¡Hola, chicos!
¿Todo muy bien?
En la publicación de hoy, voy a compartir con ustedes una investigación que he estado haciendo desde hace algún tiempo sobre las nuevas características de SQL Server en cada versión, con un enfoque en los desarrolladores de consultas y las rutinas de bases de datos. En los entornos en los que trabajo veo que muchos acaban “reinventando la rueda” o creando funciones UDF para realizar determinadas tareas (que sabemos que son pésimas para el rendimiento) cuando el propio SQL Server ya proporciona soluciones nativas para esto.
Mi objetivo en esta publicación es ayudarlo a usted, que está utilizando versiones antiguas de SQL Server, a evaluar las ventajas y nuevas características (solo desde la perspectiva del desarrollador) a las que tendrá acceso al actualizar su SQL Server.
SQL Server: ¿Qué cambió en T-SQL en la versión 2012?
Paginación de datos con OFFSET y FETCH
Ver contenidoCon la aparición de ROW_NUMBER() en SQL Server 2005, muchas personas comenzaron a utilizar esta función para crear paginación de datos, trabajando así:
DECLARE
@Pagina INT = 5,
@ItensPorPagina INT = 10
SELECT *
FROM (
SELECT [name], ROW_NUMBER() OVER(ORDER BY [name]) AS Ranking
FROM sys.objects
) A
WHERE
A.Ranking >= ((@Pagina - 1) * @ItensPorPagina) + 1
AND A.Ranking < (@Pagina * @ItensPorPagina) + 1
Resultado:
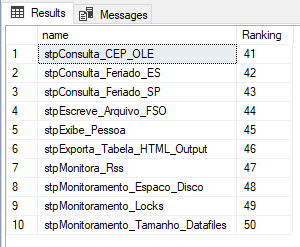
Sin embargo, a partir de SQL Server 2012, tenemos la funcionalidad de paginación nativa en el propio SQL Server, que muchas personas terminan por no utilizar por falta de conocimiento. Estamos hablando de las funciones OFFSET y FETCH, que funcionan juntas para permitirnos paginar nuestros resultados antes de mostrarlos y enviarlos a aplicaciones y clientes.
Mira cómo se usa, es simple:
SELECT [name]
FROM sys.objects
ORDER BY [name]
OFFSET 40 ROWS -- Linha de início: Vai começar a retornar a partir da linha 40
FETCH NEXT 10 ROWS ONLY -- Quantidade de linhas para retornar: Vai retornar as próximas 10 linhas
Resultado:
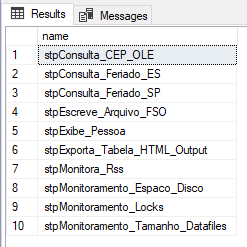
Si quieres saber más sobre esta función, asegúrate de visitar mi artículo. SQL Server – Cómo crear paginación de datos en los resultados de una consulta con OFFSET y FETCH
Secuencias
Ver contenidoEjemplo clásico: tablas Pessoa_Fisica y Pessoa_Juridica. Si usas IDENTITY para generar un secuencial, las 2 tablas tendrán un registro con ID = 25, por ejemplo. Si usas una sola secuencia para controlar el ID de estas dos tablas, el ID = 25 solo existirá en una de las dos tablas, funcionando así:
Código fuente de prueba
CREATE SEQUENCE dbo.[seq_Pessoa]
AS [INT]
START WITH 1
INCREMENT BY 1
MINVALUE 1
MAXVALUE 999999999
CYCLE
CACHE
GO
CREATE TABLE dbo.Pessoa_Fisica (
Id INT DEFAULT NEXT VALUE FOR dbo.seq_Pessoa,
Nome VARCHAR(100),
CPF VARCHAR(11)
)
CREATE TABLE dbo.Pessoa_Juridica (
Id INT DEFAULT NEXT VALUE FOR dbo.seq_Pessoa,
Nome VARCHAR(100),
CNPJ VARCHAR(14)
)
INSERT INTO dbo.Pessoa_Fisica (Nome, CPF)
VALUES('Dirceu Resende', '11111111111')
INSERT INTO dbo.Pessoa_Juridica (Nome, CNPJ)
VALUES('Dirceu Resende Ltda', '22222222222222')
INSERT INTO dbo.Pessoa_Fisica (Nome, CPF)
VALUES('Dirceu Resende 2', '33333333333')
INSERT INTO dbo.Pessoa_Juridica (Nome, CNPJ)
VALUES('Dirceu Resende ME', '44444444444444')
SELECT * FROM dbo.Pessoa_Fisica
SELECT * FROM dbo.Pessoa_Juridica
Resultado
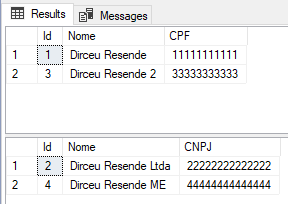
Si quieres saber más sobre Secuencias en SQL Server, lee mi artículo. SQL Server 2012: trabajo con secuencias y comparaciones con IDENTIDAD.
Manejo de errores y excepciones con THROW
Ver contenidoFunción lógica – IIF
Ver contenidoFunción lógica – ELEGIR
Ver contenidoEjemplo de uso:
SELECT CHOOSE(5,
'Janeiro',
'Fevereiro',
'Março',
'Abril',
'Maio',
'Junho',
'Julho',
'Agosto',
'Setembro',
'Novembro',
'Dezembro'
)
Resultado:

Otro ejemplo, ahora recuperando el índice del resultado de una función:
SELECT
GETDATE() AS Hoje,
DATEPART(WEEKDAY, GETDATE()) AS Dia_Semana,
CHOOSE(DATEPART(WEEKDAY, GETDATE()),
'Domingo',
'Segunda-feira',
'Terça-feira',
'Quarta-feira',
'Quinta-feira',
'Sexta-feira',
'Sábado'
) AS Nome_Dia_Semana
Resultado:

Ejemplos que utilizan índices fuera de la lista e índices con decimales
SELECT
CHOOSE(-1,
'Domingo',
'Segunda-feira',
'Terça-feira',
'Quarta-feira',
'Quinta-feira',
'Sexta-feira',
'Sábado'
) AS Nome_Dia_Semana1,
CHOOSE(4.9,
'Domingo',
'Segunda-feira',
'Terça-feira',
'Quarta-feira',
'Quinta-feira',
'Sexta-feira',
'Sábado'
) AS Nome_Dia_Semana2
Resultado:

Como podemos ver arriba, cuando el índice de la función ELEGIR no está en el rango de la lista, la función devolverá NULL. Y cuando usamos un índice con decimales, el índice se convertirá (truncará) a un número entero.
Nota: Internamente, ELEGIR es un atajo para CASE, por lo que los 2 tienen el mismo rendimiento.
Funciones de conversión: PARSE, TRY_PARSE, TRY_CONVERT y TRY_CAST
Ver contenidola funcion PARROQUIA (disponible para fechas y números) es muy útil para convertir algunos formatos distintos al estándar, que CAST y CONVERT no pueden convertir, como en el siguiente ejemplo:
SELECT CAST('Sábado, 29 de dezembro de 2018' AS DATETIME) AS [Cast] -- Erro
GO
SELECT CONVERT(DATETIME, 'Sábado, 29 de dezembro de 2018') AS [CONVERT] -- Erro
GO
SELECT PARSE('Sábado, 29 de dezembro de 2018' AS DATETIME USING 'pt-BR') AS [PARSE] -- Sucesso
GO
Resultado:

Como evolución de la función PARSE, tenemos la función TRY_PARSE, que tiene básicamente el mismo comportamiento que la función PARSE, pero con la diferencia de que cuando la conversión no es posible, en lugar de devolver una excepción durante el procesamiento, simplemente devolverá NULL.
Ejemplo:
-- Nesse exemplo, será gerada uma exceção durante a execução do código T-SQL
-- Msg 9819, Level 16, State 1, Line 1: Error converting string value 'Domingo, 29 de dezembro de 2018' into data type datetime using culture 'pt-BR'.
SELECT PARSE('Domingo, 29 de dezembro de 2018' AS DATETIME USING 'pt-BR') AS [PARSE]
GO
-- Aqui vai apenas retornar NULL
SELECT TRY_PARSE('Domingo, 29 de dezembro de 2018' AS DATETIME USING 'pt-BR') AS [PARSE]
GO
Lo mismo ocurre con las funciones. TRY_CONVERT y TRY_CAST, que tienen el mismo comportamiento que las funciones originales, pero no generan una excepción cuando no se puede realizar una conversión.
Ejemplos de uso:
-- Sucesso (2018-12-28 00:00:00.000)
SELECT CAST('2018-12-28' AS DATETIME)
GO
-- Erro: The conversion of a varchar data type to a datetime data type resulted in an out-of-range value.
SELECT CAST('2018-12-99' AS DATETIME)
GO
-- NULL
SELECT TRY_CAST('2018-12-99' AS DATETIME)
GO
-- Sucesso (2018-12-28 00:00:00.000)
SELECT CONVERT(DATETIME, '2018-12-28')
GO
-- Erro: The conversion of a varchar data type to a datetime data type resulted in an out-of-range value.
SELECT CONVERT(DATETIME, '2018-12-99')
GO
-- NULL
SELECT TRY_CONVERT(DATETIME, '2018-12-99')
GO
Resultado:

Para obtener más información sobre el procesamiento de datos y las conversiones, consulte mi artículo. SQL Server: cómo identificar errores de conversión de datos usando TRY_CAST, TRY_CONVERT, TRY_PARSE, ISNUMERIC e ISDATE.
Función de fecha – EOMES
Ver contenidoEjemplos de uso
SELECT
EOMONTH('2018-01-01') AS Janeiro,
EOMONTH('2018-02-12') AS Fevereiro,
EOMONTH('2018-03-15') AS [Março],
EOMONTH('2018-04-17') AS Abril,
EOMONTH('2018-05-29') AS Maio,
EOMONTH('2018-06-05') AS Junho,
EOMONTH('2018-07-04') AS Julho,
EOMONTH('2018-08-24') AS Agosto,
EOMONTH('2018-09-21') AS Setembro,
EOMONTH('2018-10-11') AS Outubro,
EOMONTH('2018-11-10') AS Novembro,
EOMONTH('2018-12-03') AS Dezembro
Resultado

Funciones de fecha: DATEFROMPARTS, DATETIME2FROMPARTS, DATETIMEFROMPARTS, DATETIMEOFFSETFROMPARTS, SMALLDATETIMEFROMPARTS y TIMEFROMPARTS
Ver contenido- FECHADEPARTES (año, mes, día)
- DATETIME2FROMPARTS (año, mes, día, hora, minuto, segundos, fracciones, precisión)
- DATETIMEFROMPARTS (año, mes, día, hora, minuto, segundos, milisegundos)
- DATETIMEOFFSETFROMPARTS (año, mes, día, hora, minutos, segundos, fracciones, compensación_hora, compensación_minutos, precisión)
- SMALLDATETIMEFROMPARTS (año, mes, día, hora, minuto)
- TIMEFROMPARTS (hora, minuto, segundos, fracciones, precisión)
Script para generar datos de prueba:
IF (OBJECT_ID('tempdb..#Dados') IS NOT NULL) DROP TABLE #Dados
CREATE TABLE #Dados (
Ano INT,
Mes INT,
Dia INT,
Hora INT,
Minuto INT,
Segundo INT,
Millisegundo INT,
Offset_Hora INT,
Offset_Minuto INT
)
INSERT INTO #Dados
VALUES
(2018, 12, 19, 14, 39, 1, 123, 3, 30),
(1987, 5, 28, 21, 22, 59, 999, 3, 0),
(2018, 12, 31, 23, 59, 59, 999, 0, 0)
Ejemplo de la función DATEFROMPARTS y cómo la hacíamos antes de SQL Server 2012:
-- Antes do SQL Server 2012: Utilizando CAST/CONVERT
SELECT
CAST(CAST(Ano AS VARCHAR(4)) + '-' + CAST(Mes AS VARCHAR(2)) + '-' + CAST(Dia AS VARCHAR(2)) AS DATE) AS [CAST_DATE]
FROM
#Dados
-- A partir do SQL Server 2012: DATEFROMPARTS
SELECT
DATEFROMPARTS (Ano, Mes, Dia) AS [DATEFROMPARTS]
FROM
#Dados
Resultado:

Ejemplo usando las 6 funciones juntas
SELECT
DATEFROMPARTS (Ano, Mes, Dia) AS [DATEFROMPARTS],
DATETIME2FROMPARTS (Ano, Mes, Dia, Hora, Minuto, Segundo, Millisegundo, 7) AS [DATETIME2FROMPARTS],
DATETIMEFROMPARTS (Ano, Mes, Dia, Hora, Minuto, Segundo, Millisegundo) AS [DATETIMEFROMPARTS],
DATETIMEOFFSETFROMPARTS (Ano, Mes, Dia, Hora, Minuto, Segundo, Millisegundo, Offset_Hora, Offset_Minuto, 7) AS [DATETIMEOFFSETFROMPARTS],
SMALLDATETIMEFROMPARTS (Ano, Mes, Dia, Hora, Minuto) AS [SMALLDATETIMEFROMPARTS],
TIMEFROMPARTS (Hora, Minuto, Segundo, Millisegundo, 7) AS [TIMEFROMPARTS]
FROM
#Dados
Resultado:

Función de manejo de cadenas – FORMATO
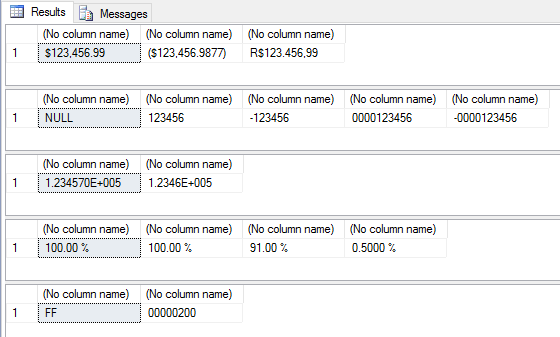
Ver contenidoAlgunos ejemplos del uso de FORMATO – Números
SELECT
FORMAT(123456.99, 'C'), -- Formato de moeda padrão
FORMAT(-123456.987654321, 'C4'), -- Formato de moeda com 4 casas decimais
FORMAT(123456.987654321, 'C2', 'pt-br') -- Formato de moeda forçando a localidade pra Brasil e 2 casas decimais
SELECT
FORMAT(123456.99, 'D'), -- Formato de número inteiro com valores numeric (NULL)
FORMAT(123456, 'D'), -- Formato de número inteiro
FORMAT(-123456, 'D4'), -- Formato de número inteiro com valores negativos
FORMAT(123456, 'D10', 'pt-br'), -- formato de número inteiro com tamanho fixo em 10 caracteres
FORMAT(-123456, 'D10', 'pt-br') -- formato de número inteiro com tamanho fixo em 10 caracteres
SELECT
FORMAT(123456.99, 'E'), -- Formato de notação científica
FORMAT(123456.99, 'E4') -- Formato de notação científica e 4 casas decimais de precisão
SELECT
FORMAT(1, 'P'), -- Formato de porcentagem
FORMAT(1, 'P2'), -- Formato de porcentagem com 2 casas decimais
FORMAT(0.91, 'P'), -- Formato de porcentagem
FORMAT(0.005, 'P4') -- Formato de porcentagem com 4 casas decimais
SELECT
FORMAT(255, 'X'), -- Formato hexadecimal
FORMAT(512, 'X8') -- Formato hexadecimal fixando o retorno em 8 caracteres
Resultado
Otros ejemplos con números:
SELECT
-- Formato de moeda brasileira (manualmente)
FORMAT(123456789.9, 'R$ ###,###,###,###.00'),
-- Utilizando sessão (;) para formatar valores positivos e negativos
FORMAT(123456789.9, 'R$ ###,###,###,###.00;-R$ ###,###,###,###.00'),
-- Utilizando sessão (;) para formatar valores positivos e negativos
FORMAT(-123456789.9, 'R$ ###,###,###,###.00;-R$ ###,###,###,###.00'),
-- Utilizando sessão (;) para formatar valores positivos e negativos
FORMAT(-123456789.9, 'R$ ###,###,###,###.00;(R$ ###,###,###,###.00)'),
-- Formatando porcentagem com 2 casas decimais
FORMAT(0.9975, '#.00%'),
-- Formatando porcentagem com 4 casas decimais
FORMAT(0.997521654, '#.0000%'),
-- Formatando porcentagem com 4 casas decimais
FORMAT(123456789.997521654, '#.0000%'),
-- Formatando porcentagem com 2 casas decimais e utilizando sessão (;)
FORMAT(0.123456789, '#.00%;-#.00%'),
-- Formatando porcentagem com 2 casas decimais e utilizando sessão (;)
FORMAT(-0.123456789, '#.00%;-#.00%'),
-- Formatando porcentagem com 2 casas decimais e utilizando sessão (;)
FORMAT(-0.123456789, '#.00%;(#.00%)')
Resultado:

Número de llenado con ceros a la izquierda:
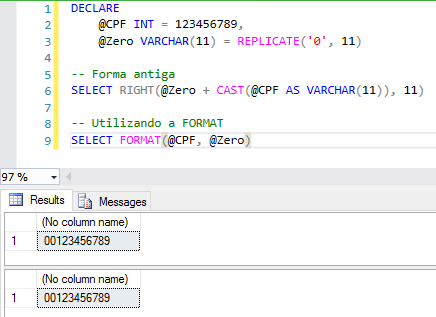
Algunos ejemplos del uso de FORMATO – Fechas
SET LANGUAGE 'English'
SELECT
FORMAT(GETDATE(), 'd'), -- Padrão de data abreviada.
FORMAT(GETDATE(), 'D'), -- Padrão de data completa.
FORMAT(GETDATE(), 'R'), -- Padrão RFC1123
FORMAT(GETDATE(), 't'), -- Padrão de hora abreviada.
FORMAT(GETDATE(), 'T') -- Padrão de hora completa.
SET LANGUAGE 'Brazilian'
SELECT
FORMAT(GETDATE(), 'd'), -- Padrão de data abreviada.
FORMAT(GETDATE(), 'D'), -- Padrão de data completa.
FORMAT(GETDATE(), 'R'), -- Padrão RFC1123
FORMAT(GETDATE(), 't'), -- Padrão de hora abreviada.
FORMAT(GETDATE(), 'T') -- Padrão de hora completa.
Resultado:

Formato de fecha personalizado:
SELECT
-- Formato de data típico do Brasil
FORMAT(GETDATE(), 'dd/MM/yyyy'),
-- Formato de data/hora típico dos EUA
FORMAT(GETDATE(), 'yyyy-MM-dd HH:mm:ss.fff'),
-- Exibindo a data por extenso
FORMAT(GETDATE(), 'dddd, dd \d\e MMMM \d\e yyyy'),
-- Exibindo a data por extenso (forçando o idioma pra PT-BR)
FORMAT(GETDATE(), 'dddd, dd \d\e MMMM \d\e yyyy', 'pt-br'),
-- Exibindo a data/hora, mas zerando os minutos e segundos
FORMAT(GETDATE(), 'dd/MM/yyyy HH:00:00', 'pt-br')
Resultado:

Si quieres saber más sobre la función FORMATO, lee mi artículo. SQL Server: uso de la función FORMATO para aplicar máscaras y formato a números y fechas.
Función de manejo de cadenas – CONCAT
Ver contenidoGenerando datos para ejemplos
IF (OBJECT_ID('tempdb..#Dados') IS NOT NULL) DROP TABLE #Dados
CREATE TABLE #Dados (
Dt_Nascimento DATE,
Nome1 VARCHAR(50),
Nome2 VARCHAR(50),
Idade AS CONVERT(INT, (DATEDIFF(DAY, Dt_Nascimento, GETDATE()) / 365.25))
)
INSERT INTO #Dados
VALUES
('1987-05-28', 'Dirceu', 'Resende'),
('1987-01-15', 'Patricia', 'Resende'),
('1987-01-15', 'Teste', NULL)
Ejemplos
-- Antes do SQL Server 2012: Utilizando CAST/CONVERT
SELECT
Nome1 + ' ' + Nome2 + ' | ' + CAST(Idade AS VARCHAR(3)) + ' | ' + CAST(Dt_Nascimento AS VARCHAR(40)) AS [Antes do SQL Server 2012]
FROM
#Dados
-- A partir do SQL Server 2012: Utilizando CONCAT
SELECT
CONCAT(Nome1, ' ', Nome2, ' | ', Idade, ' | ', Dt_Nascimento) AS [A partir do SQL Server 2012]
FROM
#Dados
Resultado:

Como puede ver, la función CONCAT convierte automáticamente tipos de datos a varchar y también maneja valores NULL y los convierte en cadenas vacías. En otras palabras, CONCAT es más sencillo, pero ¿qué pasa con el rendimiento? ¿Cómo es?

