Hola, chicos,
¡Buenas noches!
En esta publicación demostraré una herramienta utilizada por el 99,99% de los administradores de bases de datos de SQL Server en todo el mundo y probablemente ya la conozcas, que es el excelente y muy famoso procedimiento almacenado. sp_WhoIsActive, de Adam Machanic, el cual nos permite obtener una serie de información sobre las sesiones activas de una instancia de SQL Server como la consulta que se está ejecutando, el usuario que la ejecuta, el evento de espera, el tiempo de ejecución, el uso de CPU, el uso de Tempdb, las lecturas de disco (IO) y mucho más.
El objetivo de este post es demostrar esta herramienta y cómo diferentes parámetros y personalizaciones cambian el resultado final del Procedimiento almacenado. Hoy en día muchos DBA's siempre utilizan este SP con los parámetros por defecto, ya sea por desconocimiento de los parámetros o incluso de su existencia.
Antes de comenzar, haré la última versión del sp_WhoIsActive para que lo descargue, si no puede descargarlo desde el sitio web de Adam Machanic.
ACTUALIZAR: El 25/07/2017 puse a disposición una consulta que sería una “versión compacta” (lite) de sp_WhoIsActive. echa un vistazo en esta publicación.
Si visita este artículo en busca de consejos de rendimiento, lea también mi serie de artículos sobre este tema:
– Comprender cómo funcionan los índices en SQL Server
– SQL Server: comparación de rendimiento entre la función escalar y la función escalar CLR
