Hola, chicos,
¡Buenas noches!
En esta publicación, le demostraré cómo importar, leer, procesar y exportar datos entre una tabla de SQL Server y un archivo XML.
Esta integración entre la base de datos y los archivos XML es una característica excelente y un gran diferenciador para los desarrolladores que usan SQL Server y pueden leer y generar fácilmente archivos en este formato de forma nativa a través de la base de datos.
Conociendo los archivos XML de ejemplo Cómo importar archivos XML a SQL Server Cómo tratar y leer atributos XML en SQL ServerCómo tratar y leer datos de atributos de XML en SQL Server
Una vez que el XML ya esté en una tabla, comencemos a procesar y leer la información XML. En este caso necesitaremos almacenar el contenido en una variable de tipo XML.
Para hacer esto, puedes hacerlo así:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML)
Ahora que podemos cargar nuestro XML en una variable, comencemos a procesar los datos.
Lectura sencilla:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML)
SELECT
@XML.value('(/Root/Cliente[1]/@Nome)[1]','varchar(100)') AS Cliente1_Nome,
@XML.value('(/Root/Cliente[1]/@Idade)[1]','int') AS Cliente1_Idade,
@XML.value('(/Root/Cliente[1]/@CPF)[1]','varchar(100)') AS Cliente1_CPF,
@XML.value('(/Root/Cliente[1]/@Email)[1]','varchar(100)') AS Cliente1_Email,
@XML.value('(/Root/Cliente[1]/@Celular)[1]','varchar(100)') AS Cliente1_Celular,
@XML.value('(/Root/Cliente[1]/Endereco[1]/@Cidade)[1]','varchar(100)') AS Cliente1_Endereco1_Cidade,
@XML.value('(/Root/Cliente[1]/Endereco[2]/@Cidade)[1]','varchar(100)') AS Cliente1_Endereco2_Cidade
SELECT
@XML.value('(/Root/Cliente[2]/@Nome)[1]','varchar(100)') AS Cliente2_Nome,
@XML.value('(/Root/Cliente[2]/@Idade)[1]','int') AS Cliente2_Idade,
@XML.value('(/Root/Cliente[2]/@CPF)[1]','varchar(100)') AS Cliente2_CPF,
@XML.value('(/Root/Cliente[2]/@Email)[1]','varchar(100)') AS Cliente2_Email,
@XML.value('(/Root/Cliente[2]/@Celular)[1]','varchar(100)') AS Cliente2_Celular,
@XML.value('(/Root/Cliente[2]/Endereco[1]/@Cidade)[1]','varchar(100)') AS Cliente1_Endereco1_Cidade,
@XML.value('(/Root/Cliente[2]/Endereco[2]/@Cidade)[1]','varchar(100)') AS Cliente1_Endereco2_Cidade

Como vimos en el ejemplo anterior, necesitamos definir manualmente la línea que queremos que devuelva información de nuestro XML. Pero ¿qué pasa si el archivo tiene 100, 1000 o más líneas? ¿Tendremos que usar la declaración WHILE para recorrer todas las líneas del XML? No. Para hacer esto, podemos usar la función NODOS, que aplica nuestros filtros SELECT a todos los nodos en nuestro selector y los devuelve en forma de filas de una tabla:
Usando la función NODOS para devolver todos los nodos:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML)
SELECT
Clientes.linha.value('@Nome','varchar(100)') AS Nome,
Clientes.linha.value('@Idade','int') AS Idade,
Clientes.linha.value('@CPF','varchar(14)') AS CPF,
Clientes.linha.value('@Email','varchar(200)') AS Email,
Clientes.linha.value('@Celular','varchar(20)') AS Celular
FROM
@XML.nodes('/Root/Cliente') Clientes(linha)

Cuando usamos la función nodos, estamos informando que por cada nodo del árbol XML que esté en la estructura “/Root/Cliente” se devuelve un registro de nuestra tabla. Este registro se identifica mediante la nomenclatura Clientes (elemento padre, que sería como la tabla) y línea (cada registro del elemento padre).
Después de dividir los nodos en registros, necesitamos recuperar la información de cada atributo. Para ello utilizamos la función valor, seguido de @NameOfAttribute (debe ser el mismo que el nombre del atributo XML) y su respectivo tipo de retorno.
Usando la función EXISTIR
En determinadas situaciones, necesitamos saber si un determinado nodo existe en nuestro XML. Para ello, SQL Server nos proporciona la función existir, que nos permite realizar este tipo de comprobación:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML)
SELECT
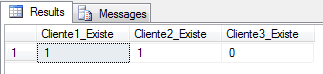
@XML.exist('(/Root/Cliente[1]/@Nome)[1]') AS Cliente1_Existe,
@XML.exist('(/Root/Cliente[2]/@Nome)[1]') AS Cliente2_Existe,
@XML.exist('(/Root/Cliente[3]/@Nome)[1]') AS Cliente3_Existe
Usando existe junto con el valor:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML)
SELECT
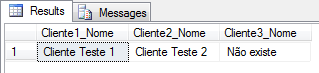
(CASE WHEN @XML.exist('(/Root/Cliente[1]/@Nome)[1]') = 1
THEN @XML.value('(/Root/Cliente[1]/@Nome)[1]', 'varchar(100)')
ELSE 'Não existe'
END) AS Cliente1_Nome,
(CASE WHEN @XML.exist('(/Root/Cliente[2]/@Nome)[1]') = 1
THEN @XML.value('(/Root/Cliente[2]/@Nome)[1]', 'varchar(100)')
ELSE 'Não existe'
END) AS Cliente2_Nome,
(CASE WHEN @XML.exist('(/Root/Cliente[3]/@Nome)[1]') = 1
THEN @XML.value('(/Root/Cliente[3]/@Nome)[1]', 'varchar(100)')
ELSE 'Não existe'
END) AS Cliente3_Nome
Recuperando nodos secundarios
La primera parte se ha completado: ahora podemos realizar una importación simple a nuestro XML. Pero todavía nos queda un largo camino por recorrer: nuestro XML tiene N nodos secundarios, con 2 niveles de jerarquía más con los que podemos trabajar (Dirección y Teléfono).
Importando el 1er nivel de jerarquía: Dirección
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML)
SELECT
Clientes.linha.value('@Nome','varchar(100)') AS Nome,
Clientes.linha.value('@Idade','int') AS Idade,
Clientes.linha.value('@CPF','varchar(14)') AS CPF,
Clientes.linha.value('@Email','varchar(200)') AS Email,
Clientes.linha.value('@Celular','varchar(20)') AS Celular,
Enderecos.linha.value('@Cidade','varchar(60)') AS Cidade,
Enderecos.linha.value('@Estado','varchar(2)') AS UF,
Enderecos.linha.value('@Pais','varchar(50)') AS Pais,
Enderecos.linha.value('@CEP','varchar(10)') AS CEP
FROM
@XML.nodes('/Root/Cliente') Clientes(linha)
CROSS APPLY Clientes.linha.nodes('Endereco') Enderecos(linha)

