¡Hola, chicos! ¿Cómo estás?
Hoy vamos a profundizar en uno de los temas que más dudas genera en la mente de quienes inician el camino de la modernización de datos en Microsoft Azure: elegir el modelo de compra de Azure SQL Database.
Si ya abrió Azure Portal, es posible que se haya encontrado con una sopa de letras: DTU, núcleo virtual, Básico, Estándar, Propósito general, Base de datos única, Piscina Elástica, hiperescala, Sin servidor, Piscina Elástica…
La lista es larga y elegir el modelo equivocado puede significar pagar mucho más por un recurso innecesario y/o sufrir problemas de rendimiento porque el cuello de botella de IOPS o CPU está tocando el techo de una capa de servicio que no fue bien planificada para esa carga de trabajo.
Cuando surgió Azure SQL Database, Microsoft necesitaba llegar a dos audiencias completamente diferentes al mismo tiempo: desarrolladores que solo querían una base de datos funcional y administradores de bases de datos que estaban acostumbrados a pensar en CPU, memoria, disco y latencia y querían la flexibilidad para elegir los componentes de hardware de la base de datos.
En esta publicación, analizaremos las diferencias técnicas, comprenderemos la arquitectura detrás de cada nivel y, por supuesto, le proporcionaremos un script para que sepa exactamente cuál es el equivalente de vCore para su banco que actualmente se ejecuta en DTU.
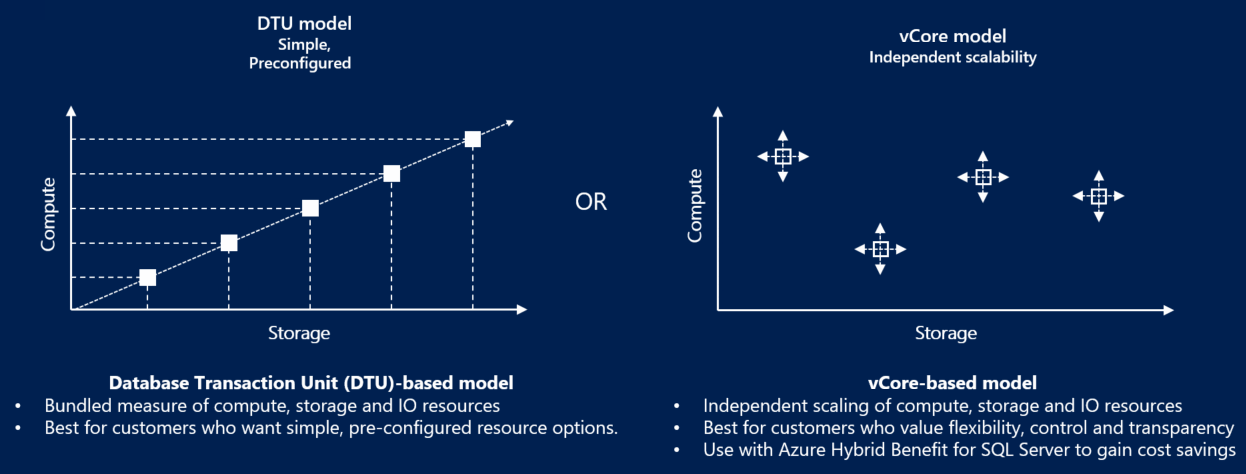
¿Qué es el Modelo DTU (Unidad de Transacción de Base de Datos)?
El modelo basado en DTU fue el primero en publicarse en Azure SQL Database y es del tipo Base de datos única. La idea de Microsoft era simplificar la vida de los DBA y los desarrolladores: en lugar de preocuparse por cuántos núcleos de procesador, cuántos IOPS tendrá el disco o cuánta RAM necesita el banco, se compra una “unidad de medida” que representa la potencia computacional.
Uno DTU es una mezcla equilibrada de UPC, Memoria y Lectura/escritura de datos (E/S) basado en un punto de referencia interno de Microsoft que simula una carga de trabajo OLTP genérica, con lectura, escritura, uso de CPU y generación de registros de transacciones.
Cuando compras DTU, no estás comprando CPU, ni memoria, ni IOPS individualmente. Estás comprando una porción de este paquete cerrado.
En la práctica, esto significa que si su aplicación está limitada a la CPU, alcanzará el límite de la CPU antes que nada. Si está vinculado a E/S, alcanzará IOPS. Si tiene muchos registros, el cuello de botella aparece como WRITELOG. Y lo que es peor: no puedes reasignar recursos dentro del paquete. Si tiene mucha memoria pero le falta CPU, tendrá que aumentar el nivel del banco, lo que aumentará la CPU, la memoria y el disco, incluso si no necesita aumentar la memoria y el disco, por ejemplo.
Niveles de servicio en el modelo DTU
- Básico: Es el nivel más simple posible, que cuesta USD 4,90 mensuales, donde el límite de tamaño de la base de datos es de sólo 2 GB y la potencia de procesamiento es mínima. Fue diseñado para escenarios extremadamente livianos, pruebas de concepto, demostraciones y aplicaciones muy pequeñas. Los IOPS son muy bajos, la latencia es alta y cualquier pico de carga se convierte rápidamente en un cuello de botella. No es un nivel para una producción seria.
