En este post hablaré un poco sobre el método de compresión de datos de SQL Server y cómo podemos usar esta característica para comprimir todos los objetos en una base de datos. La compresión de datos se puede configurar para los siguientes objetos de base de datos:
- Para una tabla que se almacena como un montón.
- Para una tabla que se almacena como un índice agrupado.
- Para un índice no agrupado.
- Para una vista indexada.
- Para índices y tablas particionadas, la opción de compresión se puede configurar para cada partición y las distintas particiones de un objeto pueden contener diferentes configuraciones de compresión.
Recuerde que la compresión no está disponible para los objetos del sistema y la configuración de compresión no se aplica automáticamente a los índices no agrupados. Por lo tanto, cada índice no agrupado debe configurarse de forma individual y manual.
NIVEL DE COMPRESIÓN DE FILA
Esta característica de compresión tiene en cuenta el tipo de estructuras de datos variables que definen una columna. El nivel de compresión de fila es un nivel de compresión que no utiliza ningún algoritmo de compresión.
El objetivo principal del nivel de compresión de filas es reducir el almacenamiento de datos de tipo fijo, es decir, cuando habilita la compresión de nivel de filas solo está cambiando el formato de almacenamiento físico de los datos asociados con un tipo de datos.
La compresión de nivel de fila amplía el formato de almacenamiento vardecimal al almacenar datos de todos los tipos de longitud fija en un formato de almacenamiento de longitud variable. Este tipo de compresión eliminará los bytes adicionales en el tipo de datos fijo. No se requieren absolutamente ningún cambio en la aplicación.
Por ejemplo, tenemos una columna CHAR(100) que usa el nivel de compresión de filas y solo usará la cantidad de almacenamiento definida por los datos. ¿Como esto? Almacenemos la frase “SQL Server 2008″ en la columna, la frase contiene solo 15 caracteres y solo se almacenan estos 15 caracteres a diferencia de los 100 que fueron definidos por la columna, por lo tanto, tienes un ahorro del 85% en espacio de almacenamiento.
NIVEL DE COMPRESIÓN DE PÁGINA
En versiones anteriores de SQL Server, cada valor se almacenaba en la página, independientemente de si el mismo valor ya había aparecido en la misma columna para otras filas dentro de una página. En SQL Server 2008, el valor redundante o duplicado se almacenará sólo una vez dentro de la página y se hará referencia a él en todas las demás apariciones, por lo que tenemos el nivel de compresión de página.
Básicamente, el nivel de compresión de página es un superconjunto de compresión de FILAS y tiene en cuenta datos redundantes en una o más filas de una página determinada. También utiliza compresión de prefijos y diccionarios.
El método del nivel de compresión de página es más importante ya que permite compartir datos comunes entre filas de una página determinada.
Este tipo de compresión utiliza las siguientes técnicas:
- COMPRESIÓN DE FILAS: Ya visto arriba.
- COMPRESIÓN DE PREFIJOS: Para cada columna de una página se identifican prefijos duplicados. Estos prefijos se almacenan en los encabezados de Compresión de información (CI), que se encuentran después del encabezado de la página. Se asigna un número de referencia a estos prefijos y este número de referencia se utiliza dondequiera que se utilicen estos prefijos, disminuyendo la cantidad de bytes utilizados.
- COMPRESIÓN DEL DICCIONARIO: Busca valores duplicados fuera de la página y los almacena en el CI. La principal diferencia entre la compresión de prefijo y la compresión de diccionario es que el prefijo está restringido a una sola columna, mientras que el diccionario se aplica a toda la página.
Una vez completada la compresión de prefijos, se aplica la compresión de diccionario, busca valores repetidos en cualquier lugar de la página y los almacena en el área CI. A diferencia de la compresión de prefijos, la compresión de diccionarios no se limita a una columna y puede reemplazar valores repetidos que aparecen en cualquier lugar de una página.
Estimación de la ganancia de espacio
En SQL Server 2008 existen dos formas de estimar el ahorro de espacio para almacenar tablas e índices. El primer método es utilizar un SP del sistema llamado sp_estimate_data_compression_ Savings y el segundo método es utilizar el Asistente de compresión de datos.
Primero usemos sp_estimate_data_compression_ Savings donde:
El primer parámetro es el nombre del esquema;
El segundo parámetro es el nombre del objeto;
El tercer parámetro es el ID del índice;
El cuarto parámetro es el ID de la partición.
El quinto parámetro es el tipo de compresión;
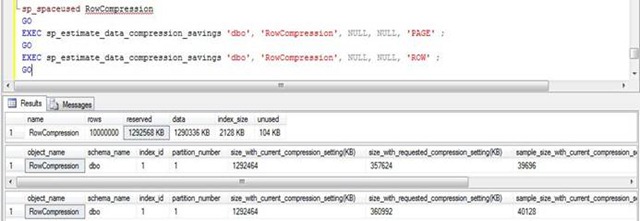
Tenga en cuenta las columnas size_with_current_compression_setting(KB) y size_with_requested_compression_setting(KB), estas columnas muestran el valor actual y el valor después de la compresión. De esta forma podremos saber cuánto espacio ganaremos aplicando compresión.