Tenga en cuenta que para obtener los subniveles de la jerarquía utilizo un CROSS APPLY del elemento padre (Clientes) y para cada registro (línea) cruzo estos datos con los nodos hijos (del tipo Dirección).
Importación del segundo nivel de jerarquía: Teléfono
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML)
SELECT
Clientes.linha.value('@Nome','varchar(100)') AS Nome,
Clientes.linha.value('@Idade','int') AS Idade,
Clientes.linha.value('@CPF','varchar(14)') AS CPF,
Clientes.linha.value('@Email','varchar(200)') AS Email,
Clientes.linha.value('@Celular','varchar(20)') AS Celular,
Enderecos.linha.value('@Cidade','varchar(60)') AS Cidade,
Enderecos.linha.value('@Estado','varchar(2)') AS UF,
Enderecos.linha.value('@Pais','varchar(50)') AS Pais,
Enderecos.linha.value('@CEP','varchar(10)') AS CEP,
Telefones.linha.value('@Fixo','varchar(20)') AS Telefone_Fixo,
Telefones.linha.value('@Piscina','varchar(20)') AS Tem_Piscina,
Telefones.linha.value('@Quintal','varchar(20)') AS Tem_Quintal,
Telefones.linha.value('@Quadra','varchar(20)') AS Tem_Quadra,
Telefones.linha.value('@NaoExiste','varchar(20)') AS Atributo_Nao_Existe
FROM
@XML.nodes('/Root/Cliente') Clientes(linha)
CROSS APPLY Clientes.linha.nodes('Endereco') Enderecos(linha)
CROSS APPLY Enderecos.linha.nodes('Telefone') Telefones(linha)

Y finalmente pudimos importar los datos. Pero hay un error ahí...
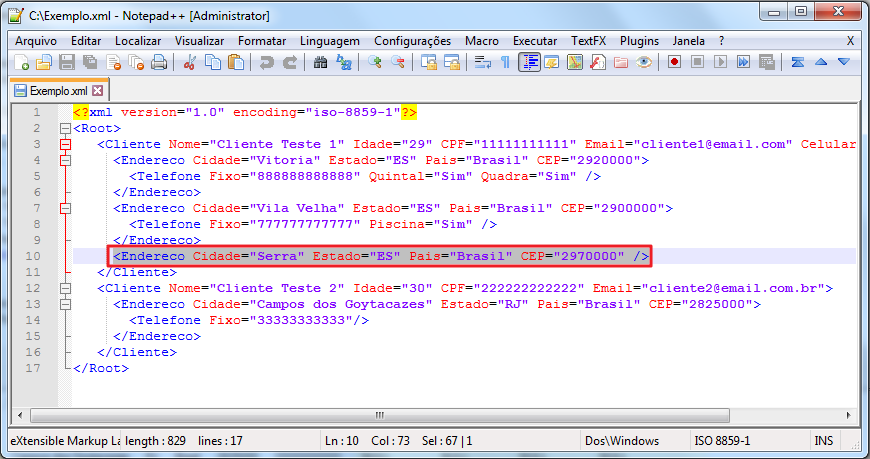
Si analizamos más nuestro XML veremos que una de las direcciones no fue importada, porque no tenía número de teléfono y como hicimos un CROSS APPLY este registro fue ignorado. Tendremos que abordar esto:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML)
SELECT
Clientes.linha.value('@Nome','varchar(100)') AS Nome,
Clientes.linha.value('@Idade','int') AS Idade,
Clientes.linha.value('@CPF','varchar(14)') AS CPF,
Clientes.linha.value('@Email','varchar(200)') AS Email,
Clientes.linha.value('@Celular','varchar(20)') AS Celular,
Enderecos.linha.value('@Cidade','varchar(60)') AS Cidade,
Enderecos.linha.value('@Estado','varchar(2)') AS UF,
Enderecos.linha.value('@Pais','varchar(50)') AS Pais,
Enderecos.linha.value('@CEP','varchar(10)') AS CEP,
Telefones.linha.value('@Fixo','varchar(20)') AS Telefone_Fixo,
Telefones.linha.value('@Piscina','varchar(20)') AS Tem_Piscina,
Telefones.linha.value('@Quintal','varchar(20)') AS Tem_Quintal,
Telefones.linha.value('@Quadra','varchar(20)') AS Tem_Quadra,
Telefones.linha.value('@NaoExiste','varchar(20)') AS Atributo_Nao_Existe
FROM
@XML.nodes('/Root/Cliente') Clientes(linha)
CROSS APPLY Clientes.linha.nodes('Endereco') Enderecos(linha)
OUTER APPLY Enderecos.linha.nodes('Telefone') Telefones(linha)
Para resolver esta situación, reemplacé el último CROSS APPLY con un OUTER APPLY, que tiene un comportamiento similar a un LEFT JOIN en este caso, donde los registros que no tienen un nodo hijo continúan apareciendo en nuestra tabla y las columnas destinadas a los nodos hijos estarán vacías. Siempre que haya una situación en la que no esté seguro de si el elemento tendrá hijos o no, utilice OUTER APPLY.