– SQL Server – Introducción al estudio de Performance Tuning
– SQL Server: cómo identificar una consulta lenta o pesada en su base de datos
Espero que les guste esta serie 🙂
Un poco más sobre sp_WhoIsActive
Descripción de columnas Usando la ayuda de sp_WhoIsActiveConsultando la ayuda de sp_WhoIsActive
Esta herramienta tiene su propia ayuda, y podemos acceder a ella usando el parámetro @help = 1:
EXEC sp_whoIsActive @help = 1
y la salida se divide en 3 conjuntos de resultados:
Información sobre el creador de SP.
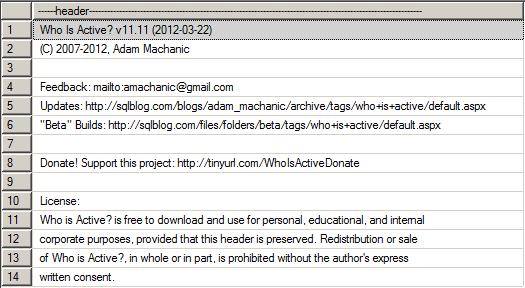
Descripción de los parámetros de llamada al SP
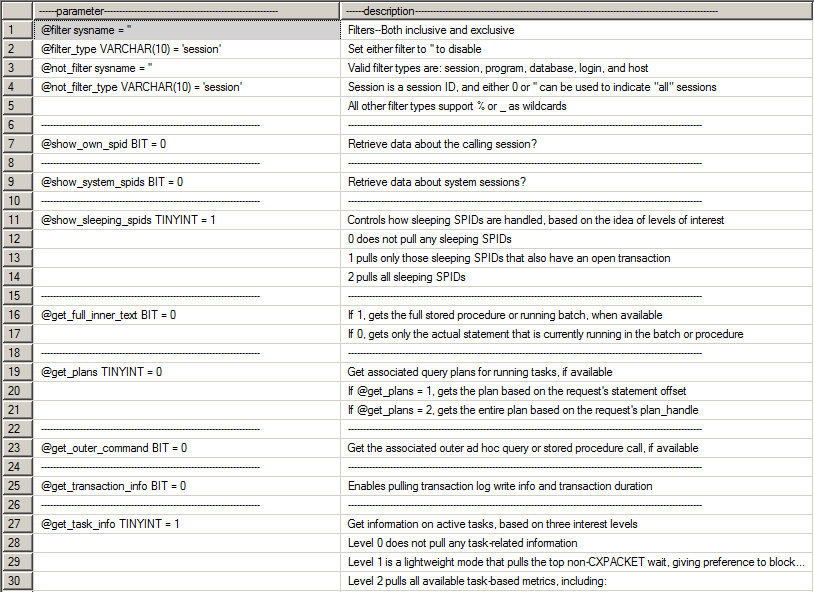
Descripción de las columnas devueltas por SP
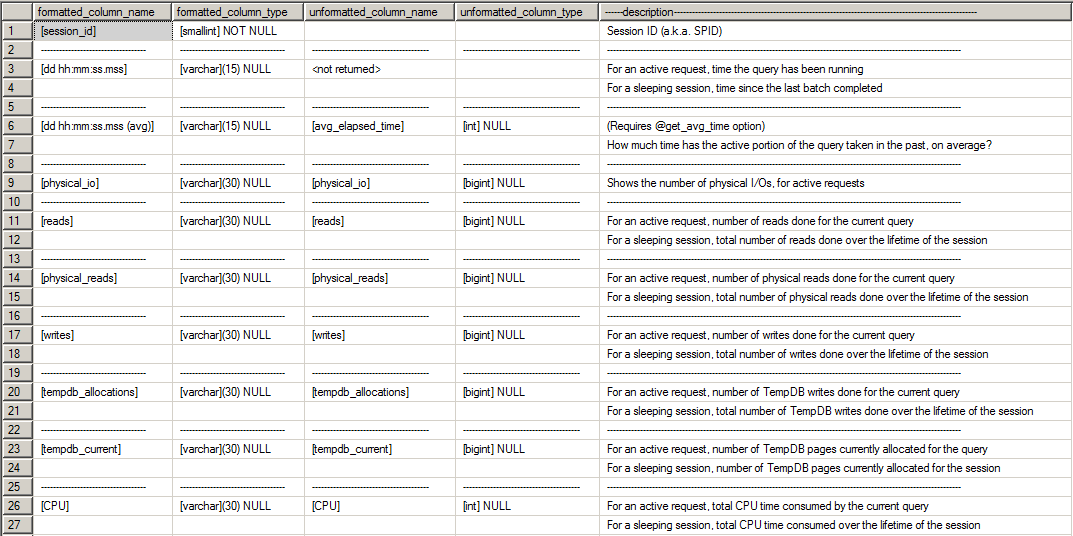
Permisos mínimos necesarios para ejecutar SP
Uno de los puntos importantes a comentar son los permisos mínimos necesarios para utilizar sp_WhoIsActive. He visto muchos DBA otorgar acceso de administrador de sistemas a un usuario, para que pueda usar este SP, porque no sabe qué se debe liberar para que el usuario ejecute el Procedimiento almacenado en la instancia, ya que lo más común es intentar liberar solo el permiso EJECUTAR en el Procedimiento almacenado.
Si no libera el permiso de ver el estado del servidor, verá el siguiente mensaje de error:
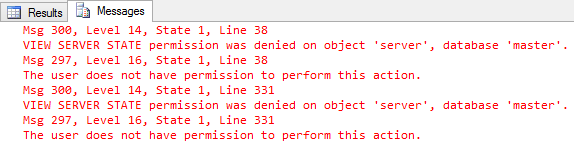