Ahora usemos el asistente.
Haga clic derecho en la tabla y elija Storege -> Administrar compresión
Se abrirá la pantalla del asistente de compresión.
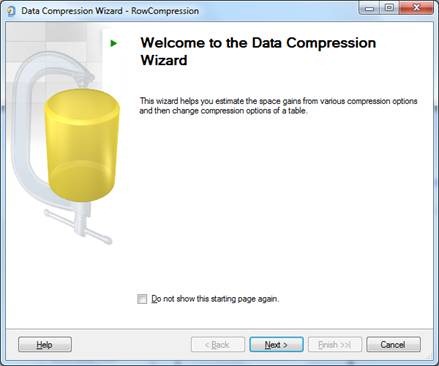
En la siguiente pantalla del reloj podrás probar el tipo de compresión y antes de aplicarla podrás calcular el espacio para comprobar cuál tenía la mayor tasa de compresión de datos.
Continuando con el asistente de compresión, elegí la opción PÁGINA, que generalmente obtiene el mejor resultado, y luego me preguntará qué hacer: simplemente generar el script, ejecutar la compresión o programar el cambio para activar la compresión.
Finalmente, se mostrará en la pantalla un mensaje de éxito de la compresión de datos.
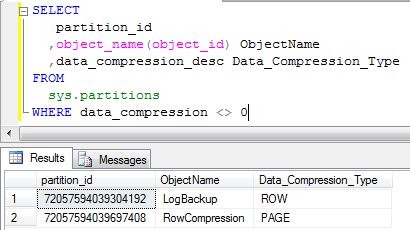
Puede verificar todos sus objetos y qué niveles de compresión tienen haciendo clic derecho en el objeto, en la pestaña Almacenamiento, la opción Compresión informa el tipo de compresión o usando el comando:
SELECT
A.[partition_id],
A.[object_id],
object_name(A.[object_id]) AS [object_name],
data_compression_desc
FROM
sys.partitions A
join sys.objects B on A.[object_id] = B.[object_id]
WHERE
B.is_ms_shipped = 0
Aplicar compresión a una base de datos completa
En este post ya hemos visto lo beneficiosa que es la compresión de datos, especialmente para el almacenamiento. Bueno, pongamos esto en práctica. Creé un procedimiento que te permite compactar todos los objetos en una base de datos, fácil y rápidamente. El código del procedimiento está disponible aquí:
CREATE PROCEDURE [dbo].[stpCompacta_Database] (
@Ds_Database SYSNAME,
@Fl_Rodar_Shrink BIT = 1,
@Fl_Parar_Se_Falhar BIT = 1,
@Fl_Exibe_Comparacao_Tamanho BIT = 1,
@Fl_Metodo_Compressao_Page BIT = 1
)
AS
BEGIN
SET NOCOUNT ON
DECLARE
@Ds_Query VARCHAR(MAX),
@Ds_Comando_Compactacao VARCHAR(MAX),
@Ds_Metodo_Compressao VARCHAR(20) = (CASE WHEN @Fl_Metodo_Compressao_Page = 1 THEN 'PAGE' ELSE 'ROW' END),
@Nr_Metodo_Compressao VARCHAR(20) = (CASE WHEN @Fl_Metodo_Compressao_Page = 1 THEN 2 ELSE 1 END)
IF (OBJECT_ID('tempdb..#Comandos_Compactacao') IS NOT NULL) DROP TABLE #Comandos_Compactacao
CREATE TABLE #Comandos_Compactacao
(
Id BIGINT IDENTITY(1, 1),
Tabela SYSNAME,
Indice SYSNAME NULL,
Comando VARCHAR(MAX)
)
IF (@Fl_Exibe_Comparacao_Tamanho = 1)
BEGIN
SET @Ds_Query = '
SELECT
(SUM(a.total_pages) / 128) AS Vl_Tamanho_Tabelas_Antes_Compactacao
FROM
[' + @Ds_Database + '].sys.tables t WITH(NOLOCK)
INNER JOIN [' + @Ds_Database + '].sys.indexes i WITH(NOLOCK) ON t.OBJECT_ID = i.object_id
INNER JOIN [' + @Ds_Database + '].sys.partitions p WITH(NOLOCK) ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN [' + @Ds_Database + '].sys.allocation_units a WITH(NOLOCK) ON p.partition_id = a.container_id
WHERE
i.OBJECT_ID > 255
'
EXEC(@Ds_Query)
END
SET @Ds_Query =
'INSERT INTO #Comandos_Compactacao( Tabela, Indice, Comando )
SELECT DISTINCT
A.name AS Tabela,
NULL AS Indice,
''ALTER TABLE ['' + ''' + @Ds_Database + ''' + ''].['' + C.name + ''].['' + A.name + ''] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = ' + @Ds_Metodo_Compressao + ')'' AS Comando
FROM
[' + @Ds_Database + '].sys.tables A
INNER JOIN [' + @Ds_Database + '].sys.partitions B ON A.object_id = B.object_id
