
Olá pessoal,
Bom dia!
Neste post vou falar sobre um assunto que não é nenhuma novidade no SQL Server, está presente desde o SQL Server 2008, mas não vejo muita gente utilizando em suas consultas, que é o agrupamento de dados (sumarização) utilizando ROLLUP, CUBE e GROUPING SETS.
Esse tipo de recurso é especialmente útil para gerar totais e subtotais sem precisar criar várias subquerys, pois permite realizar essa tarefa em um único comando, conforme vou demonstrar abaixo.
Para criar um recurso de AutoSoma em seu conjunto de dados, assim com o Excel implementa, veja mais no post SQL Server – Como criar uma AutoSoma (igual do Excel) utilizando Window functions
Base de Testes
Para os exemplos desse post, vou disponibilizar a base abaixo para que possamos criar um ambiente de testes e demonstrações.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
IF (OBJECT_ID('tempdb..#Produtos') IS NOT NULL) DROP TABLE #Produtos CREATE TABLE #Produtos ( Codigo INT IDENTITY(1, 1) NOT NULL PRIMARY KEY, Ds_Produto VARCHAR(50) NOT NULL, Ds_Categoria VARCHAR(50) NOT NULL, Preco NUMERIC(18, 2) NOT NULL ) IF (OBJECT_ID('tempdb..#Vendas') IS NOT NULL) DROP TABLE #Vendas CREATE TABLE #Vendas ( Codigo INT IDENTITY(1, 1) NOT NULL PRIMARY KEY, Dt_Venda DATETIME NOT NULL, Cd_Produto INT NOT NULL ) INSERT INTO #Produtos ( Ds_Produto, Ds_Categoria, Preco ) VALUES ( 'Processador i7', 'Informática', 1500.00 ), ( 'Processador i5', 'Informática', 1000.00 ), ( 'Processador i3', 'Informática', 500.00 ), ( 'Placa de Vídeo Nvidia', 'Informática', 2000.00 ), ( 'Placa de Vídeo Radeon', 'Informática', 1500.00 ), ( 'Celular Apple', 'Celulares', 10000.00 ), ( 'Celular Samsung', 'Celulares', 2500.00 ), ( 'Celular Sony', 'Celulares', 4200.00 ), ( 'Celular LG', 'Celulares', 1000.00 ), ( 'Cama', 'Utilidades do Lar', 2000.00 ), ( 'Toalha', 'Utilidades do Lar', 40.00 ), ( 'Lençol', 'Utilidades do Lar', 60.00 ), ( 'Cadeira', 'Utilidades do Lar', 200.00 ), ( 'Mesa', 'Utilidades do Lar', 1000.00 ), ( 'Talheres', 'Utilidades do Lar', 50.00 ) DECLARE @Contador INT = 1, @Total INT = 100 WHILE(@Contador <= @Total) BEGIN INSERT INTO #Vendas ( Cd_Produto, Dt_Venda ) SELECT (SELECT TOP 1 Codigo FROM #Produtos ORDER BY NEWID()) AS Cd_Produto, DATEADD(DAY, (CAST(RAND() * 364 AS INT)), '2017-01-01') AS Dt_Venda SET @Contador += 1 END |
Em um agrupamento de dados simples, apenas trazendo as quantidades filtrando por categoria e produto, conseguimos retornar essa visão utilizando a consulta abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT B.Ds_Categoria, B.Ds_Produto, COUNT(*) AS Qt_Vendas, SUM(B.Preco) AS Vl_Total FROM #Vendas A JOIN #Produtos B ON A.Cd_Produto = B.Codigo GROUP BY B.Ds_Categoria, B.Ds_Produto ORDER BY 1, 2 |

Sumarizando os valores
Mas e se você precisar agrupar os dados criando um totalizador de cada categoria e no final e um totalizador geral? Como você faria?
Utilizando UNION ALL
Uma forma tradicional de se atender essa necessidade, é utilizando subquery com UNION ALL, de forma que você retorne 3 resultsets contendo os dados analíticos, os totalizadores por categoria e depois a soma geral. Quanto maior o número de filtros, mais complexo será a sua subquery, pois precisará de mais consultas a cada nível.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
SELECT * FROM ( SELECT B.Ds_Categoria, B.Ds_Produto, COUNT(*) AS Qt_Vendas, SUM(B.Preco) AS Vl_Total FROM #Vendas A JOIN #Produtos B ON A.Cd_Produto = B.Codigo GROUP BY B.Ds_Categoria, B.Ds_Produto UNION ALL SELECT B.Ds_Categoria, 'Subtotal' AS Ds_Produto, COUNT(*) AS Qt_Vendas, SUM(B.Preco) AS Vl_Total FROM #Vendas A JOIN #Produtos B ON A.Cd_Produto = B.Codigo GROUP BY B.Ds_Categoria UNION ALL SELECT 'Total' AS Ds_Categoria, 'Total' AS Ds_Produto, COUNT(*) AS Qt_Vendas, SUM(B.Preco) AS Vl_Total FROM #Vendas A JOIN #Produtos B ON A.Cd_Produto = B.Codigo ) A ORDER BY (CASE WHEN A.Ds_Categoria = 'Total' THEN 1 ELSE 0 END), A.Ds_Categoria, (CASE WHEN A.Ds_Produto = 'Subtotal' THEN 1 ELSE 0 END), A.Ds_Produto |