Cómo tratar y leer datos de XML en SQL Server
A diferencia de la base 1, donde toda la información se almacenaba en forma de atributos, ahora usaremos XML de base 2, que se compone predominantemente de datos.
Lectura de datos sencilla
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT
@XML.value('(Escola/Turma/Aluno)[1]', 'varchar(60)') AS Aluno1,
@XML.value('(Escola/Turma/Aluno)[2]', 'varchar(60)') AS Aluno2,
@XML.value('(Escola/Turma/Aluno)[3]', 'varchar(60)') AS Aluno3,
@XML.value('(Escola/Turma/Aluno)[4]', 'varchar(60)') AS Aluno4,
@XML.value('(Escola/Turma/Aluno)[5]', 'varchar(60)') AS Aluno5,
@XML.value('(Escola/Turma/Aluno)[6]', 'varchar(60)') AS Aluno6,
@XML.value('(Escola/Turma/Aluno)[14]', 'varchar(60)') AS Aluno14_Nao_Existe

Al igual que hice con los atributos, quería demostrar cómo devolver individualmente cada nodo en el archivo, especificando el índice de su posición en relación con la raíz. Ahora demostraré nuevamente cómo usar la función NODOS para devolver todos los nodos como registros de una tabla:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT
Alunos.linha.value('.','varchar(100)') AS Nome
FROM
@XML.nodes('/Escola/Turma/Aluno') Alunos(linha)

Ejemplo más completo, mezclando datos y atributos:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT
Alunos.linha.value('.', 'varchar(60)') AS Aluno,
Turmas.linha.value('@Nome','varchar(100)') AS Turma,
Turmas.linha.value('@Serie','int') AS Serie,
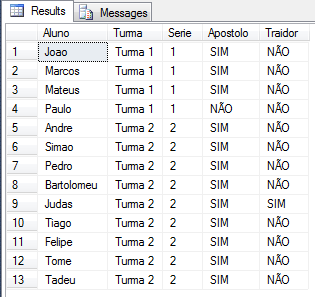
(CASE WHEN Alunos.linha.value('@Apostolo','varchar(60)') = '1' THEN 'SIM' ELSE 'NÃO' END) AS Apostolo,
(CASE WHEN Alunos.linha.value('@Traidor','varchar(2)') = '1' THEN 'SIM' ELSE 'NÃO' END) AS Traidor
FROM
@XML.nodes('/Escola/Turma') Turmas(linha)
CROSS APPLY Turmas.linha.nodes('Aluno') Alunos(linha)
Usando XQuery (función XML.query)
Muchas veces al manejar archivos XML sentimos la necesidad de realizar consultas o filtros más avanzados para devolver la información que queremos en lugar del archivo completo. Para esta necesidad, tenemos la función de consulta:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT
@XML.query('.') AS XML_Completo,
@XML.query('Escola/Turma[1]/Aluno[1]') AS XML_Turma1_Aluno1,
@XML.query('Escola/Turma[1]/Aluno[1]/text()') AS XML_Turma1_Aluno1_Nome,
@XML.query('Escola/Turma[1]/Aluno[1]').value('.', 'varchar(100)') AS Turma1_Aluno1_Nome

Usando XQuery para filtrar resultados:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT
@XML.query('Escola/Turma[@Serie=''2'']') AS XML_Turma_2a_Serie,
@XML.query('Escola/Turma[@Nome=''Turma 1'']') AS XML_Turma1,
@XML.query('Escola/Turma/Aluno[@Traidor=''1'']') AS XML_Judas,
@XML.query('Escola/Turma/Aluno[@Apostolo=''0'']') AS XML_Paulo,
@XML.query('Escola/Turma/Aluno[.=''Pedro'']') AS XML_Pedro