Al menos en las pruebas que hice, CONCAT demostró ser más rápido que la concatenación tradicional (usando “+”). Más simple y más rápido.
Funciones analíticas: FIRST_VALUE y LAST_VALUE
Ver contenidoScript T-SQL para crear datos para el ejemplo:
IF (OBJECT_ID('tempdb..#Dados') IS NOT NULL) DROP TABLE #Dados
CREATE TABLE #Dados (
Id INT IDENTITY(1,1),
Nome VARCHAR(50),
Idade INT
)
INSERT INTO #Dados
VALUES
('Dirceu Resende', 31),
('Joãozinho das Naves', 33),
('Rafael Sudré', 48),
('Potássio', 27),
('Rafaela', 25),
('Jodinei', 39)
Ejemplo 1: Identificar las edades más antiguas y más jóvenes y los nombres de estas personas
-- Antes do SQL Server 2012: MIN/MAX e Subquery
SELECT
*,
(SELECT MIN(Idade) FROM #Dados) AS Menor_Idade,
(SELECT MAX(Idade) FROM #Dados) AS Maior_Idade,
(SELECT TOP(1) Nome FROM #Dados ORDER BY Idade) AS Nome_Menor_Idade,
(SELECT TOP(1) Nome FROM #Dados ORDER BY Idade DESC) AS Nome_Maior_Idade
FROM
#Dados
-- A partir do SQL Server 2012: FIRST_VALUE
SELECT
*,
FIRST_VALUE(Idade) OVER(ORDER BY Idade) AS Menor_Idade,
FIRST_VALUE(Idade) OVER(ORDER BY Idade DESC) AS Maior_Idade,
FIRST_VALUE(Nome) OVER(ORDER BY Idade) AS Nome_Menor_Idade,
FIRST_VALUE(Nome) OVER(ORDER BY Idade DESC) AS Nome_Maior_Idade
FROM
#Dados
Resultado:

Bueno, el código es mucho más simple y limpio. Hablando de rendimiento, hay varias formas de lograr este objetivo, con consultas de mayor rendimiento que la que usé en el primer ejemplo, pero quería que el código fuera lo más simple posible. Si realmente utilizas este tipo de programación en tu código, es una buena idea revisar tus consultas, ya que tienen un rendimiento muy pobre.
Vea cómo se ve el plan de ejecución para la primera consulta y la consulta usando la función FIRST_VALUE:

Y ahora usemos la función LAST_VALUE para devolver los registros más grandes del conjunto de datos:
SELECT
*,
FIRST_VALUE(Idade) OVER(ORDER BY Idade) AS Menor_Idade,
LAST_VALUE(Idade) OVER(ORDER BY Idade) AS Maior_Idade,
FIRST_VALUE(Nome) OVER(ORDER BY Idade) AS Nome_Menor_Idade,
LAST_VALUE(Nome) OVER(ORDER BY Idade) AS Nome_Maior_Idade
FROM
#Dados
Resultado:

Eh... La función LAST_VALUE no trajo el último valor sino el valor de la línea actual... Esto sucede debido al concepto de marco. El marco le permite especificar un conjunto de filas para la "ventana", que es incluso más pequeña que la partición. El marco predeterminado contiene líneas que comienzan con la primera línea y llegan hasta la línea actual. Para la línea 1, la “ventana” es solo la línea 1. Para la línea 3, la ventana contiene las líneas 1 a 3. Cuando usa FIRST_VALUE, la primera línea se incluye de forma predeterminada, por lo que no tiene que preocuparse para obtener los resultados que espera.
Para que la función LAST_VALUE realmente devuelva el último valor de todo el conjunto de datos, usaremos los parámetros FILAS ENTRE LA FILA ACTUAL Y LAS SIGUIENTES SIN LÍMITES junto con la función LAST_VALUE, que hace que la ventana comience desde la línea actual hasta la última línea de la partición.
Nuevo script usando la función LAST_VALUE:
SELECT
*,
FIRST_VALUE(Idade) OVER(ORDER BY Idade) AS Menor_Idade,
LAST_VALUE(Idade) OVER(ORDER BY Idade ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS Maior_Idade,
FIRST_VALUE(Nome) OVER(ORDER BY Idade) AS Nome_Menor_Idade,
LAST_VALUE(Nome) OVER(ORDER BY Idade ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS Nome_Maior_Idade
FROM
#Dados
Resultado:

Funciones analíticas: LAG y LEAD
Ver contenidoScript T-SQL para generar los datos de prueba:
IF (OBJECT_ID('tempdb..#Dados') IS NOT NULL) DROP TABLE #Dados
CREATE TABLE #Dados (
Id INT IDENTITY(1,1),
Nome VARCHAR(50),
Idade INT
)
INSERT INTO #Dados
VALUES
('Dirceu Resende', 31),
('Joãozinho das Naves', 33),
('Rafael Sudré', 48),
('Potássio', 27),
('Rafaela', 25),
('Jodinei', 39)
Imagine que quiero crear un puntero y acceder a quién es el siguiente ID y el ID anterior del registro actual. Antes de SQL Server 2008, necesitábamos crear autouniones para completar esta tarea. A partir de SQL Server 2012, podemos utilizar las funciones LAG y LEAD para esta necesidad:
-- Antes do SQL Server 2008: Self-Joins
SELECT
A.*,
B.Id AS Id_Proximo,
C.Id AS Id_Anterior
FROM
#Dados A
LEFT JOIN #Dados B ON B.Id = A.Id + 1
LEFT JOIN #Dados C ON C.Id = A.Id - 1
-- A partir do SQL Server 2012: LAG e LEAD
SELECT
A.*,
LEAD(Id) OVER(ORDER BY Id) AS Id_Proximo,
LAG(Id) OVER(ORDER BY Id) AS Id_Anterior
FROM
#Dados AResultado:

Código mucho más simple y limpio. Analicemos ahora el rendimiento de las dos consultas:

Sí, aunque LAG y LEAD son mucho más simples y legibles, su rendimiento termina siendo un poco menor que el de los Self-Joins, probablemente por el ordenamiento que se hace para aplicar las funciones. Voy a insertar un volumen mayor de registros (3 millones de registros) para comprobar si el rendimiento sigue siendo peor que el de Self-Joins, lo cual creo que no tiene sentido, ya que Self-Join realiza varias lecturas en la mesa y las funciones, en teoría, solo deberían hacer 1.
Resultados de la prueba con 3 millones de registros (me sorprendió):

Plan de ejecución con SELF-JOIN:

Plan de ejecución con LED y LEAD:

Imaginé que al tener un plan más simple y hacer menos lecturas de la tabla, las funciones tendrían un rendimiento mucho mejor que las autouniones, pero debido a un operador SORT muy pesado, el rendimiento usando las funciones terminó siendo peor, como podemos ver en el plan de ejecución y la advertencia para el operador sort:

En resumen, si trabaja con conjuntos de datos pequeños, puede utilizar las funciones LAG y LEAD sin ningún problema, ya que el código es más legible. Si necesita utilizar esto en grandes volúmenes de datos, pruebe la autounión para evaluar cómo será el rendimiento en su escenario.
EJECUTAR… CON CONJUNTOS DE RESULTADOS
Ver contenidoA partir de SQL Server 2012, ahora podemos utilizar la cláusula FROM RESULT SETS al ejecutar Procedimientos Almacenados, de manera que podemos cambiar el nombre y tipo de campos que devuelven los Procedimientos Almacenados, de una forma muy sencilla y práctica.
Ejemplo 1:
CREATE PROCEDURE dbo.stpLista_Tabelas
AS
BEGIN
SELECT
[object_id],
[name],
[type_desc],
create_date
FROM
sys.tables
END
-- Executa a Stored Procedure
EXEC dbo.stpLista_Tabelas
GO
EXEC dbo.stpLista_Tabelas
WITH RESULT SETS ((
[id_tabela] int,
[nome_tabela] varchar(100),
[tipo] varchar(50),
[data_criacao] date
))
Resultado:
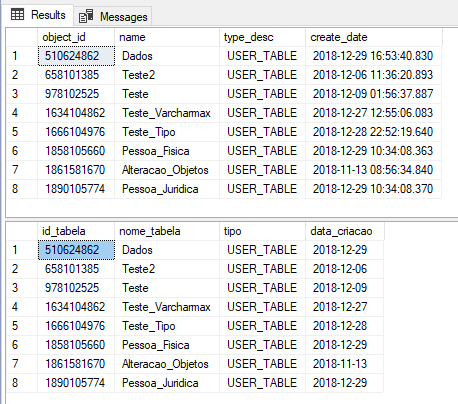
Si el procedimiento almacenado devuelve más de un conjunto de datos, puede utilizar la cláusula CON CONJUNTOS DE RESULTADOS como esta:
CREATE PROCEDURE dbo.stpLista_Tabelas2
AS
BEGIN
SELECT
[object_id],
[name],
[type_desc],
create_date
FROM
sys.tables
SELECT
[object_id],
[name],
[type_desc],
create_date
FROM
sys.objects
END
-- Executa a Stored Procedure
EXEC dbo.stpLista_Tabelas2
GO
EXEC dbo.stpLista_Tabelas2
WITH RESULT SETS (
(
[id_tabela] int,
[nome_tabela] varchar(100),
[tipo] varchar(50),
[data_criacao] date
),
(
[id_objeto] int,
[nome_objeto] varchar(100),
[tipo] varchar(50),
[data_criacao] date
)
)
Resultado:
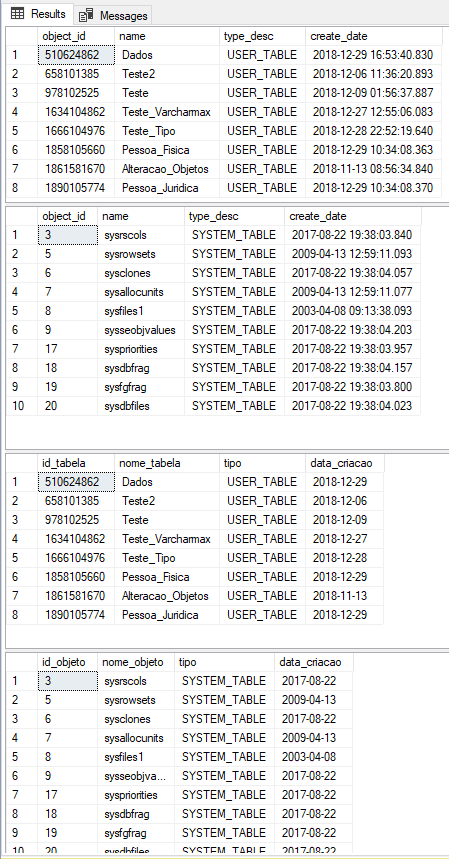
SELECCIONE EL X POR CIENTO SUPERIOR
Ver contenidoSu uso es prácticamente el mismo que el tradicional y ya conocido TOP:
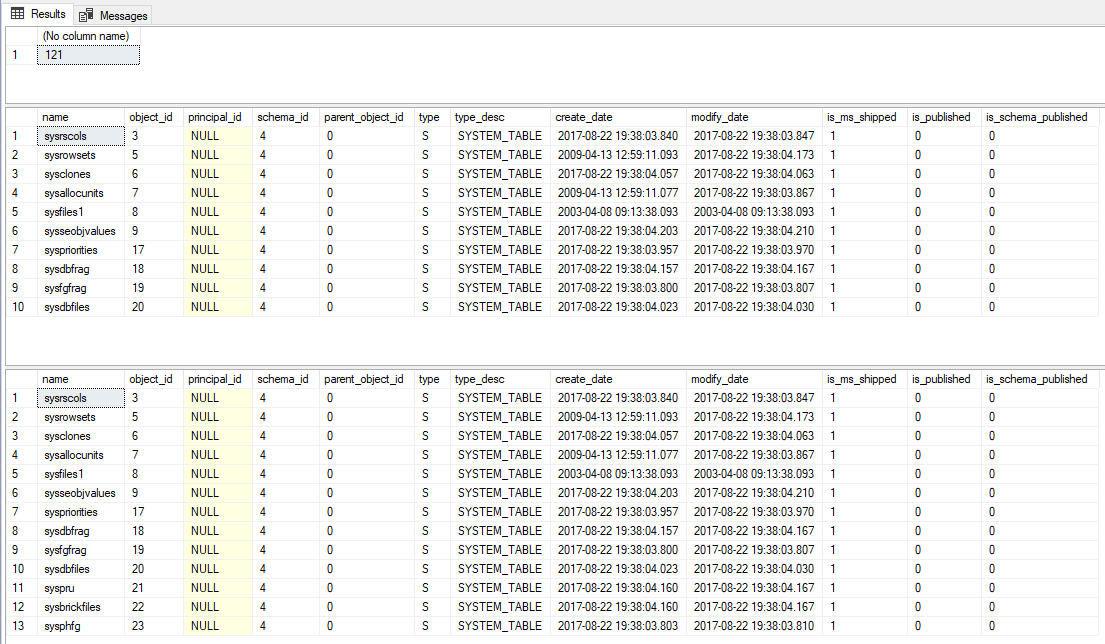
-- Conta quantos objetos existem na sys.objects (121)
SELECT COUNT(*) FROM sys.objects
-- Retorna 10 linhas da view sys.objects
SELECT TOP 10 * FROM sys.objects
-- Retorna 10% das linhas da view sys.objects (arredondando para cima - CEILING)
SELECT TOP 10 PERCENT * FROM sys.objects
Resultado:
Función matemática – LOG
Ver contenido¡Eso es todo, amigos!
Un fuerte abrazo para ti y nos vemos en el próximo post.

Comentários (0)
Carregando comentários…