INNER JOIN [' + @Ds_Database + '].sys.schemas C ON A.schema_id = C.schema_id
WHERE
B.data_compression <> ' + @Nr_Metodo_Compressao + ' -- NONE
AND B.data_compression_desc NOT LIKE ''COLUMNSTORE%''
AND B.index_id = 0
AND A.type = ''U''
UNION
SELECT DISTINCT
B.name AS Tabela,
A.name AS Indice,
''ALTER INDEX ['' + A.name + ''] ON ['' + ''' + @Ds_Database + ''' + ''].['' + C.name + ''].['' + B.name + ''] REBUILD PARTITION = ALL WITH ( STATISTICS_NORECOMPUTE = OFF, ONLINE = OFF, SORT_IN_TEMPDB = OFF, DATA_COMPRESSION = ' + @Ds_Metodo_Compressao + ')''
FROM
[' + @Ds_Database + '].sys.indexes A
INNER JOIN [' + @Ds_Database + '].sys.tables B ON A.object_id = B.object_id
INNER JOIN [' + @Ds_Database + '].sys.schemas C ON B.schema_id = C.schema_id
INNER JOIN [' + @Ds_Database + '].sys.partitions D ON A.object_id = D.object_id AND A.index_id = D.index_id
WHERE
D.data_compression <> ' + @Nr_Metodo_Compressao + ' -- NONE
AND D.data_compression_desc NOT LIKE ''COLUMNSTORE%''
AND D.index_id <> 0
AND B.type = ''U''
ORDER BY
Tabela,
Indice
'
EXEC(@Ds_Query)
DECLARE
@Qt_Comandos INT = (SELECT COUNT(*) FROM #Comandos_Compactacao),
@Contador INT = 1,
@Ds_Mensagem VARCHAR(MAX),
@Nr_Codigo_Erro INT = (CASE WHEN @Fl_Parar_Se_Falhar = 1 THEN 16 ELSE 10 END)
WHILE(@Contador <= @Qt_Comandos)
BEGIN
SELECT
@Ds_Comando_Compactacao = Comando
FROM
#Comandos_Compactacao
WHERE
Id = @Contador
BEGIN TRY
SET @Ds_Mensagem = 'Executando comando "' + @Ds_Comando_Compactacao + '"... Aguarde...'
RAISERROR(@Ds_Mensagem, 10, 1) WITH NOWAIT
EXEC(@Ds_Comando_Compactacao)
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() AS ErrorState,
ERROR_PROCEDURE() AS ErrorProcedure,
ERROR_LINE() AS ErrorLine,
ERROR_MESSAGE() AS ErrorMessage;
SET @Ds_Mensagem = 'Falha ao executar o comando "' + @Ds_Comando_Compactacao + '"'
RAISERROR(@Ds_Mensagem, @Nr_Codigo_Erro, 1) WITH NOWAIT
RETURN
END CATCH
SET @Contador = @Contador + 1
END
IF (@Fl_Exibe_Comparacao_Tamanho = 1)
BEGIN
SET @Ds_Query = '
SELECT
(SUM(a.total_pages) / 128) AS Vl_Tamanho_Tabelas_Depois_Compactacao
FROM
[' + @Ds_Database + '].sys.tables t WITH(NOLOCK)
INNER JOIN [' + @Ds_Database + '].sys.indexes i WITH(NOLOCK) ON t.OBJECT_ID = i.object_id
INNER JOIN [' + @Ds_Database + '].sys.partitions p WITH(NOLOCK) ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN [' + @Ds_Database + '].sys.allocation_units a WITH(NOLOCK) ON p.partition_id = a.container_id
WHERE
i.OBJECT_ID > 255
'
EXEC(@Ds_Query)
END
IF (@Fl_Rodar_Shrink = 1)
BEGIN
SET @Ds_Query = '
USE ' + @Ds_Database + '
DBCC SHRINKFILE (' + @Ds_Database + ', 1) WITH NO_INFOMSGS
'
EXEC(@Ds_Query)
END
IF (@Qt_Comandos > 0)
PRINT 'Database "' + @Ds_Database + '" compactado com sucesso!'
ELSE
PRINT 'Nenhum objeto para compactar no database "' + @Ds_Database + '"'
ENDEjemplo de uso:
EXEC dbo.stpCompacta_Database
@Ds_Database = 'Testes', -- sysname
@Fl_Rodar_Shrink = 1, -- bit
@Fl_Parar_Se_Falhar = 0, -- bit
@Fl_Exibe_Comparacao_Tamanho = 1, -- bit
@Fl_Metodo_Compressao_Page = 1 -- bit
Nota: No recomiendo utilizar la opción @Fl_Rodar_Shrink en entornos de producción.
servidor SQL, comprimir tabla, comprimir base de datos, comprimir, comprimir, compactar, reducir

Comentários (0)
Carregando comentários…