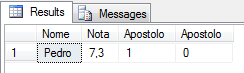
Información del estudiante que regresa Pedro:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
DECLARE @XML2 XML = (SELECT @XML.query('Escola/Turma/Aluno[.=''Pedro'']'))
SELECT
Alunos.linhas.value('.', 'varchar(100)') AS Nome,
Alunos.linhas.value('@Nota', 'float') AS Nota,
Alunos.linhas.value('@Apostolo', 'bit') AS Apostolo,
Alunos.linhas.value('@Traidor', 'bit') AS Apostolo
FROM
@XML2.nodes('/Aluno') AS Alunos(linhas)
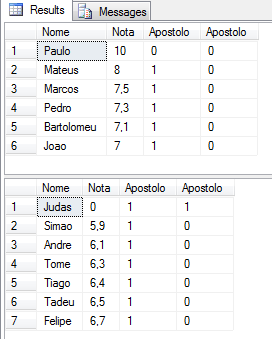
Trabajar con valores:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
DECLARE @XML_Aprovados XML = (SELECT @XML.query('//Aluno[@Nota>=7]'))
DECLARE @XML_Reprovados XML = (SELECT @XML.query('//Aluno[@Nota<7]'))
SELECT
Alunos.linhas.value('.', 'varchar(100)') AS Nome,
Alunos.linhas.value('@Nota', 'float') AS Nota,
Alunos.linhas.value('@Apostolo', 'bit') AS Apostolo,
Alunos.linhas.value('@Traidor', 'bit') AS Apostolo
FROM
@XML_Aprovados.nodes('/Aluno') AS Alunos(linhas)
ORDER BY
Nota DESC
SELECT
Alunos.linhas.value('.', 'varchar(100)') AS Nome,
Alunos.linhas.value('@Nota', 'float') AS Nota,
Alunos.linhas.value('@Apostolo', 'bit') AS Apostolo,
Alunos.linhas.value('@Traidor', 'bit') AS Apostolo
FROM
@XML_Reprovados.nodes('/Aluno') AS Alunos(linhas)
ORDER BY
Nota
Una cosa a tener en cuenta sobre la función de consulta es que no le permite seleccionar datos de atributos que estén en el mismo nivel que el nodo actual. Por ejemplo, si está utilizando un selector de estudiantes, no puede devolver un atributo de ese nodo Estudiante que está seleccionando. Si intenta hacer esto, encontrará uno de estos mensajes de error:
XQuery [Sqm.data.query()]: el atributo no puede aparecer fuera de un elemento
XQuery [valor()]: no se admiten nodos de atributos de nivel superior
Para evitar esto, use la función valor y aplica tus filtros de otra manera.
Usando funciones en XML
Otra característica muy interesante de XML es la posibilidad de utilizar funciones para filtrar u obtener más información a través de los datos de nuestro XML. Ahora demostraré cómo aplicar esto a nuestros archivos XML de ejemplo.
Usando funciones numéricas:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT
@XML.value('max(//Aluno/@Nota)', 'float') AS Maior_Nota,
@XML.value('min(//Aluno/@Nota)', 'float') AS Menor_Nota,
@XML.value('avg(//Aluno/@Nota)', 'float') AS Media_Nota,
@XML.value('sum(//Aluno/@Nota)', 'float') AS Soma_Nota,
@XML.value('count(//Aluno/@Nota)', 'int') AS Qtde_Nota,
@XML.value('count(//Aluno[@Nota>=7]/@Nota)', 'int') AS Qtde_Nota_Maior7,
@XML.value('count(//Aluno[@Nota<7]/@Nota)', 'int') AS Qtde_Nota_Menor7

Funciones de cadena:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT
@XML.value('(//Aluno[.=''Pedro''])[1]', 'varchar(100)') AS Pedro,
@XML.value('string-length((//Aluno[.=''Pedro''])[1])', 'varchar(100)') AS Tamanho_Nome_Pedro,
@XML.value('concat((//Aluno[.=''Pedro''])[1], '' Teste'')', 'varchar(100)') AS [Concat],
@XML.value('substring((//Aluno[.=''Pedro''])[1], 1, 1)', 'varchar(100)') AS [Primeira_Letra]
o podemos usar contiene:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT
Alunos.linha.value('.', 'varchar(100)') AS Pedro,
Alunos.linha.value('string-length((.))', 'varchar(100)') AS Tamanho_Nome_Pedro,
Alunos.linha.value('concat((.), '' Teste'')', 'varchar(100)') AS [Concat],
Alunos.linha.value('substring((.), 1, 1)', 'varchar(100)') AS [Primeira_Letra]
FROM
@XML.nodes('//Aluno') AS Alunos(linha)
WHERE
Alunos.linha.value('contains((.), "Pedro")', 'bit') = 1
e incluso operaciones simples de Transact-SQL:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT
Alunos.linha.value('.', 'varchar(100)') AS Pedro,
Alunos.linha.value('string-length((.))', 'varchar(100)') AS Tamanho_Nome_Pedro,
Alunos.linha.value('concat((.), '' Teste'')', 'varchar(100)') AS [Concat],
Alunos.linha.value('substring((.), 1, 1)', 'varchar(100)') AS [Primeira_Letra]
FROM
@XML.nodes('//Aluno') AS Alunos(linha)
WHERE
Alunos.linha.value('.', 'varchar(100)') = 'Pedro'