Para hacer esto, simplemente ejecute el siguiente comando, para que el usuario pueda usar sp_WhoIsActive normalmente:
USE [master]
GO
GRANT EXECUTE ON dbo.sp_WhoIsActive TO [dominio\usuario]
GRANT VIEW SERVER STATE TO [dominio\usuario]
GO
Usando parámetros en sp_WhoIsActive
Ejecución predeterminada, sin parámetros.Parte 1:

parte 2

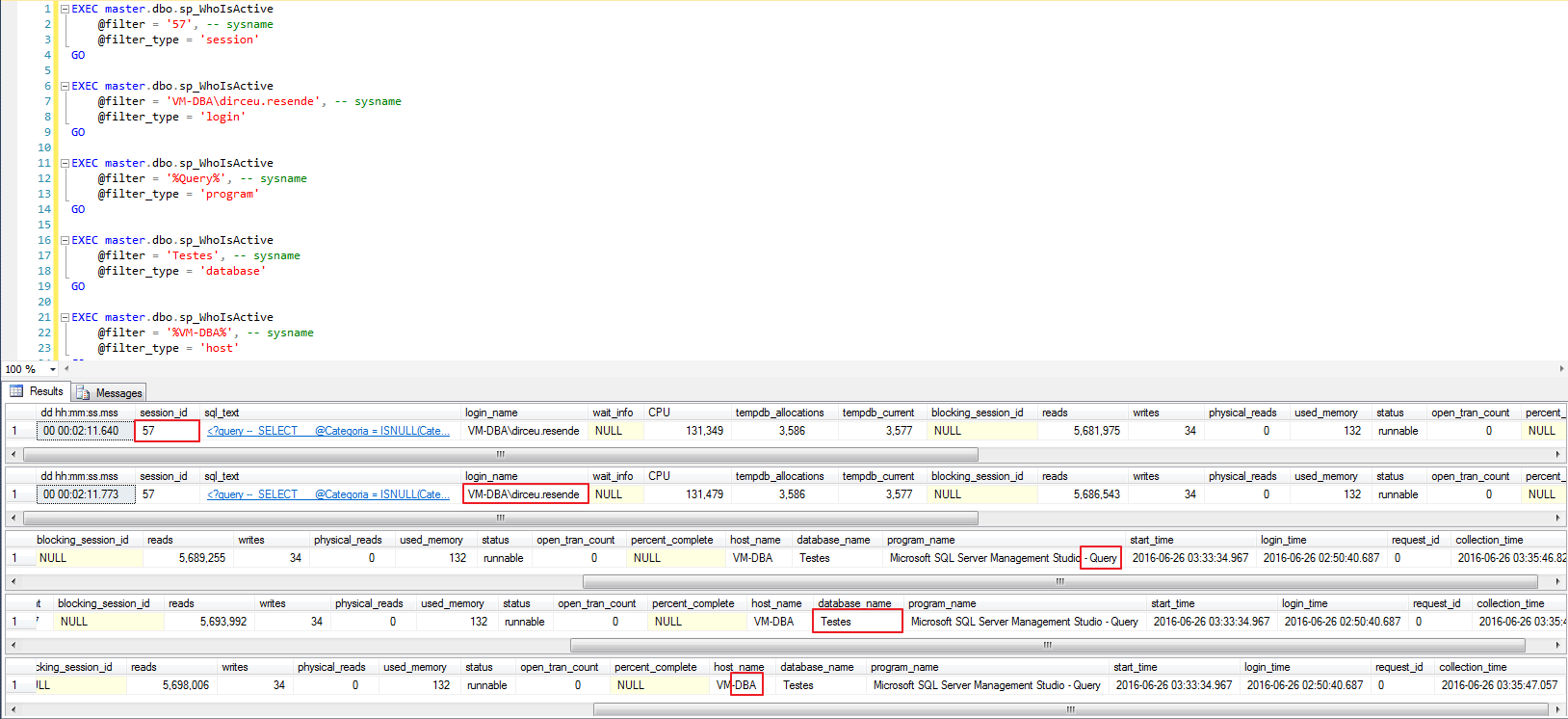
El parámetro @filter nos permite definir lo que queremos buscar (admite el comodín % para realizar búsquedas como LIKE ‘%string%’), mientras que el parámetro @filter_type nos permite definir dónde queremos buscar esta información. Los tipos posibles para @filter_type son:
- sesión: Le permite buscar una sesión específica
- programa: Le permite buscar sesiones que utilizan un software de cliente específico para conectarse a la base de datos.
- base de datos: Este tipo de filtro se utiliza para filtrar las consultas que se ejecutan en una base de datos determinada.
- acceso: Filtro utilizado para filtrar las sesiones de un usuario específico
- anfitrión: utilice este filtro para ver solo sesiones provenientes de un nombre de host específico
Ejemplos de uso de filtros inclusivos (@filter y @filter_type):
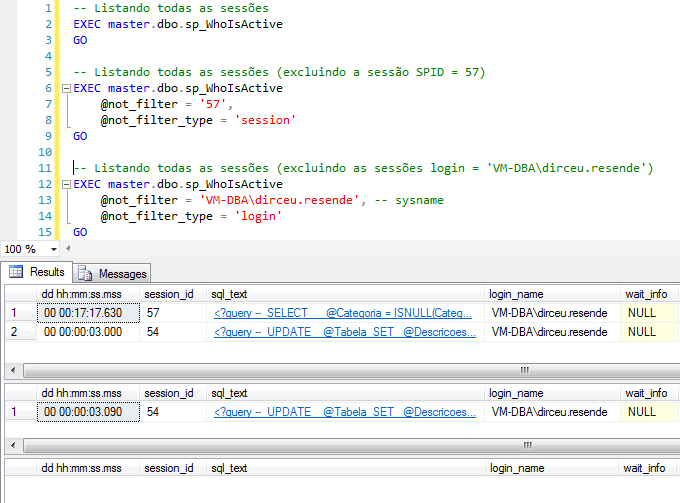
Ejemplos de uso de filtros únicos (@not_filter y @not_filter_type):
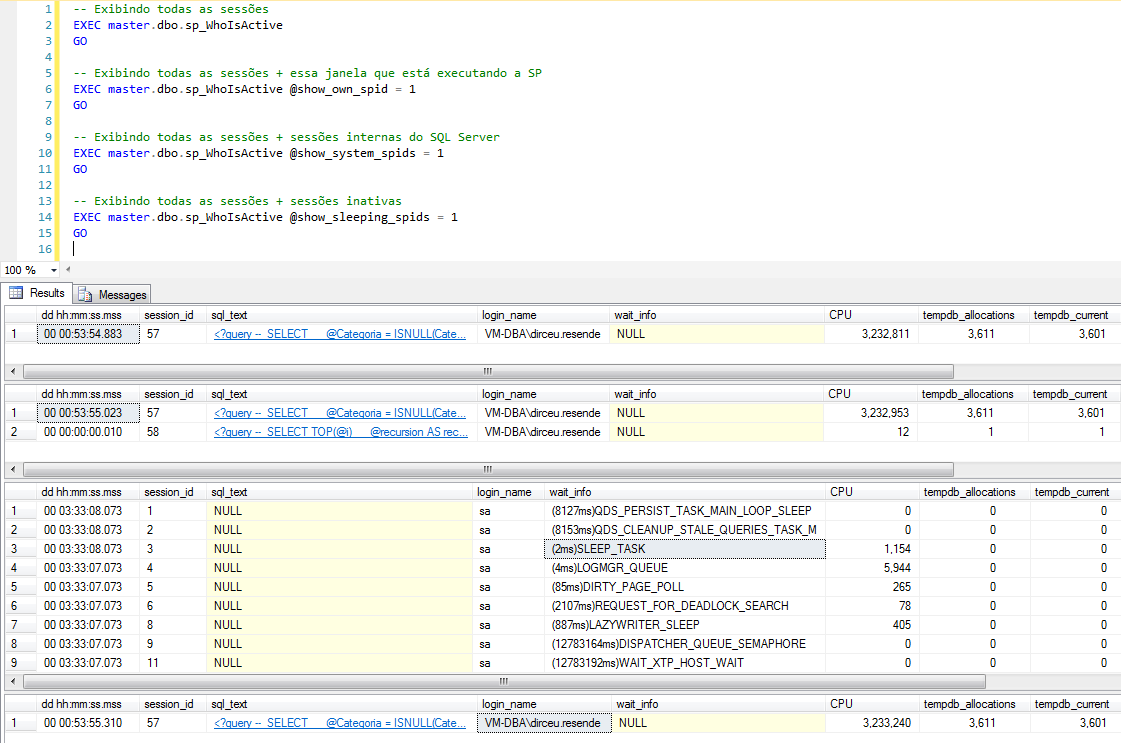
El parámetro @show_own_spid (BIT) determina si la sesión que está ejecutando el procedimiento será parte del resultado final que se mostrará en pantalla. El valor predeterminado es 0 (cero), lo que significa que la sesión en sí no se muestra de forma predeterminada.