Utilizando GROUP BY ROLLUP
Uma forma muito simples e prática de se resolver esse problema é utilizando a função ROLLUP() no GROUP BY, que já cria os agrupamentos e sumarizações de acordo com as colunas agrupadas na função.
Utilizando essa função, você verá que ela cria os totalizadores logo abaixo de cada agrupamento e o totalizador geral na última linha do resultset.
Exemplo 1:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT B.Ds_Categoria, B.Ds_Produto, COUNT(*) AS Qt_Vendas, SUM(B.Preco) AS Vl_Total FROM #Vendas A JOIN #Produtos B ON A.Cd_Produto = B.Codigo GROUP BY ROLLUP(B.Ds_Categoria, B.Ds_Produto) |

Como vocês devem ter notado, as linhas contendo as sumarizações possuem o valor NULL nas colunas agrupadas. Neste exemplo, o subtotal por categoria possui a coluna Ds_Produto com o valor NULL e no total geral, as duas colunas possuem valor NULL. Para que a nossa consulta produza o mesmo resultado da outra consulta com UNION ALL, basta tratarmos esses valores NULL, conforme demonstro abaixo:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT ISNULL(B.Ds_Categoria, 'Total') AS Ds_Categoria, ISNULL(B.Ds_Produto, 'Subtotal') AS Ds_Produto, COUNT(*) AS Qt_Vendas, SUM(B.Preco) AS Vl_Total FROM #Vendas A JOIN #Produtos B ON A.Cd_Produto = B.Codigo GROUP BY ROLLUP(B.Ds_Categoria, B.Ds_Produto) |

Exemplo 2:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT ISNULL(CONVERT(VARCHAR(10), MONTH(A.Dt_Venda)), 'Total') AS Mes_Venda, ISNULL(B.Ds_Categoria, 'Subtotal') AS Ds_Categoria, COUNT(*) AS Qt_Vendas, SUM(B.Preco) AS Vl_Total FROM #Vendas A JOIN #Produtos B ON A.Cd_Produto = B.Codigo GROUP BY ROLLUP(MONTH(A.Dt_Venda), B.Ds_Categoria) |
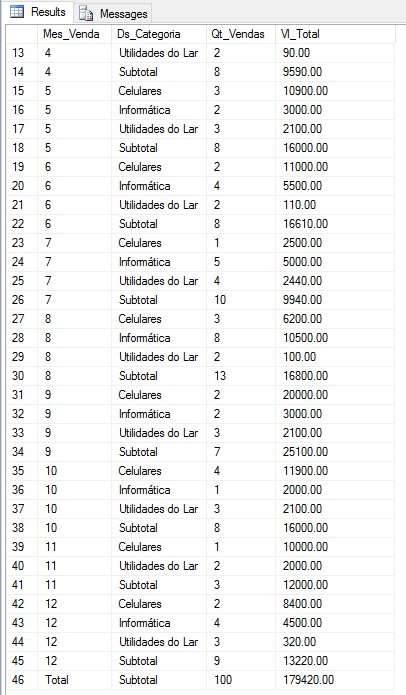
Utilizando GROUP BY CUBE
Assim como a função ROLLUP(), a função CUBE() permite criar totalizadores agrupados de uma forma muito prática e fácil e sua sintaxe é igual ao da função ROLLUP.
Utilizando essa função, você verá que a diferença dela para a ROLLUP, é que a função CUBE cria os totalizadores para cada tipo de agrupamento.
Exemplo:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT ISNULL(CONVERT(VARCHAR(10), MONTH(A.Dt_Venda)), 'Total') AS Mes_Venda, ISNULL(B.Ds_Categoria, 'Subtotal') AS Ds_Categoria, COUNT(*) AS Qt_Vendas, SUM(B.Preco) AS Vl_Total FROM #Vendas A JOIN #Produtos B ON A.Cd_Produto = B.Codigo GROUP BY CUBE(MONTH(A.Dt_Venda), B.Ds_Categoria) |