- Estándar: Aquí es donde comienzan la mayoría de las empresas, donde el costo mensual comienza en USD 17,81 con hasta 250 GB de almacenamiento (nivel S0) y puede escalar hasta un costo mensual de USD 5606,43 con 1 TB de almacenamiento (nivel S12). En este nivel, si asignas 1 GB o 250 GB, pagarás exactamente la misma cantidad. A partir de 250 GB, todo lo que supere este tamaño generará un cargo. Proporciona un rendimiento predecible para aplicaciones pequeñas y medianas y proyectos de datos pequeños. El almacenamiento sigue siendo remoto, el registro puede convertirse fácilmente en un cuello de botella y las cargas de trabajo más agresivas comienzan a sufrir latencia de E/S y WRITELOG.
- De primera calidad: Enfocado a aplicaciones de misión crítica, donde el costo mensual comienza en USD 552,12 con hasta 500 GB de almacenamiento ya incluido (nivel P1), llegando hasta USD 19081,25 y 4 TB de almacenamiento (nivel P15). En Business Critical, tienes IOPS significativamente mayor, baja latencia (SSD local) y soporte Leer escalamiento horizontal (una réplica de lectura gratuita) para consultas e informes pesados sin afectar el nodo principal donde se ejecuta la aplicación. Premium DTU y Business Critical vCore utilizan arquitecturas muy similares.
En la capa de servicio DTU, el banco utiliza redundancia de hardware local (LRS), con un SLA típico del 99,99%, donde su banco tiene réplicas en el mismo centro de datos, pero si hay alguna indisponibilidad en ese centro de datos, su banco no estará disponible.
¿Qué es el modelo vCore (Núcleo virtual)?
el modelo núcleo virtual, que también es del tipo Base de Datos Única, fue creado para brindar transparencia. Está mucho más cerca de lo que estamos acostumbrados en el medio ambiente. Local. En él, usted elige específicamente la generación del hardware, el número de núcleos virtuales (vCores) y la cantidad de memoria está vinculada a esta elección (generalmente una proporción fija por núcleo).
Con vCore, puede comprender exactamente si el banco está vinculado a la CPU, a la memoria o a las E/S. Puede planificar el crecimiento, estimar costos, comparar con el sistema local y, lo más importante, justificar técnicamente cada centavo gastado. A cambio, se pierde la simplicidad de DTU y se asume la responsabilidad de diseñar correctamente.
La gran ventaja aquí, además de la transparencia, es la posibilidad de utilizar el Beneficio híbrido de Azure (AHB), que le permite utilizar sus licencias de SQL Server que ya tiene (con Software Assurance) para pagar mucho menos en PaaS.
Niveles de servicio en el modelo vCore
- Propósito general: Capa de entrada para vCore e ideal para aplicaciones empresariales comunes, siempre que no sean muy sensibles a la latencia de E/S. El costo mensual inicial parte desde USD 568,48 con 2 vCores 1 GB de almacenamiento, ampliable hasta 1 TB y puede llegar a USD 37483,51 con 128 vCores y 4 TB de almacenamiento. El almacenamiento y la computación están separados. El registro de transacciones y los datos se encuentran en Azure Premium Storage, lo que puede dar como resultado una latencia de E/S ligeramente mayor en comparación con Business Critical.
- Propósito general (sin servidor): Variante de uso general donde el cálculo se escala automáticamente según el uso, lo que permite pausa automática del banco cuando está inactivo y facturación por núcleo virtual por segundo. Ideal para cargas de trabajo intermitentes, entornos de desarrollo, QA y aplicaciones con uso esporádico, reduciendo drásticamente el costo cuando la base de datos no está en uso. Tiene arranque en frío al reiniciarse y no es adecuado para sistemas OLTP críticos o cargas de trabajo 24×7.
- Crítico para el negocio: Alto rendimiento y alta disponibilidad, con costos mensuales desde USD 1392,62 por 1 GB de almacenamiento, llegando hasta USD 91520,22 mensuales, con 128 vCores y 4 TB de almacenamiento. Al igual que con Premium (DTU), los datos se almacenan en SSD locales (NVMe), garantizando una latencia muy baja y replicando los datos internamente vía Always On en 3 réplicas, además de soporte para Leer escalamiento horizontal, donde 1 de las 3 réplicas locales permite lecturas para ejecutar consultas e informes pesados sin afectar el nodo principal donde se ejecuta la aplicación. Ideal para bancos con un alto volumen de ESCRIBIR REGISTRO y es el nivel adecuado para sistemas críticos, OLTP pesado y bancos que sufren de WRITELOG y PAGEIOLATCH.
- Hiperescala: La arquitectura más moderna, con costos mensuales desde USD 506,70 por 1 réplica de alta disponibilidad, llegando hasta USD 101339,77 mensuales, con 80 vCores y 4 réplicas de alta disponibilidad. Permite bancos de hasta 128 TB en Single Database (y 100 TB en Elastic Pool). Separa el motor de consultas del motor de almacenamiento, lo que permite un escalado casi instantáneo independientemente del tamaño de los datos, lo que permite un crecimiento de datos prácticamente ilimitado. No es automáticamente más rápido que Business Critical. Es mejor cuando el problema es el tamaño y el crecimiento, no la pura latencia.