El parámetro @show_system_spids (BIT) determina si las sesiones internas del sistema SQL Server se mostrarán en el resultado final del SP. El valor predeterminado es 0 (cero), lo que hace que estas sesiones se ignoren.
El parámetro @show_sleeping_spids (TINYINT) determina si las sesiones inactivas (durmiendo) se mostrarán en el resultado final del SP. El valor predeterminado es 0 (cero), lo que hace que estas sesiones se ignoren. El valor 1 muestra todas las sesiones inactivas que tienen una transacción abierta y el valor 2 muestra todas las sesiones inactivas.
Ejemplos de uso:
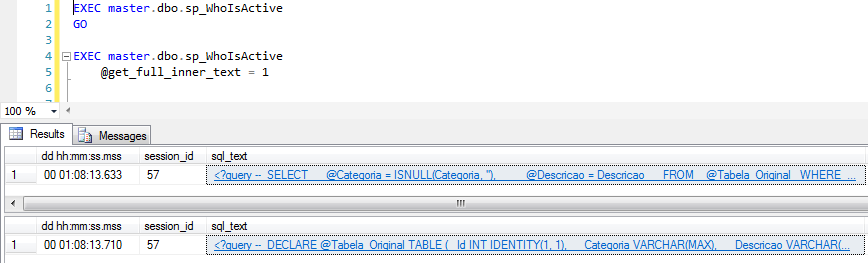
@get_full_inner_text
De forma predeterminada, la instrucción SQL que se devuelve en formato XML en la columna sql_text es solo el lote que se está procesando actualmente. Al utilizar este parámetro, podemos observar todo el contenido del lote que se envió a SQL Server para su procesamiento.
@get_plans
Al utilizar este parámetro con el valor 1, se generará una demostración del plan de ejecución de la consulta actual de cada sesión devuelta por este SP. Usando el valor 2 en este parámetro, se genera el plan de ejecución para toda la consulta de sesión. Al hacer clic en ResultSet XML, Management Studio ya muestra el plan de ejecución para esta consulta. ¡Fantástico!