Manipular XML con la función de modificación
Cuando utilizamos la función de modificación, tenemos más pruebas de cuán avanzado es el procesamiento XML con SQL Server. Esta función nos permite modificar los datos almacenados en la variable XML en tiempo de ejecución, y nos permite insertar datos (insert), reemplazar datos (replace value of) y eliminar datos (delete).
Para utilizar la función modificar(), debe realizar ACTUALIZAR, ELIMINAR o ESTABLECER @Variavel. No se permite el uso de esta función durante un SELECT.
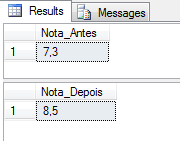
Cómo reemplazar valores usando el valor de reemplazo de la función:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT @XML.value('(//Aluno[.="Pedro"]/@Nota)[1]', 'float') AS Nota_Antes
------------------------------------------------------
-- ALTERA O VALOR DA NOTA DO ALUNO "PEDRO"
------------------------------------------------------
DECLARE @Tabela_XML TABLE ( Dados XML )
INSERT INTO @Tabela_XML
SELECT Ds_Xml FROM #XML2
UPDATE @Tabela_XML
SET Dados.modify('replace value of (//Aluno[.="Pedro"]/@Nota)[1] with("8.5")')
SET @XML = (SELECT TOP 1 Dados FROM @Tabela_XML)
SELECT @XML.value('(//Aluno[.="Pedro"]/@Nota)[1]', 'float') AS Nota_Depois
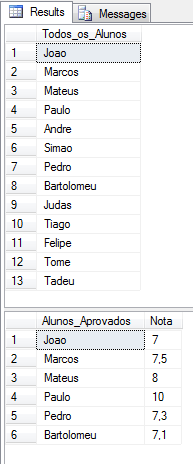
Elimine un elemento de XML usando la función de eliminación:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SELECT Alunos.linha.value('.', 'varchar(100)') AS Todos_os_Alunos
FROM @XML.nodes('//Aluno') Alunos(linha)
------------------------------------------------------
-- REMOVE OS ALUNOS COM NOTA MENOR QUE 7
------------------------------------------------------
DECLARE @Tabela_XML TABLE ( Dados XML )
INSERT INTO @Tabela_XML
SELECT Ds_Xml FROM #XML2
UPDATE @Tabela_XML
SET Dados.modify('delete (//Aluno[@Nota<7])')
SET @XML = (SELECT TOP 1 Dados FROM @Tabela_XML)
SELECT
Alunos.linha.value('.', 'varchar(100)') AS Alunos_Aprovados,
Alunos.linha.value('@Nota', 'float') AS Nota
FROM @XML.nodes('//Aluno') Alunos(linha)
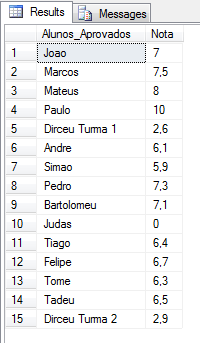
Inserte nodos en XML usando la función de inserción:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
SET @XML.modify('insert <Aluno Apostolo="0" Traidor="0" Nota="2.6">Dirceu Turma 1</Aluno>
into (//Turma)[1]')
SET @XML.modify('insert <Aluno Apostolo="0" Traidor="0" Nota="2.9">Dirceu Turma 2</Aluno>
into (//Turma)[2]')
SELECT
Alunos.linha.value('.', 'varchar(100)') AS Alunos_Aprovados,
Alunos.linha.value('@Nota', 'float') AS Nota
FROM @XML.nodes('//Aluno') Alunos(linha)
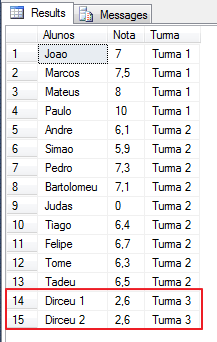
Inserte varios nodos en XML desde una variable SQL:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
DECLARE @Inserir XML = '
<Turma Nome="Turma 3" Serie="3">
<Aluno Apostolo="0" Traidor="0" Nota="2.6">Dirceu 1</Aluno>
<Aluno Apostolo="0" Traidor="0" Nota="2.6">Dirceu 2</Aluno>
</Turma>'
SET @XML.modify('insert sql:variable("@Inserir")
into (//Escola)[1]')
SELECT
Alunos.linha.value('.', 'varchar(100)') AS Alunos,
Alunos.linha.value('@Nota', 'float') AS Nota,
Alunos.linha.value('../@Nome', 'varchar(100)') AS Turma
FROM
@XML.nodes('//Aluno') Alunos(linha)
Usando expresiones XQuery FLOWR en XML
El recurso FLOWR (pronunciado “flor”) es una poderosa herramienta y extensión de la función QUERY, que le permite iterar a través de archivos XML y realizar una serie de operaciones. Los comandos son PARA, DEJAR, ORDENAR POR, DÓNDE y DEVOLVER. Veamos a continuación cómo utilizarlos.
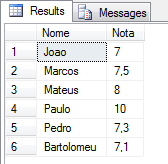
Usando FOR iteración:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
DECLARE @XML2 XML = (SELECT @XML.query('for $A in //Aluno[@Nota>=7] return $A'))
SELECT
Alunos.linha.value('.', 'varchar(100)') AS Nome,
Alunos.linha.value('@Nota', 'float') AS Nota
FROM
@XML2.nodes('//Aluno') Alunos(linha)
Usando la iteración FOR, WHERE y ORDER BY:
DECLARE @XML XML = (SELECT TOP 1 Ds_XML FROM #XML2)
DECLARE @XML2 XML = (SELECT @XML.query('
for $A
in //Aluno
where ($A = "Pedro" or $A = "Marcos" or $A = "Andre" or $A = "Joao")
order by $A descending
return $A'))
SELECT
Alunos.linha.value('.', 'varchar(100)') AS Nome,
Alunos.linha.value('@Nota', 'float') AS Nota
FROM
@XML2.nodes('//Aluno') Alunos(linha)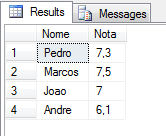
Usando el comando LET para cambiar el valor de la información y dar un aumento del 20% a dos empleados:
En este ejemplo específico, creo el XML en tiempo real, ya que mi segundo XML de ejemplo no tenía valores de datos, solo atributos, lo que hace imposible usarlo junto con la función de consulta.
DECLARE @XML XML = '
<Empresa>
<Funcionario>
<Nome>Joao</Nome>
<Salario>1250.28</Salario>
</Funcionario>
<Funcionario>
<Nome>Pedro</Nome>
<Salario>1754.54</Salario>
</Funcionario>
<Funcionario>
<Nome>Paulo</Nome>
<Salario>5487.99</Salario>
</Funcionario>
</Empresa>'
DECLARE @XML_Modificado XML = (SELECT @XML.query('
for $A
in //Funcionario
let $T := 1.20
where $A/Nome != "Pedro"
return
<Funcionario>
<Nome>{data($A/Nome)}</Nome>
<NovoSalario>{data($A/Salario/text())[1] * data($T)}</NovoSalario>
</Funcionario>'))
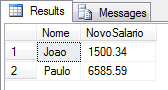
SELECT
Funcionarios.linha.value('Nome[1]', 'varchar(100)') AS Nome,
Funcionarios.linha.value('NovoSalario[1]', 'numeric(18,2)') AS NovoSalario
FROM
@XML_Modificado.nodes('//Funcionario') Funcionarios(linha)
Exportación de datos de bases de datos a XML: PARA XML RAW, AUTO, EXPLICIT, PATH
Después de mucho hablar sobre importar y procesar archivos XML, finalmente ha llegado el momento de hacer lo contrario. Cómo transformar datos de una tabla de SQL Server a una cadena XML.
Para facilitar esta tarea, SQL Server proporciona 4 formas de hacerlo con FOR XML: RAW, AUTO, EXPLICI y PATH. Averigüemos ahora para qué sirven y cómo utilizarlos.
Creación de la mesa de prueba:
IF (OBJECT_ID('dbo.Teste_XML') IS NOT NULL) DROP TABLE dbo.Teste_XML
CREATE TABLE dbo.Teste_XML (
Categoria VARCHAR(100),
Descricao VARCHAR(100)
)
INSERT INTO dbo.Teste_XML ( Categoria, Descricao )
VALUES ('Brinquedo', 'Bola'),
('Brinquedo', 'Carrinho'),
('Brinquedo', 'Boneco'),
('Brinquedo', 'Jogo'),
('Cama e Mesa', 'Toalha'),
('Cama e Mesa', 'Edredom'),
('Informatica', 'Teclado'),
('Informatica', 'Mouse'),
('Informatica', 'HD'),
('Informatica', 'CPU'),
('Informatica', 'Memoria'),
('Informatica', 'Placa-Mae'),
(NULL, 'TV')
PARA XML SIN PROCESAR
El método RAW de FOR XML genera un XML a partir de nuestra tabla donde cada columna se convierte en un atributo del XML generado y cada línea representará un nodo (elemento).
SELECT *
FROM dbo.Teste_XML
FOR XML RAW
XML generado:
<row Categoria="Brinquedo" Descricao="Bola" />
<row Categoria="Brinquedo" Descricao="Carrinho" />
<row Categoria="Brinquedo" Descricao="Boneco" />
<row Categoria="Brinquedo" Descricao="Jogo" />
<row Categoria="Cama e Mesa" Descricao="Toalha" />
<row Categoria="Cama e Mesa" Descricao="Edredom" />
<row Categoria="Informatica" Descricao="Teclado" />
<row Categoria="Informatica" Descricao="Mouse" />
<row Categoria="Informatica" Descricao="HD" />
<row Categoria="Informatica" Descricao="CPU" />
<row Categoria="Informatica" Descricao="Memoria" />
<row Categoria="Informatica" Descricao="Placa-Mae" />
<row Descricao="TV" />
En el siguiente ejemplo, agregaré la opción ROOT después de RAW(), para agregar un elemento raíz que será el nodo padre de los nodos creados. Esto es opcional, si no lo usas, la única diferencia es que no se creará el elemento
SELECT *
FROM dbo.Teste_XML
FOR XML RAW('Produto'), ROOT('Produtos')
XML generado:
<Produtos>
<Produto Categoria="Brinquedo" Descricao="Bola" />
<Produto Categoria="Brinquedo" Descricao="Carrinho" />
<Produto Categoria="Brinquedo" Descricao="Boneco" />
<Produto Categoria="Brinquedo" Descricao="Jogo" />
<Produto Categoria="Cama e Mesa" Descricao="Toalha" />
<Produto Categoria="Cama e Mesa" Descricao="Edredom" />
<Produto Categoria="Informatica" Descricao="Teclado" />
<Produto Categoria="Informatica" Descricao="Mouse" />
<Produto Categoria="Informatica" Descricao="HD" />
<Produto Categoria="Informatica" Descricao="CPU" />
<Produto Categoria="Informatica" Descricao="Memoria" />
<Produto Categoria="Informatica" Descricao="Placa-Mae" />
<Produto Descricao="TV" />
</Produtos>
Incluso en RAW XML podemos devolver las columnas como elementos XML. Para ello basta con incluir la opción ELEMENTOS:
SELECT *
FROM dbo.Teste_XML
FOR XML RAW('Produto'), ROOT('Produtos'), ELEMENTS
XML generado (solo un fragmento para que no sea demasiado largo):
<Produtos>
<Produto>
<Categoria>Brinquedo</Categoria>
<Descricao>Bola</Descricao>
</Produto>
<Produto>
<Categoria>Brinquedo</Categoria>
<Descricao>Carrinho</Descricao>
</Produto>
<Produto>
<Categoria>Brinquedo</Categoria>
<Descricao>Boneco</Descricao>
</Produto>
</Produtos>
Otra opción interesante de FOR XML es cuando se trata de datos vacíos (NULL). Cuando no realizamos ningún tratamiento simplemente se ignoran y no se generan, como ocurre con la categoría de producto “TV”. Para manejar esto, podemos usar la opción XSINIL después de la opción ELEMENTS, que agregará el elemento vacío y creará un atributo informando esto (xsi:nil=”true”):
SELECT *
FROM dbo.Teste_XML
FOR XML RAW('Produto'), ROOT('Produtos'), ELEMENTS XSINIL
Y luego el XML con el producto se genera así:
<Produto>
<Categoria xsi:nil="true" />
<Descricao>TV</Descricao>
</Produto>
Además, podemos utilizar la opción XMLSCHEMA para transformar nuestro XML en un XSD completo:
SELECT *
FROM dbo.Teste_XML
FOR XML RAW('Produto'), ROOT('Produtos'), ELEMENTS XSINIL, XMLSCHEMA