- Hiperescala (sin servidor): Variante de hiperescala (la disponibilidad depende de la región) donde la computación escala automáticamente y el banco puede pausarse automáticamente cuando está inactivo, cobrando por núcleo virtual por segundo. Mantiene toda la arquitectura distribuida Hiperescala (Servidores de Páginas + Servicio de Registro), permitiendo bancos de hasta 128 TB a un costo extremadamente reducido en cargas de trabajo intermitentes o con largos periodos de inactividad. Tiene un arranque en frío al reiniciarse y no es adecuado para cargas de trabajo críticas 24×7 que requieren una latencia mínima constante.
Comparación gráfica:
Redundancia local (LRS) y redundancia de zona (ZRS)
Al igual que en la capa de servicio DTU, en los modelos vCore la opción predeterminada es usar redundancia de hardware local (LRS), con un SLA típico del 99,99%, su banco tiene réplicas en el mismo centro de datos, pero si hay alguna indisponibilidad en ese centro de datos, su banco no estará disponible.
A diferencia de DTU, en vCore también es posible elegir redundancia de zona (ZRS), repartida en 3 centros de datos diferentes (3 zonas de disponibilidad), con un SLA del 99,995%. Esto significa que sus datos se almacenan simultáneamente en 3 zonas físicas separadas, cada una con alimentación, red y refrigeración independientes. Si todo un centro de datos deja de funcionar, Azure promueve otra réplica y su aplicación sigue ejecutándose.
ZRS ofrece mayor SLA y tolerancia a fallas del centro de datos, pero a un costo adicional del 10 al 20 %, escrituras ligeramente más lentas y una latencia ligeramente mayor.
Capacidad reservada (reserva de vCores)
En el modelo vCore es posible contratar una reserva de 1 o 3 años, reduciendo drásticamente el coste mensual, cosa que no ocurre en el modelo DTU.
Con vCore no “alquila por horas para siempre”: puede comprar capacidad de CPU (vCores) por adelantado durante 1 o 3 años y, a cambio, Microsoft le ofrece descuentos agresivos en el valor de la computación, alcanzando hasta un 33 % de descuento con una reserva de 1 año, un 55 % de descuento con una reserva de 3 años y un 70-80 % de descuento con una reserva de 3 años + Beneficio híbrido de Azure (AHB).
En la práctica, no reserva un banco, reserva tantos vCores como desee en una región. Estos núcleos virtuales permanecen como crédito y cualquier núcleo virtual de Azure SQL que tenga en esa región consume estos créditos automáticamente. En otras palabras, no pierdes flexibilidad y puedes mover de banco, cambiar de nivel, de escala y el crédito sigue.
Comparación directa: DTU vs vCore
Para facilitarte la toma de decisiones, preparé esta tabla comparativa que muestra dónde brilla cada modelo:
| Característica | modelo DTU | modelo de núcleo virtual |
|---|---|---|
| Mejor uso para | Simplicidad y previsibilidad de bajos costos. | Control granular, escalabilidad y ahorro de licencias. |
| Configuración de hardware | Resumen (no eliges el procesador). | Especificable (Gen5, Fsv2, M-Series, etc.). |
| Escalabilidad del almacenamiento | Vinculado al nivel DTU. | Independiente (puedes aumentar el disco sin aumentar la CPU). |
| Beneficio híbrido de Azure | No disponible. | Disponible (hasta un 55% de ahorro). |
| Leer replicación | Disponible sólo en Premium. | Disponible en críticos para el negocio e hiperescala. |
Azure SQL Database sin servidor (vCore sin servidor)
EL Sin servidor no es un nuevo tipo de base de datos, sino más bien un modo especial del modelo vCore, disponible en los niveles de Propósito General e Hiperescala, donde Microsoft administra automáticamente la cantidad de CPU activa, escalando hacia arriba y hacia abajo dinámicamente según la carga de trabajo.
A diferencia de los núcleos virtuales aprovisionados, donde usted paga por los núcleos virtuales fijos las 24 horas del día, los 7 días de la semana, en Serverless usted paga por CPU utilizada por segundo y almacenamiento, lo que puede reducir drásticamente el costo de las cargas de trabajo intermitentes.
Características principales
- Escala automática de CPU: Azure aumenta y reduce automáticamente la cantidad de núcleos virtuales según el uso real del banco.
- Pausa automática: Si la base de datos está inactiva durante un período configurable (mínimo 1 hora), se puede pausar automáticamente y usted deja de pagar por el cálculo y solo paga por el almacenamiento de datos.
- Arranque en frío: Al recibir una nueva conexión después de haber sido pausada, el banco se reactiva automáticamente (entre 30 y 90 segundos en promedio).
- Sin tiempo de inactividad al escalar: La ampliación/reducción de escala se produce en línea, sin tiempo de inactividad.
Costos
- Paga por segundo de núcleo virtual activo, no por núcleo virtual aprovisionado.
- Durante la pausa automática, solo paga por el almacenamiento y las copias de seguridad.
- Ideal para cargas de trabajo que están inactivas la mayor parte del tiempo, como cargas en entornos D-1 que no tienen lecturas durante el día.
¿Cuándo vale la pena usar Serverless?
- Entornos de desarrollo, aprobación y control de calidad.
- Aplicaciones de uso esporádico (intranet, backoffice, SaaS de pocos accesos).
- API con tráfico intermitente.
- Cargas que permanecen inactivas durante largos periodos.
- Proyectos con una fuerte preocupación por el coste.
- Grandes bancos de hiperescala que están inactivos la mayor parte del tiempo.