@get_outer_command
Este parámetro es similar a @get_full_inner_text, pero en lugar de reemplazar el valor de la columna sql_text, mantiene esta columna con su valor predeterminado (solo la sección en ejecución) y agrega una nueva columna llamada sql_command, que contiene la consulta completa que está ejecutando la sesión. De esta manera, tenemos ambas opiniones.

@get_transaction_info
Usando este parámetro, podemos ver la cantidad y el volumen de datos escritos en el registro de transacciones para cada sesión.

@get_task_info
Un parámetro muy interesante para el análisis de rendimiento, @get_task_info le permite ver más información sobre las sesiones en ejecución. Al utilizar el valor 1, podemos ver los eventos de espera más grandes (aparte de CXPACKET).
Al utilizar el parámetro 2 visualizaremos el modo completo, que incluye las columnas:
- fisico_io: muestra el número de lecturas/escrituras físicas (E/S) en el disco.
- cambios de contexto: Muestra el número de cambios de contexto para la conexión activa. Un cambio de contexto ocurre cuando el kernel del sistema operativo cambia el procesador de un subproceso a otro (por ejemplo, un subproceso de mayor prioridad).
Este indicador es muy importante para identificar si un proceso está usando la CPU más que otros procesos y evitar que lleguen al procesador. Un índice muy alto significa que hay mucha competencia en el procesador y puede estar sobrecargado. Un número bajo significa que algún proceso está asignando más CPU de la que debería, generando mucho tiempo de espera (y probablemente sesiones con estado Pendiente y Ejecutable).
Los valores esperados deben ser algo inferiores a 2000 cambios por procesador/segundo (algunos DBA consideran aceptable un valor inferior a 5000). Los valores muy altos pueden deberse a fallas en la asignación de la memoria física (RAM). Otro posible agravante es la tecnología Intel® Hyper-Threading, que en algunos casos puede provocar muchos cambios de contexto debido a la simulación de núcleos virtuales. Si tiene este problema, una buena prueba es desactivar esta función en la placa base del servidor y realizar pruebas de rendimiento.
