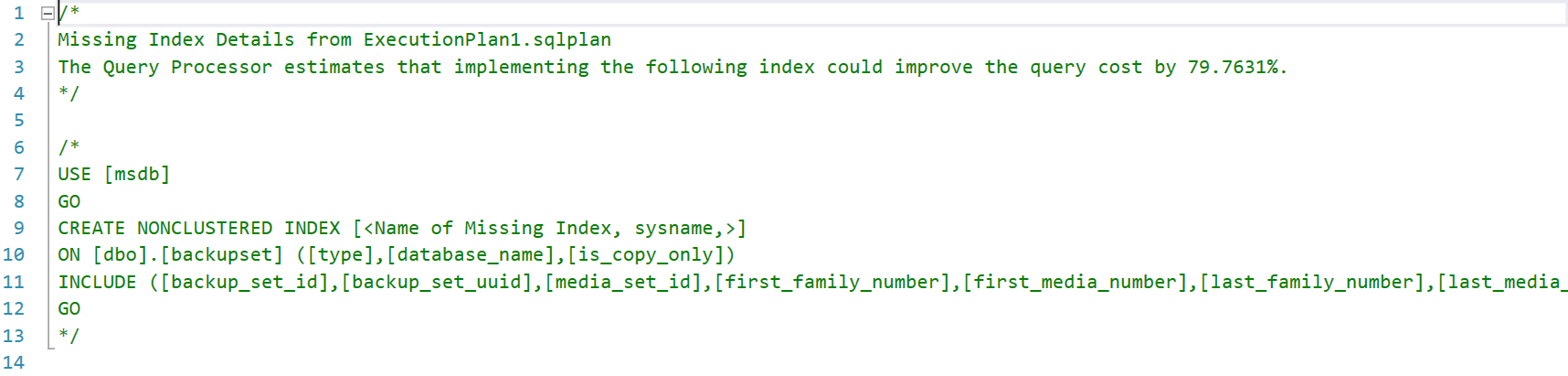
E conferir o script gerado automaticamente para a criação do índice:
Para entender melhor sobre performance tuning e entender o que é operação de Seek, Scan, etc, leia o artigo SQL Server – Introdução ao estudo de Performance Tuning.
Conclusão
Encerrando esse artigo, espero que tenham gostado dessa dica. Ela com certeza, será muito útil no seu dia a dia de DBA, especialmente para os iniciantes.
Lembre-se das minhas dicas e não saia criando todo índice sugerido e sempre analise antes de criá-lo para saber se esse índice poderia ser melhor otimizado ou mesclado com um já existente.
Analise também se esse índice vai realmente agregar valor para o negócio ou vai apenas ocupar espaço em disco e melhorar uma consulta que não irá fazer a diferença, como um query executada 1x por dia, de madrugada.
E é isso aí, pessoal!
Um grande abraço e até o próximo post!

Comentários (0)
Carregando comentários...