Cuándo NO usar Serverless
- Sistemas críticos y OLTP 24×7.
- Cargas de trabajo sensibles a la latencia de conexión (arranque en frío).
- ETL frecuentes, continuos o por lotes.
- Bancos que necesitan previsibilidad total del rendimiento.
Cambiar el nivel de servicio entre DTU y vCore
Importante: Existen pocas limitaciones al cambiar entre niveles, incluso entre diferentes modelos (DTU y vCore), es decir, puede migrar de DTU Basic a un vCore Business Critical y luego volver a un vCore General Purpose o DTU Standard, por ejemplo.
Sin embargo, hay que tener cuidado.
La barrera del tamaño (tamaño máximo de almacenamiento)
El primer punto de atención es el límite de almacenamiento físico. Cada nivel de servicio tiene un límite máximo de GB admitidos. Si su base de datos ha crecido más allá del límite del nivel de destino, Azure simplemente no le permitirá bajar de categoría o cambiar de modelo hasta que reduzca su volumen de datos o elija un nivel compatible.
Un ejemplo clásico: el nivel DTU Basic está limitado a 2 GB. Si tu banco tiene 5 GB en un nivel Estándar S0 e intentas moverlo al Básico para guardar, la operación fallará.
Limitación de recursos del motor (características)
Aunque el motor de SQL Server es el mismo, Microsoft deshabilita algunas características dependiendo del nivel contratado en la capa de servicio DTU.
Los niveles inferiores, específicamente DTU Básico y Estándar en los niveles S0, S1 y S2, tienen restricciones en funciones como los índices de almacén de columnas y OLTP en memoria (XTP), que no están disponibles en estos niveles.
La hiperescala tiene reglas diferentes
La hiperescala no es solo un nivel superior, cambia completamente la arquitectura física del banco, donde el banco ya no existe como un MDF tradicional: los datos van al almacenamiento distribuido, los datos se replican internamente usando Log Service + Page Servers en lugar de AlwaysOn y el banco se convierte en un conjunto de fragmentos distribuidos.
Al migrar un banco a Hiperescala, tiene una ventana de aproximadamente 45 dias para volver a Propósito general o Crítico para el negocio manteniendo el mismo banco. Después de este período, ya no se permite la degradación directa y el retorno requiere una estrategia de migración de copia de datos.
Esto sucede porque Microsoft mantiene temporalmente una imagen compatible del banco en el formato antiguo. Durante aproximadamente 45 días, Azure aún puede volver a montar su base de datos en GP/BC. Posteriormente, el banco se convierte definitivamente al formato distribuido y a partir de ese momento el MDF tradicional deja de existir.
Después de estos 45 días, ya no podrá pasar de Hiperescala a otro nivel o capa de servicios, el portal simplemente bloquea este cambio. Si realmente desea migrar a otra capa o nivel de servicio, tendrá que crear una nueva base de datos y migrar los datos mediante BACPAC, Replicación, SQLPackage u otra herramienta.
Tabla de disponibilidad de recursos (modelo DTU)
Para facilitar las cosas, preparé esta tabla rápida para que no cometas errores al planificar tu tier:
| Característica | Básico / S0 – S2 | Estándar S3 – S12 | Premium (Todos) |
|---|---|---|---|
| Índices de almacén de columnas | No compatible | Apoyado | Apoyado |
| OLTP en memoria | No compatible | No compatible | Apoyado |
| Tamaño máximo | 250 GB (S2) | 4TB (S3+) | 4TB |
Script de verificación de elementos impeditivos
Para evitar que lo tomen por sorpresa, preparé un script que debe ejecutar en su banco ANTES de intentar bajar a niveles más bajos. Comprueba si hay objetos que impiden pasar al mundo DTU Básico/Estándar de entrada.
-- VERIFICA RECURSOS E TAMANHO PARA DOWNGRADE (DTU BASIC / S0-S2)
IF ( OBJECT_ID( 'tempdb..#Tmp_Validacao_Downgrade' ) IS NOT NULL )
DROP TABLE [#Tmp_Validacao_Downgrade];
CREATE TABLE [#Tmp_Validacao_Downgrade] (
[Ds_Tipo_Validacao] VARCHAR(100) COLLATE SQL_Latin1_General_CP1_CI_AS,
[Nm_Referencia] VARCHAR(255) COLLATE SQL_Latin1_General_CP1_CI_AS,
[Ds_Mensagem] VARCHAR(500) COLLATE SQL_Latin1_General_CP1_CI_AS,
[Fl_Impeditivo] BIT
)
WITH ( DATA_COMPRESSION = PAGE );
-- 1. VALIDACAO DE TAMANHO (STORAGE)
DECLARE @Nr_Tamanho_Atual_Gb DECIMAL(10, 2);
SELECT
@Nr_Tamanho_Atual_Gb = CAST(SUM( [size] ) * 8. / 1024 / 1024 AS DECIMAL(10, 2))
FROM
[sys].[database_files]
WHERE
[type] = 0; -- SOMENTE DADOS (DATA)