- tareas: Número de tareas utilizadas por la ejecución actual.
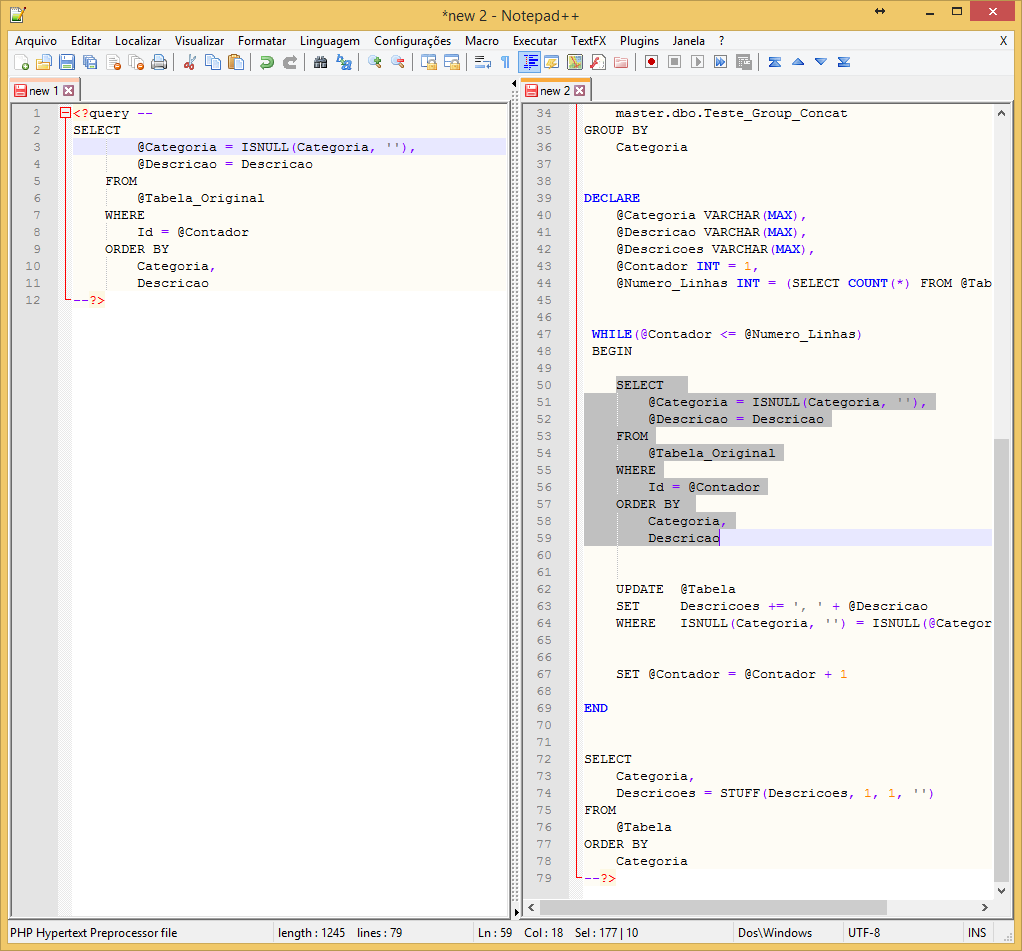
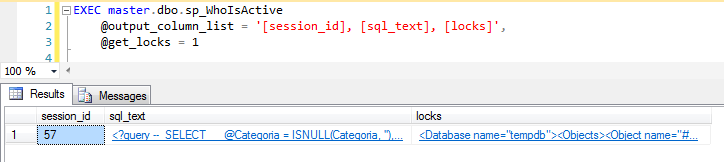
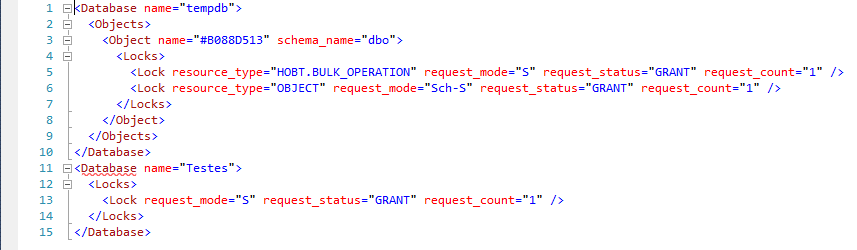
@get_locks
Parámetro muy útil para mantener e identificar bloqueos en la instancia. Al activarse muestra los objetos reservados para cada solicitud, así como el tipo de bloqueo solicitado por la sesión.
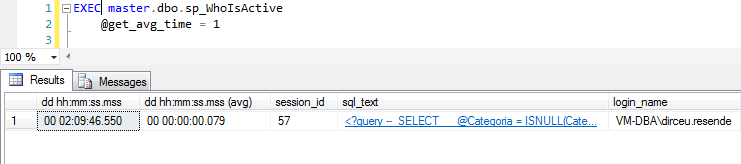
@get_avg_time
Usando este parámetro, aparece una nueva columna en el resultado final (dd hh:mm:ss.mss (avg)). Esta columna muestra el tiempo de ejecución promedio de la consulta actual que se ejecuta en cada sesión. Como puede ver en el ejemplo, mi consulta se ha estado ejecutando durante más de 2 horas, pero la sección actual está tardando un promedio de 79 ms, en un bucle de 850.000 iteraciones. Este tiempo se estima en base al plan y los historiales de ejecución.
@get_additional_info
Usando este parámetro, se creará una nueva columna en el resultado final llamada “additional_info”, que es un XML con diversa información y definiciones de comandos SET para cada sesión, como se muestra en el siguiente ejemplo:
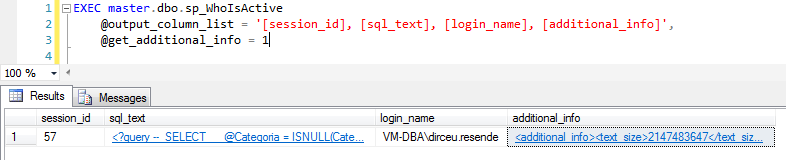
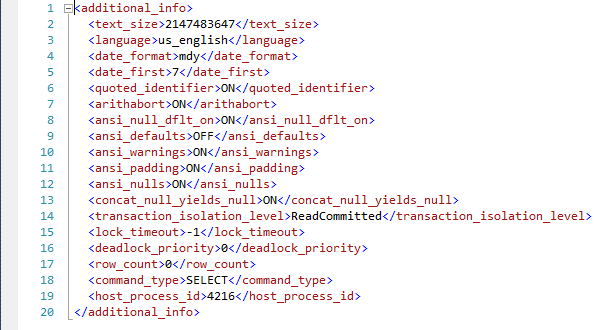
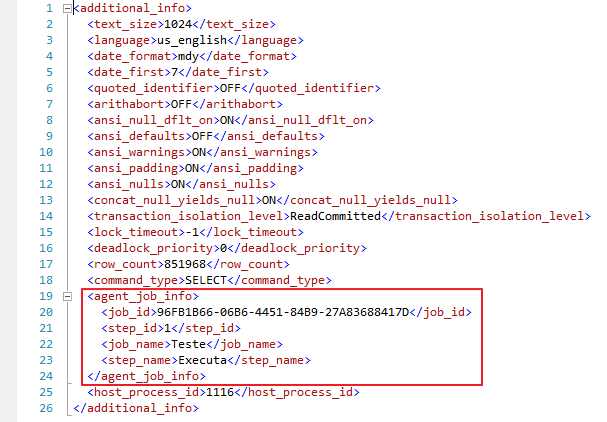
Si se está ejecutando un trabajo del Agente SQL Server, la columna de información adicional de esa sesión que abrió el trabajo tendrá la información del trabajo:
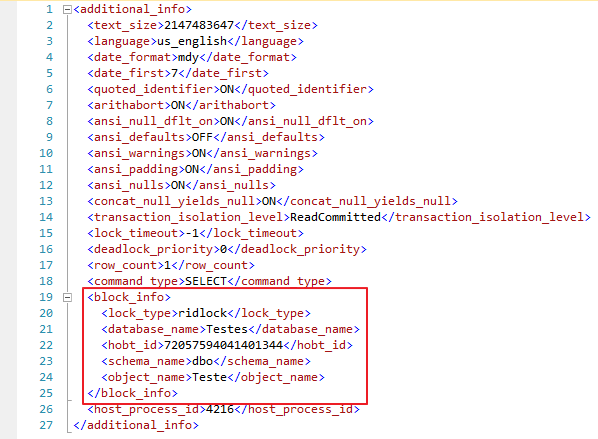
Si usas los parámetros @get_task_info = 2 y @get_additional_info = 1 y hay un bloqueo en una sesión, el XML en la columna “additional_info” de esa sesión que está bloqueada tendrá un nodo llamado block_info con la información del bloque:
@find_block_leaders