Vejam que utilizando a função CUBE(), eu consigo obter o totalizador geral, o totalizador da coluna Mes_Venda e o totalizador da coluna Categoria. Ou seja, na função CUBE, ele gera todas as possibilidades de combinação entre as colunas utilizadas na função.
Utilizando GROUP BY GROUPING SETS
Utilizando a função GROUPING SETS no GROUP BY nos possibilita gerar totalizadores dos nossos dados utilizando as colunas inseridas na função, de forma que ela gere totalizadores diferentes em uma única consulta. Diferente das funções ROLLUP e CUBE, a função GROUPING SETS não retorna um totalizador geral.
Exemplo 1:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT ISNULL(B.Ds_Produto, 'Total') AS Ds_Produto, ISNULL(B.Ds_Categoria, 'Subtotal') AS Ds_Categoria, COUNT(*) AS Qt_Vendas, SUM(B.Preco) AS Vl_Total FROM #Vendas A JOIN #Produtos B ON A.Cd_Produto = B.Codigo GROUP BY GROUPING SETS(B.Ds_Categoria, B.Ds_Produto) |

Neste exemplo, a função GROUPING SETS nos retorna o totalizador por produto e depois o totalizador por categoria, onde você precisaria executar 2 consultas para mostrar essa mesma visão.
Exemplo 2:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT MONTH(A.Dt_Venda) AS Mes_Venda, B.Ds_Categoria, B.Ds_Produto, COUNT(*) AS Qt_Vendas, SUM(B.Preco) AS Vl_Total FROM #Vendas A JOIN #Produtos B ON A.Cd_Produto = B.Codigo GROUP BY GROUPING SETS(MONTH(A.Dt_Venda), B.Ds_Categoria, B.Ds_Produto) |

Neste exemplo, a função GROUPING SETS retornou a soma dos valores agrupados pelas 3 colunas que utilizei na função: Soma por Mes_Venda, Soma por Produto e Soma por Categoria. Para reproduzir esse mesmo resultado, eu precisaria criar uma query com 3 consultas. Caso fossem 10 colunas, a query precisaria de 10 consultas diferentes para trazer esse resultado, o que conseguimos com uma única consulta utilizando a função GROUPING SETS.
Obs: Todas as 3 funções apresentadas nesse post aceitam N colunas como parâmetros, não sendo limitadas a apenas 2 colunas.
Desempenho e Performance
Agora que já vimos como funcionam as 3 funções e vimos o quão prática é sua utilização, economizando muitas linhas de código, vamos analisar se elas são performáticas ou não.
Vou procurar utilizar a mesma query para todos os casos, embora em alguns, o resultado (output) seja diferente, pois realmente tem objetivos diferentes, mas apenas para demonstrar o custo e plano de execução de cada um.
UNION ALL (Query do exemplo):
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
(19 row(s) affected)
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘#Produtos’. Scan count 2, logical reads 204, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘#Vendas’. Scan count 3, logical reads 64, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 79 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.

GROUP BY ROLLUP (Query do exemplo 1)
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(19 row(s) affected)
Table ‘#Vendas’. Scan count 1, logical reads 31, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘#Produtos’. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 57 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.

GROUP BY CUBE (Query do exemplo 1)
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 6 ms.
(49 row(s) affected)
Table ‘Worktable’. Scan count 2, logical reads 71, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘#Produtos’. Scan count 0, logical reads 200, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘#Vendas’. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 210 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.

GROUP BY GROUPING SETS (query do exemplo 1)
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 5 ms.
(18 row(s) affected)
Table ‘Worktable’. Scan count 2, logical reads 35, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘#Vendas’. Scan count 1, logical reads 31, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘#Produtos’. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 58 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.

Executando as 4 queries juntas:
Plano de execução do SQL Sentry Plan Explorer

Plano de execução do SQL Server Management Studio

Ou seja, com esses testes e utilizando essa massa de dados, podemos dizer que as consultas realizadas com essas funções são mais performáticas do que utilizar subquery com várias consultas para retornar os dados agrupados. Isso não quer dizer que essa afirmação será sempre verdade, vai depender muito do seu ambiente e da sua massa de dados.
Espero que tenham gostado desse post.
Um abraço!

Excelente explicação. Com os exemplos, as imagens e o passo a passo facilita muito a compreensão! Obrigado professor.
excelente conteúdo.
Muito bom o post. Não conhecia o comando. Vou passar a utilizar.
Ótimo post Dirceu! Sempre usei o UNION ALL para fazer essas sumarizações por desconhecer esses comandos. Vou colocar em prática a partir de agora.
Abraço.
Luiz Vitor
Valeu pelo retorno, Luiz Vitor. Também já usei muito Union all pra fazer isso.. Rs