-- VERIFICA LIMITE PARA BASIC (2 GB)
IF ( @Nr_Tamanho_Atual_Gb > 2.0 )
BEGIN
INSERT INTO [#Tmp_Validacao_Downgrade] ( [Ds_Tipo_Validacao], [Nm_Referencia], [Ds_Mensagem], [Fl_Impeditivo] )
VALUES
(
'Storage', 'Tier Basic', 'O banco possui ' + CAST(@Nr_Tamanho_Atual_Gb AS VARCHAR(10)) + ' GB. O limite do Basic e 2 GB.', 1
);
END;
-- VERIFICA LIMITE PARA S0-S2
IF ( @Nr_Tamanho_Atual_Gb > 250.0 )
BEGIN
INSERT INTO [#Tmp_Validacao_Downgrade] ( [Ds_Tipo_Validacao], [Nm_Referencia], [Ds_Mensagem], [Fl_Impeditivo] )
VALUES
(
'Storage', 'Tier S0-S2', 'O banco possui ' + CAST(@Nr_Tamanho_Atual_Gb AS VARCHAR(10)) + ' GB. Se tentar migrar para o tier DTU Standard S0-S2, vai dar erro.', 1
);
END;
-- 2. VALIDACAO DE INDICES COLUMNSTORE
INSERT INTO [#Tmp_Validacao_Downgrade] ( [Ds_Tipo_Validacao], [Nm_Referencia], [Ds_Mensagem], [Fl_Impeditivo] )
SELECT
'Feature' AS [Ds_Tipo_Validacao],
[A].[name] + '.' + [B].[name] AS [Nm_Referencia],
'Indices Columnstore requerem no minimo tier Standard S3' AS [Ds_Mensagem],
1 AS [Fl_Impeditivo]
FROM
[sys].[indexes] AS [A]
INNER JOIN [sys].[objects] AS [B] ON [A].[object_id] = [B].[object_id]
WHERE
[A].[type] IN ( 5, 6 );
-- 3. VALIDACAO DE IN-MEMORY OLTP
INSERT INTO [#Tmp_Validacao_Downgrade] ( [Ds_Tipo_Validacao], [Nm_Referencia], [Ds_Mensagem], [Fl_Impeditivo] )
SELECT
'Feature' AS [Ds_Tipo_Validacao],
[name] AS [Nm_Referencia],
'Tabelas em memoria requerem tier Premium ou Business Critical' AS [Ds_Mensagem],
1 AS [Fl_Impeditivo]
FROM
[sys].[tables]
WHERE
[is_memory_optimized] = 1;
-- EXIBE O RESULTADO FINAL
SELECT
[Ds_Tipo_Validacao],
[Nm_Referencia],
[Ds_Mensagem],
( CASE WHEN [Fl_Impeditivo] = 1 THEN 'SIM' ELSE 'NAO' END ) AS [Fl_Erro_Critico]
FROM
[#Tmp_Validacao_Downgrade];Cuando DTU tiene sentido
DTU tiene sentido cuando la simplicidad es más importante que el control. Entornos pequeños, aplicaciones sencillas, equipos sin un DBA dedicado o escenarios donde el banco no es crítico suelen beneficiarse del modelo DTU. Reduce las decisiones, reduce el error humano y ofrece algo suficientemente bueno sin requerir conocimientos arquitectónicos profundos.
En términos prácticos, cuando comienzas un nuevo proyecto, comenzar en DTU tiene mucho sentido, ya que puedes comenzar con un valor muy bajo y escalar a los siguientes niveles según sea necesario. Desde el nivel S6 en adelante, el costo alcanza los USD 712,44 y migrar al modelo vCore ahora tiene más sentido que mantener DTU.
¿Cuándo migrar de DTU a vCore?
¡La pregunta del millón! En mi experiencia, las señales de que debes alejarte de DTU y pasar a vCore son:
- Presión de la memoria (ligada a la memoria): Si sufres de esperas como RECURSO_SEMÁFORO, derrames del operador (Hash/Sort) o degradación de la caché y la DTU ya es alta. En vCore puedes controlar el ratio de memoria por núcleo, algo imposible en DTU.
- Latencia de almacenamiento (vinculada a IO): Si nota esperas recurrentes como PAGEIOLATCH_SH, ESCRIBIR REGISTRO o LOG_RATE_GOVERNOR. En vCore Business Critical o DTU Premium, los datos y el registro están en un SSD NVMe local, lo que reduce drásticamente la latencia de lectura y escritura, pero vCore BC puede tener una mejor relación costo-beneficio.
- Costo de la licencia: Si su empresa ya cuenta con licencias de SQL Server con Software Assurance, vCore le permite utilizar Beneficio híbrido de Azure y reducir el costo mensual hasta en un 55% (o hasta ~80% si se combina con reservas).
- Rendimiento y previsibilidad ETL: Si necesita garantizar la velocidad de registro (MB/s), IOPS o un rendimiento estable para cargas ETL, integraciones o procesos por lotes que hoy sufren de gobernanza interna de DTU.
- Tamaño y crecimiento del banco: Si tu banco empieza a acercarse 300–500 GB, o dirigiéndose hacia el límite de 1 TB de los niveles Estándar, vCore se convierte en la opción natural, ya que permite el crecimiento independiente del almacenamiento y el acceso a Hiperescala.
- Verdadera alta disponibilidad (ZRS): Si el banco es crítico y necesita sobrevivir a la caída de un centro de datos completo, solo vCore permite el almacenamiento con redundancia de zona (ZRS) con un SLA del 99,995 %.
- Escala de datos masiva (Hiperescala): Solo vCore permite bancos de más de 4 TB, alcanzando hasta 128 TB con escalabilidad de lectura y restauraciones casi instantáneas.