Uno de mis parámetros favoritos, @find_block_leaders, cuando está activado, le permite analizar cada sesión y contar cuántas otras sesiones están bloqueadas esperando que esa sesión libere objetos. ¿Sabe cuándo comienzan los eventos de bloqueo en su instancia de producción y debe seguir buscando quién está causando estos bloqueos? Este parámetro es la solución para usted.

@delta_interval
Esta interesante característica permite realizar dos recopilaciones de datos en un período de tiempo determinado (este período es el valor del parámetro, en segundos) y analizar la diferencia en la asignación de tempdb, lecturas, escrituras, etc. entre las dos recopilaciones realizadas.
En el siguiente ejemplo, especifiqué un intervalo de 10 segundos entre cada colección. Al cabo de 10 segundos, se crearán columnas con el sufijo "_delta", que demuestran la diferencia entre la primera y la segunda ejecución.
Esto es muy útil para analizar el crecimiento de la asignación de tempdb o lecturas de disco en tiempo real. A menudo, analizar sólo la sesión total y la asignación actual no es suficiente para estimar el crecimiento y la asignación de recursos, lo que hace que esta característica sea muy interesante para los DBA.

@salida_columna_lista
Como ya he demostrado en algunos ejemplos anteriores, este parámetro se utiliza para definir qué columnas deben formar parte del resultado final de la ejecución del SP.

@sort_order
Como sugiere el nombre, este parámetro se utiliza para ordenar los resultados según tus necesidades, donde eliges qué columnas usar para ordenar y cuáles son los criterios (asc o desc).
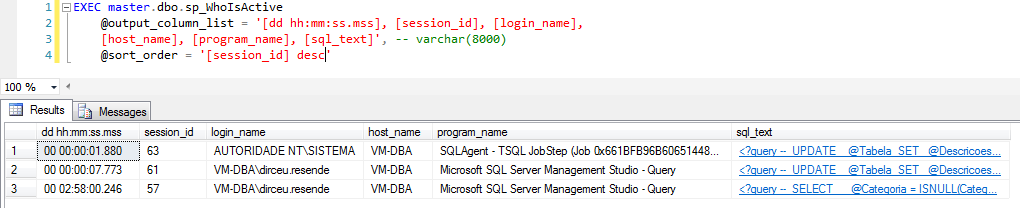
@formato_salida
Este parámetro se utiliza para cambiar la forma en que se muestran algunas columnas a un modo de lectura más "humano". Con un valor de 1, el formato de salida utilizará fuentes de longitud variable. Con un valor de 2, el formato de salida utilizará fuentes de longitud fija.