PARA XML AUTOMÁTICO
El modo AUTO de FOR XML es muy similar al RAW, pero con la diferencia de que en su uso estándar, el nombre de la tabla es el nombre predeterminado de cada elemento.
SELECT *
FROM dbo.Teste_XML
FOR XML AUTO
XML generado:
<dbo.Teste_XML Categoria="Brinquedo" Descricao="Bola" />
<dbo.Teste_XML Categoria="Brinquedo" Descricao="Carrinho" />
<dbo.Teste_XML Categoria="Brinquedo" Descricao="Boneco" />
<dbo.Teste_XML Categoria="Brinquedo" Descricao="Jogo" />
<dbo.Teste_XML Categoria="Cama e Mesa" Descricao="Toalha" />
<dbo.Teste_XML Categoria="Cama e Mesa" Descricao="Edredom" />
<dbo.Teste_XML Categoria="Informatica" Descricao="Teclado" />
<dbo.Teste_XML Categoria="Informatica" Descricao="Mouse" />
<dbo.Teste_XML Categoria="Informatica" Descricao="HD" />
<dbo.Teste_XML Categoria="Informatica" Descricao="CPU" />
<dbo.Teste_XML Categoria="Informatica" Descricao="Memoria" />
<dbo.Teste_XML Categoria="Informatica" Descricao="Placa-Mae" />
<dbo.Teste_XML Descricao="TV" />
PARA RUTA XML
XML PATH es un poco diferente de los otros dos ejemplos en que los nombres de columnas y alias se tratan como elementos XPATH. Cuando generas un XML común, sin personalizar, incluye un elemento raíz (fila), donde cada línea es un elemento hijo, un nivel de jerarquía debajo y cada columna también es un elemento del XML, más otro nivel debajo:
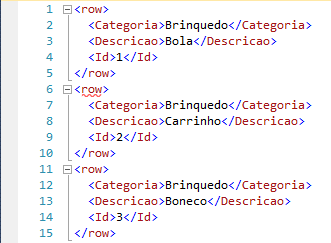
Al igual que XML AUTO y XML RAW, podemos usar ROOT('NomeDaRaiz') para crear el elemento raíz, también podemos usar la opción ELEMENTS con XSINIL (para devolver incluso elementos nulos).
Nota: Como XML PATH siempre devuelve columnas como elementos, usar solo la opción ELEMENTS no tendrá ningún efecto, solo si se usa junto con XSINIL.
Creando jerarquías con XML PATH:
SELECT
Id AS '@Id_Produto', -- Atributo
Categoria AS 'DadosProduto/Categoria', -- Elemento
Descricao AS 'DadosProduto/Descricao'-- Elemento
FROM
dbo.Teste_XML
FOR XML PATH('Produto'), ROOT('Produtos'), ELEMENTS
XML generado:

PARA XML EXPLÍCITO
El modo EXPLICIT de FOR XML tiende a ser muy diferente de otros modos. Esto se debe a que requiere un encabezado en un formato específico, que defina jerarquía y estructuras. Este encabezado debe haber unido los datos usando UNION ALL.
El encabezado SELECT debe tener la siguiente estructura:
- Primera columna: Es un número que define el nivel de la jerarquía. El nombre de la columna debe ser Etiqueta.
- Segunda columna: Es un número que define el nivel de jerarquía del elemento padre (o NULL, si no lo tiene y es la raíz). El nombre de la columna debe ser Padre.
- Tercera columna en adelante: Estos son los datos que formarán parte del XML y que su XML devolverá.
Tenga en cuenta que desde el principio debemos definir todas las columnas que formarán parte del XML en el encabezado.
El formato predeterminado para la definición de campo se define de la siguiente manera:
<NomeDoElemento>!<NúmeroDaTag>!<NomeDoAtributo>[!<InformacoesAdicionais>]
Dónde:
- Nombre del elemento: Es el nombre del elemento padre que estamos generando (En el caso del ejemplo, Productos)
- Número de etiqueta: Es el número del nivel de jerarquía de los elementos secundarios.
- Nombre del atributo: Es el nombre de cada atributo/columna de los datos que estamos exportando a XML (en el caso del ejemplo, Categoría y Descripción)
- información adicional: datos adicionales que se pueden utilizar en la creación del XML
Veamos ahora cómo funciona esto en la práctica:
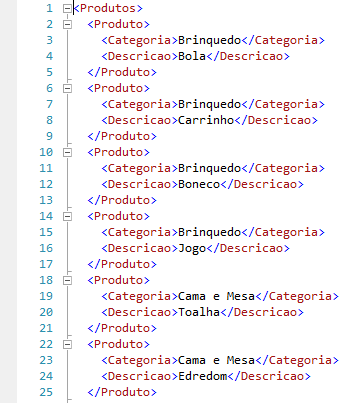
-- Cabeçalho
SELECT
1 AS Tag,
NULL AS Parent,
NULL AS [Produtos!1!Id],
NULL AS [Produto!2!Categoria!ELEMENT],
NULL AS [Produto!2!Descricao!ELEMENT]
UNION ALL
-- Conteúdo
SELECT
2 AS Tag,
1 AS Parent,
NULL,
Categoria,
Descricao
FROM
dbo.Teste_XML
FOR
XML EXPLICIT
Extracto del XML devuelto:
Para hacer el ejemplo más interesante, agregaré una nueva columna a nuestra tabla:
ALTER TABLE dbo.Teste_XML ADD Id INT IDENTITY(1,1)
Generando el XML nuevamente:
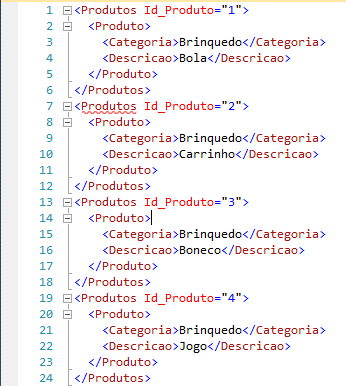
-- Cabeçalho
SELECT
1 AS Tag,
NULL AS Parent,
Id AS [Produtos!1!Id_Produto],
NULL AS [Produto!2!Categoria!ELEMENT],
NULL AS [Produto!2!Descricao!ELEMENT]
FROM
dbo.Teste_XML
UNION ALL
-- Conteúdo
SELECT
2 AS Tag,
1 AS Parent,
Id AS Id_Produto,
ISNULL(Categoria, ''),
Descricao
FROM
dbo.Teste_XML
ORDER BY
[Produtos!1!Id_Produto],
[Produto!2!Categoria!ELEMENT]
FOR
XML EXPLICIT
Nuestro resultado será este:
Cabe mencionar que este ORDER BY utilizado es necesario para que los resultados se muestren de la forma correcta. De lo contrario, los elementos se generarán en el orden incorrecto y el XML no tendrá el mismo resultado.
Como podemos ver, el nuevo campo agregado (ID) es un atributo XML. Si desea convertirlo en un atributo, simplemente agregue !ELEMENT a su encabezado:
-- Cabeçalho
SELECT
1 AS Tag,
NULL AS Parent,
Id AS [Produtos!1!Id_Produto!ELEMENT],
NULL AS [Produto!2!Categoria!ELEMENT],
NULL AS [Produto!2!Descricao!ELEMENT]
FROM
dbo.Teste_XML
UNION ALL
-- Conteúdo
SELECT
2 AS Tag,
1 AS Parent,
Id AS Id_Produto,
ISNULL(Categoria, ''),
Descricao
FROM
dbo.Teste_XML
ORDER BY
[Produtos!1!Id_Produto!ELEMENT],
[Produto!2!Categoria!ELEMENT]
FOR
XML EXPLICIT
Quedando así:

En los dos ejemplos anteriores, agregué una cláusula ISNULL() a la categoría, ya que el producto "TV" no tiene una categoría definida. Cuando esto ocurre en modo EXPLÍCITO, y se utiliza la categoría para ordenar los resultados, los elementos acaban perdiéndose y los que no tienen categoría acaban junto con elementos de otras categorías.
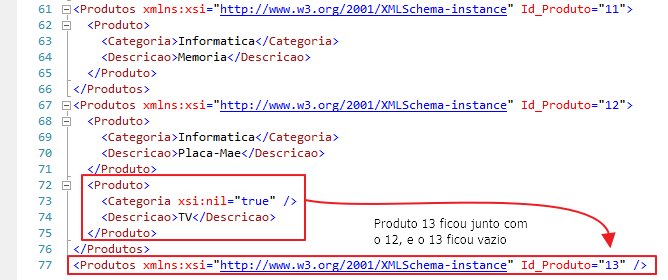
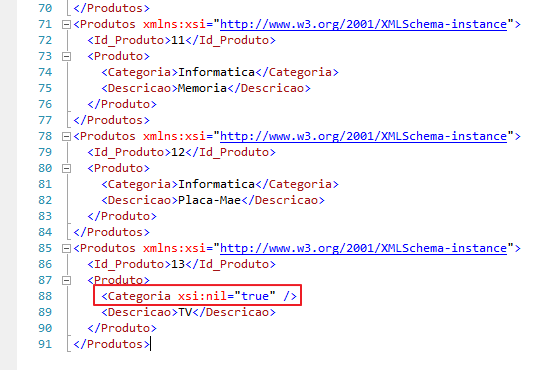
Otra forma de solucionar este problema, además de agregar ISNULL(), es definiendo el tipo de atributo ELEMENTXSINIL en el encabezado de nuestra estructura SELECT y no usar esta columna que tiene posibles valores NULL en el ORDER BY:
-- Cabeçalho
SELECT
1 AS Tag,
NULL AS Parent,
Id AS [Produtos!1!Id_Produto!ELEMENT],
NULL AS [Produto!2!Categoria!ELEMENTXSINIL],
NULL AS [Produto!2!Descricao!ELEMENT]
FROM
dbo.Teste_XML
UNION ALL
-- Conteúdo
SELECT
2 AS Tag,
1 AS Parent,
Id AS Id_Produto,
Categoria,
Descricao
FROM
dbo.Teste_XML
ORDER BY
[Produtos!1!Id_Produto!ELEMENT],
[Produto!2!Descricao!ELEMENT]
FOR
XML EXPLICIT
XML generado:
Si tienes alguna duda o sugerencia déjala aquí en los comentarios.
¡Gracias por visitarnos y hasta la próxima!
servidor SQL cómo aprender a trabajar usar leer importar tratar aprendizaje de archivos de cadena xml
servidor SQL cómo aprender a trabajar usar leer importar tratar aprendizaje de archivos de cadena xml

Comentários (0)
Carregando comentários…