- Verdadero paralelismo y control de CPU: vCore proporciona CPU real y maxDOP al mismo tiempo que evita los límites estrictos e impredecibles de DTU.
Script T-SQL para comparar el nivel DTU con el nivel vCore del banco Azure actual
Muchos administradores de bases de datos se pierden al convertir “X DTU” en “Y vCores”. Para resolver esto, preparé un script que analiza los DMV de su base de datos actual y sugiere la configuración de vCore y DTU según el hardware que está ejecutando en Azure.
Debido a que DTU oculta la CPU, la memoria y las E/S dentro de un paquete cerrado, Azure no le indica claramente cuánto hardware tiene realmente detrás. Este script abre la caja negra de la DTU y traduce su base de datos actual en números de infraestructura reales.
Este script estima cuántos “núcleos lógicos” tiene su banco hoy, cuánta memoria total tiene realmente disponible el banco y en qué generación de hardware (Gen4 o Gen5) se está ejecutando el banco. A partir de esto, genera From x To, que muestra cuántos núcleos virtuales se necesitarían para alcanzar algo equivalente en el modelo de núcleo virtual, y no solo en un hardware, sino en varias familias diferentes: Gen4, Gen5, Fsv2 (vinculado a CPU) y M-Series (vinculado a memoria). Para cada uno de ellos, el guión también estima cuánta memoria tendría ese entorno, lo que facilita la elección de la familia correcta.
Finalmente, el script también sugiere qué nivel de núcleo virtual tiene más sentido desde el punto de vista arquitectónico para su banco (propósito general, crítico para el negocio o hiperescala), según el nivel de DTU actual, y sirve como guía de migración inicial.
-- https://docs.microsoft.com/en-us/azure/azure-sql/database/migrate-dtu-to-vcore
WITH dtu_vcore_map
AS (
SELECT
rg.server_name,
rg.[database_name],
rg.slo_name,
rg.dtu_limit,
rg.volume_local_iops,
rg.pool_max_io,
rg.max_dop,
rg.max_sessions,
DATABASEPROPERTYEX( DB_NAME(), 'Edition' ) AS dtu_service_tier,
DATABASEPROPERTYEX( DB_NAME(), 'ServiceObjective' ) AS [service_objective],
DATABASEPROPERTYEX( DB_NAME(), 'Updateability' ) AS updateability,
(CASE
WHEN rg.slo_name LIKE '%SQLG4%' OR rg.slo_name LIKE '%GPGen4%' THEN 'Gen4'
WHEN rg.slo_name LIKE '%SQLGZ%' OR rg.slo_name LIKE '%GPGenZ%' THEN 'Gen4'
WHEN rg.slo_name LIKE '%SQLG5%' OR rg.slo_name LIKE '%GPGen5%' THEN 'Gen5'
WHEN rg.slo_name LIKE '%SQLG6%' OR rg.slo_name LIKE '%GPGen6%' THEN 'Gen5'
WHEN rg.slo_name LIKE '%SQLG7%' OR rg.slo_name LIKE '%GPGen7%' THEN 'Gen5'
WHEN rg.slo_name LIKE '%SQLG8%' OR rg.slo_name LIKE '%GPGen8%' THEN 'Gen5'
END
) AS dtu_hardware_gen,
CAST(rg.dtu_limit / 100. AS DECIMAL(6, 2)) AS dtu_logical_cpus,
CAST((jo.process_memory_limit_mb / s.scheduler_count) / 1024. AS DECIMAL(6, 2)) AS dtu_memory_per_core_gb
FROM
sys.dm_user_db_resource_governance AS rg
CROSS JOIN (SELECT COUNT( 1 ) AS scheduler_count FROM sys.dm_os_schedulers WHERE [status] = 'VISIBLE ONLINE') AS s
CROSS JOIN sys.dm_os_job_object AS jo
WHERE
rg.dtu_limit > 0
AND DB_NAME() <> 'master'
AND rg.database_id = DB_ID()
)
SELECT
server_name AS ServerName,
[database_name] AS DatabaseName,
dtu_service_tier AS ServiceTier,
[service_objective] AS ServiceObjetive,
dtu_limit AS DTUs,
volume_local_iops AS IOPS,
pool_max_io AS ElasticPoolMaxIO,
max_dop AS [MaxDOP],
max_sessions AS MaxSessions,
dtu_hardware_gen AS HardwareGeneration,
(CASE
WHEN dtu_service_tier = 'Basic' THEN 'General Purpose'
WHEN dtu_service_tier = 'Standard' THEN 'General Purpose or Hyperscale'
WHEN dtu_service_tier = 'Premium' THEN 'Business Critical or Hyperscale'
END
) AS vCoreRecommendedTier,
dtu_logical_cpus AS CPUs,
CEILING( dtu_memory_per_core_gb * dtu_logical_cpus ) AS MemoryInGB,
(CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus WHEN dtu_hardware_gen = 'Gen5' THEN dtu_logical_cpus * 0.7 END) AS vCoresNeededForGen4,
CEILING((CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus WHEN dtu_hardware_gen = 'Gen5' THEN dtu_logical_cpus * 0.7 END) * 7 ) AS MemoryNeededForGen4,
(CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.7 WHEN dtu_hardware_gen = 'Gen5' THEN dtu_logical_cpus END) AS vCoresNeededForGen5,
CEILING((CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.7 WHEN dtu_hardware_gen = 'Gen5' THEN dtu_logical_cpus END) * 5.05 ) AS MemoryNeededForGen5,
(CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus WHEN dtu_hardware_gen = 'Gen5' THEN dtu_logical_cpus * 0.8 END) AS vCoresNeededForFsv2,
CEILING((CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus WHEN dtu_hardware_gen = 'Gen5' THEN dtu_logical_cpus * 0.8 END) * 1.89 ) AS MemoryNeededForFsv2,
(CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.4 WHEN dtu_hardware_gen = 'Gen5' THEN dtu_logical_cpus * 0.9 END) AS vCoresNeededForM,
CEILING((CASE WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.4 WHEN dtu_hardware_gen = 'Gen5' THEN dtu_logical_cpus * 0.9 END) * 29.4 ) AS MemoryNeededForM
FROM
dtu_vcore_map;Análisis de rendimiento y tipos de espera
Al monitorear el rendimiento en Azure SQL Database, independientemente del modelo, debe tener en cuenta Tipos de espera. Son la brújula del DBA.