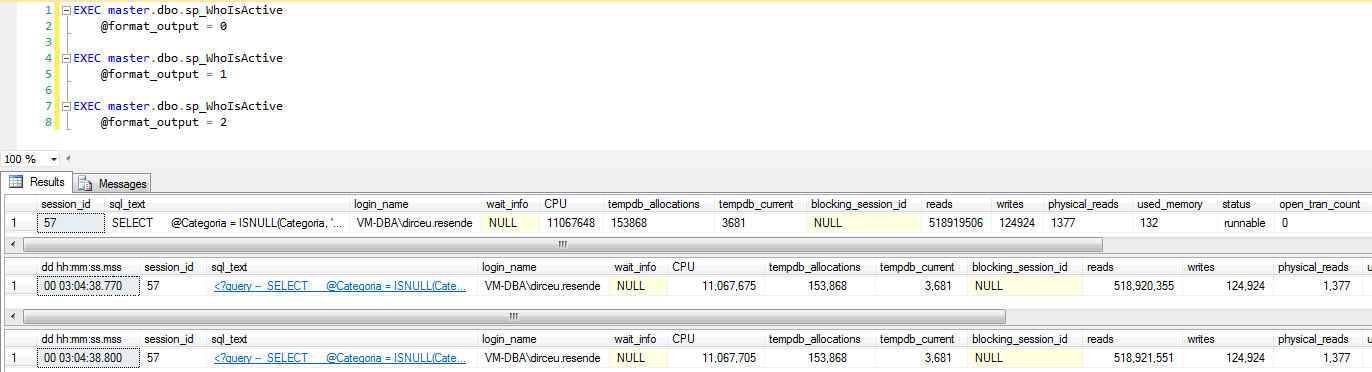
Para ser honesto, veo diferencias entre el valor 0 y 1, pero no veo diferencias entre los valores 1 y 2.
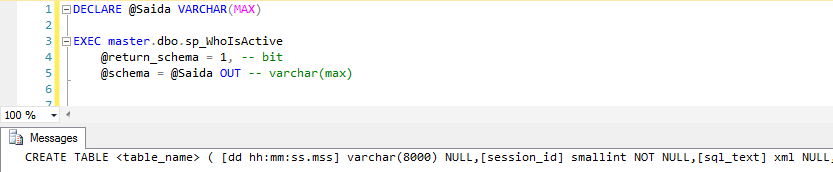
@return_schema y @schema
Estos parámetros juntos sirven para generar el script de creación de resultados del SP. El parámetro @return_schema, cuando se establece en 1, en lugar de devolver el resultado de la ejecución, genera el script CREATE TABLE para el resultado. Este script debe leerse usando una variable OUTPUT en el parámetro @schema, como se muestra a continuación:
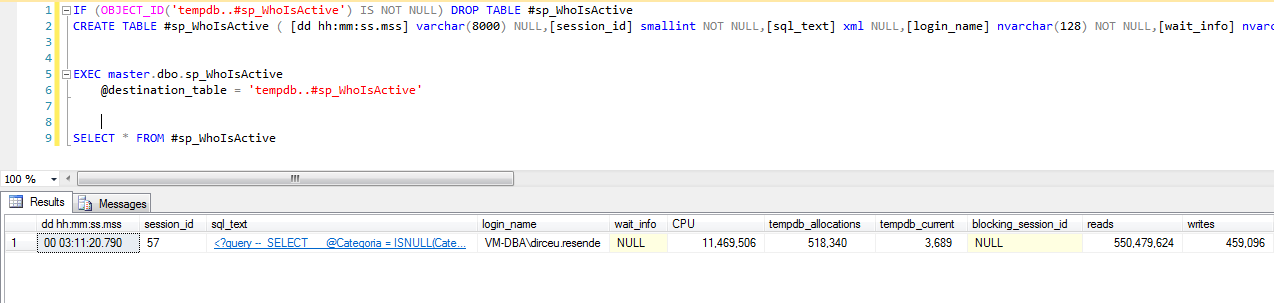
@mesa_destino
Y por último, tenemos el parámetro @destination_table. Se utiliza para insertar el resultado de la ejecución del SP en una tabla física, donde podemos almacenar el historial y consultarlo cuando queramos.
Para utilizar este parámetro se debe crear previamente la tabla, ya que este parámetro solo insertará los datos, no creará la tabla. Para obtener el comando CREATE TABLE resultante de la ejecución de este SP, basta con mirar los parámetros explicados anteriormente (@return_schema y @schema) para hacerlo de forma sencilla y en unos segundos.
¡Eso es todo amigos!
Espero que esta publicación te sea útil.

Comentários (0)
Carregando comentários…