- INSTANCE_AND_RESOURCES_GOVERNOR: Si ve este tipo de espera, Azure está limitando su base de datos debido al nivel contratado. Es una señal clara de que necesita una actualización (más DTU o más núcleos virtuales).
- LOG_RATE_GOVERNOR: Indica que ha alcanzado el límite de rendimiento del registro de transacciones. En vCore, cada nivel tiene un límite de registro de MB/s. Si tu proceso INSERTAR/ACTUALIZAR el volumen es lento, el cuello de botella podría estar aquí.
- ESCRIBIR REGISTRO: Común en niveles Estándar o Propósito general, donde el almacenamiento no es local. Si este tiempo de espera es alto, considere pasar a Premium o Business Critical.
Azure SQL Database no ofrece recursos ilimitados. Cada nivel tiene límites internos de CPU, IO, velocidad de registro, sesiones y trabajadores. Al alcanzar estos límites, el motor comienza a aplicar gobernanza, provocando esperas como LOG_RATE_GOVERNOR e INSTANCE_AND_RESOURCES_GOVERNOR.
Lectura escalada (réplica de lectura nativa)
los niveles DTU Prima y Núcleo virtual crítico para el negocio ofrecer el recurso Leer ampliación horizontal, que proporciona una réplica de lectura nativa, síncrona y automática, creado por la propia Azure SQL Database, sin coste adicional (ya incluido en el precio, de hecho).
Esta réplica utiliza la arquitectura Always On, manteniendo una sólida coherencia (sin retrasos notables) y permitiéndole descargar consultas de BI, informes, paneles y API de lectura desde la réplica principal, sin afectar el rendimiento de escritura.
El acceso a la réplica de lectura se realiza simplemente agregando el siguiente parámetro a la cadena de conexión:
AplicaciónIntent=Solo lectura
A diferencia de las replicaciones tradicionales, Read Scale-out no requiere configuración, no tiene complejidad operativa, participa automáticamente en mecanismos de conmutación por error y garantiza que las consultas de lectura siempre vean los datos actualizados en tiempo real.
Cuando se produce una conmutación por error, Read Scale-out se comporta de manera completamente diferente a una réplica tradicional. En arquitecturas con replicación clásica (replicación transaccional, siempre activada configurada manualmente, réplica de Azure SQL), la aplicación necesita cambiar la cadena de conexión para que apunte al nuevo primario. En Read Scale-out, Azure promueve automáticamente una de las réplicas a principal y vuelve a crear la réplica de lectura de forma transparente, manteniendo el mismo punto final lógico. Esto significa que no se requieren cambios en la cadena de conexión y que tanto las conexiones de escritura como de lectura continúan funcionando normalmente después de la conmutación por error.
Copias de seguridad y retención (PITR/LTR)
Azure SQL Database mantiene copias de seguridad automáticas de todas las bases de datos, incluidas las completas, diferenciales y de registro de transacciones, lo que permite la restauración en cualquier momento (PITR – Point in Time Restore) dentro del período de retención configurado.
Por defecto, todos los bancos tienen 7 días de retención PITR, que pueden ampliarse hasta 35 días. Estas copias de seguridad se almacenan en un almacenamiento administrado por Azure y forman parte del costo estándar del servicio solo hasta el límite de retención estándar.
Retención de PITR (corto plazo)
- La retención estándar (7 días) está incluida en el costo del banco.
- Cualquier retención más allá de este período (de 8 a 35 días) genera cargos de almacenamiento adicionales.
- El valor se calcula en base a la tamaño total del banco y el volumen de registros generados.
En bancos con más de unos pocos cientos de GB, extender la retención de PITR de 7 a 35 días puede agregar fácilmente cientos o miles de dólares al mes en costos de almacenamiento invisibles.
Retención a largo plazo (LTR)
La LTR se utiliza para requisitos legales y auditorías, lo que le permite conservar copias completas del banco durante semanas, meses o años.
- Puede configurar retenciones semanales, mensuales y anuales.
- Las copias de seguridad LTR se cobran en su totalidad como almacenamiento de copias de seguridad.
- El costo crece linealmente con el tamaño del banco y el número de copias mantenidas.
Diferencia de costos por nivel y arquitectura
- Propósito general de DTU y vCore: Las copias de seguridad se almacenan en Azure Premium Storage remoto, con un costo proporcional al tamaño total de la base de datos.
- Núcleo virtual crítico para el negocio: Aunque los datos se almacenan en un SSD local, las copias de seguridad continúan almacenándose en un almacenamiento remoto y siguen el mismo modelo de facturación.
- Hiperescala: Tiene el mayor impacto potencial, ya que el banco puede alcanzar decenas de TB y las copias de seguridad (incluidos PITR y LTR) siguen este crecimiento y pueden superar fácilmente el costo informático.
Ejemplo real de impacto financiero
Un banco de 2 TB con retención de PITR extendida a 35 días y LTR configurado para mantener 12 copias de seguridad mensuales puede generar fácilmente un costo de copia de seguridad adicional estimado de USD 600 ~ 1000/mes en LRS/ZRS y USD 1200 ~ 2100/mes en GRS/GZRS, y puede ser incluso mayor en bancos de hiperescala de más de 10 TB.
Piscina Elástica
Elastic Pool es un modelo de uso compartido de recursos de Azure SQL Database en el que varias bases de datos consumen un grupo común de CPU y E/S, manteniendo la gestión de la memoria individual por banco (grupo de búfer separado), en lugar de que cada banco tenga recursos totalmente dedicados.
En el modelo DTU, Elastic Pool utiliza eDTU (DTU elásticas). Aunque la nomenclatura es equivalente, el modelo de gobernanza del pool significa que, en la práctica, se necesitan más eDTU para ofrecer el mismo rendimiento que una base de datos única en DTU.
como funciona
- El grupo tiene un total de núcleos virtuales o eDTU compartidos.
- Cada banco tiene límites mínimos y máximos configurables.
- Azure distribuye dinámicamente CPU y E/S entre bancos.
- Los bancos inactivos dan recursos a los bancos que están siendo utilizados.
Limitaciones y particularidades de Elastic Pool
- Elastic Pool tiene un límite de almacenamiento global compartido entre todos los bancos.
- Las consultas entre bases de datos solo funcionan entre bases de datos que están en el mismo grupo y servidor lógico (la base de datos única no tiene esta característica).
- El almacén de columnas solo se admite a partir del nivel S3/300 eDTU.
- Funciones como OLTP en memoria y tablas optimizadas para memoria no se admiten en grupos elásticos.
- Las cargas de trabajo con uso intensivo de registros (WRITELOG) sufren más gobernanza que las bases de datos de base de datos única.
Cuando Elastic Pool tiene sentido
- Entornos multiinquilino con cientos o miles de bancos (creando múltiples grupos, ya que cada grupo admite hasta 500 bancos).
- Aplicaciones SaaS con uso impredecible por cliente.
- Bancos pequeños que están inactivos la mayor parte del tiempo.
- Escenarios donde el costo individual por banco se vuelve prohibitivo.
Cuándo NO utilizar Elastic Pool
- Bancos con picos simultáneos constantes.
- Cargas de trabajo predecibles sensibles a la latencia y WRITELOG.
- Bancos críticos que necesitan un rendimiento mínimo garantizado por el banco.
Grupo elástico y núcleo virtual
- Existe en DTU y vCore, pero vCore es donde tiene más sentido, ya que permite Azure Hybrid Benefit, reservas y una arquitectura moderna.
- En vCore, los grupos existen en Propósito general y Crítico para el negocio.
- Existen grupos de hiperescala, pero el modelo más común y eficiente para SaaS masivo es el grupo de propósito general.
Conclusión
La elección entre DTU y vCore no es sólo una cuestión de precio, sino de estrategia arquitectónica, gobernanza y evolución de la plataforma. El modelo DTU es fantástico por su simplicidad y baja fricción operativa, mientras que vCore ofrece la solidez, previsibilidad y transparencia necesarias para entornos que ya se comportan como infraestructura crítica, además de facilitar el análisis de capacidad y la planificación financiera para las migraciones desde entornos locales a Azure SQL Database.
Si estás iniciando un proyecto nuevo, pequeño o con un uso impredecible, DTU Standard funciona muy bien y te permite crecer de forma sencilla. Si necesita una latencia de disco mínima, una alta tasa de registro y coherencia en el rendimiento, la ruta correcta es vCore Business Critical. Si su banco crece rápidamente o necesita superar los límites de tamaño tradicionales, Hyperscale se convierte en una decisión arquitectónica, no solo una elección de nivel.
Para entornos con uso intermitente, desarrollo, aprobación y cargas de trabajo que están inactivas la mayor parte del tiempo, vCore Serverless ofrece el menor costo posible sin renunciar a los recursos de la plataforma. Para las empresas que cuentan con Software Assurance, vCore con Azure Hybrid Benefit y reservas representa un ahorro estructural que el modelo DTU simplemente no puede ofrecer.
Para aplicaciones SaaS y escenarios multiinquilino con docenas o cientos de bancos, con picos de uso variables y no competitivos, Elastic Pool es la forma más eficiente de consolidar costos y capacidad, permitiéndole escalar docenas de bancos sobre el mismo conjunto de recursos compartidos.
En resumen: DTU es una excelente puerta de entrada. vCore es el camino natural hacia la madurez.
Espero que te haya gustado este tip, un fuerte abrazo y ¡hasta la próxima!

Comentarios (0)
Cargando comentarios...