¿Qué pasa, chicos?
¿Listo para otro consejo?
Introducción
En este artículo me gustaría demostrarle algunas formas de cargar datos de forma rápida y eficiente en la base de datos, utilizando la menor cantidad de registros posible. Esto es especialmente útil para escenarios de preparación en procesos de BI/almacén de datos, donde los datos deben cargarse rápidamente y la posible pérdida de datos es aceptable (ya que el proceso se puede rehacer en caso de falla).
El propósito de este artículo es comparar el rendimiento de las más diversas formas de inserción de datos, como tablas temporales, variables de tipo tabla, combinaciones de modelo_recuperación, tipos de compresión y tablas optimizadas para memoria (In-Memory OLTP), con el objetivo de demostrar cuán eficiente es esta característica.
Cabe mencionar que la función OLTP en memoria está disponible desde SQL Server 2014 y tiene mejoras significativas en SQL Server 2016 y SQL Server 2017.
Pruebas que utilizan soluciones basadas en disco
Ver contenidoScript base utilizado:
SET STATISTICS TIME OFF
SET NOCOUNT ON
IF (OBJECT_ID('dirceuresende.dbo.Staging_Sem_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Sem_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Sem_JOIN ( Contador INT, Nome VARCHAR(50), Idade INT, [Site] VARCHAR(200) )
GO
IF (OBJECT_ID('dirceuresende.dbo.Staging_Com_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Com_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Com_JOIN ( Contador INT, [Dt_Venda] datetime, [Vl_Venda] float(8), [Nome_Cliente] varchar(100), [Nome_Produto] varchar(100), [Ds_Forma_Pagamento] varchar(100) )
GO
DECLARE
@Contador INT = 1,
@Total INT = 100000,
@Dt_Log DATETIME,
@Qt_Duracao_1 INT,
@Qt_Duracao_2 INT
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste simples
INSERT INTO dirceuresende.dbo.Staging_Sem_JOIN ( Contador, Nome, Idade, [Site] )
VALUES (@Contador, 'Dirceu Resende', 31, 'https://dirceuresende.com/')
SET @Contador += 1
END
SET @Qt_Duracao_1 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SET @Total = 10000
SET @Contador = 1
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste com JOIN
INSERT INTO dirceuresende.dbo.Staging_Com_JOIN
SELECT @Contador, A.Dt_Venda, A.Vl_Venda, B.Ds_Nome AS Nome_Cliente, C.Ds_Nome AS Nome_Produto, D.Ds_Nome AS Ds_Forma_Pagamento
FROM dirceuresende.dbo.Fato_Venda A
JOIN dirceuresende.dbo.Dim_Cliente B ON A.Cod_Cliente = B.Codigo
JOIN dirceuresende.dbo.Dim_Produto C ON A.Cod_Produto = C.Codigo
JOIN dirceuresende.dbo.Dim_Forma_Pagamento D ON A.Cod_Forma_Pagamento = D.Codigo
SET @Contador += 1
END
SET @Qt_Duracao_2 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SELECT @Qt_Duracao_1 AS Duracao_Sem_JOIN, @Qt_Duracao_2 AS Duracao_Com_JOIN
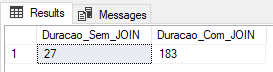
Usando tabla física (modelo de recuperación COMPLETO)
En esta prueba, usaré una tabla física con el Modelo de Recuperación COMPLETO.
ALTER DATABASE [dirceuresende] SET RECOVERY FULL
GOResultado:
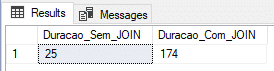
Usando tabla física (modelo de recuperación SIMPLE)
En esta prueba, usaré una tabla física con el Modelo de Recuperación en SIMPLE, que genera menos información en el registro de transacciones y, en teoría, debería entregar una carga más rápida.
ALTER DATABASE [dirceuresende] SET RECOVERY SIMPLE
GOResultado:
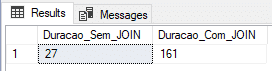
Usando tabla física (modelo de recuperación BULK-LOGGED)
En esta prueba usaré una tabla física con el Modelo de Recuperación en BULK-LOGGED, que está optimizada para procesos por lotes y cargas de datos.
ALTER DATABASE [dirceuresende] SET RECOVERY BULK_LOGGED
GOResultado:
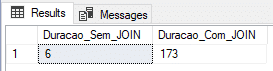
Usando tabla física y DELAYED_DURABILITY (modelo de recuperación BULK-LOGGED)
En esta prueba, usaré una tabla física con el Modelo de Recuperación en BULK-LOGGED, que está optimizado para procesos por lotes y cargas de datos y también el parámetro DELAYED_DURABILITY = FORCED, que hace que los eventos de registro se escriban de forma forzada y asincrónica (obtenga más información sobre esta característica accediendo a este enlace ou esta publicación aquí).
ALTER DATABASE [dirceuresende] SET RECOVERY BULK_LOGGED
GO
ALTER DATABASE dirceuresende SET DELAYED_DURABILITY = FORCED
GOResultado:
Usando tabla temporal (modelo de recuperación SIMPLE)
Ampliamente utilizado para tablas generadas dinámicamente y procesos rápidos, realizaré la prueba insertando los datos en una tabla #temporal (#Staging_Sem_JOIN y #Staging_Com_JOIN). Mi tempdb está utilizando el modelo de recuperación SIMPLE.
Resultado:
Usando variable de tipo tabla
Ampliamente utilizado para tablas generadas dinámicamente y procesos rápidos, así como la tabla #temporal, realizaré la prueba insertando los datos en una variable como @tabela (@Staging_Sem_JOIN y @Staging_Com_JOIN).
Resultado:
OLTP en memoria (IMO)
Ver contenidoImplementación de OLTP en memoria
Ver contenidoAgregar soporte en memoria a su base de datos
Para probar qué tan rápido se puede comparar OLTP en memoria con otros métodos utilizados, primero debemos agregar un grupo de archivos a nuestra base de datos optimizada para datos en memoria. Este es un requisito previo para utilizar In-Memory.
Para agregar este grupo de archivos "especial", puede utilizar la interfaz de SQL Server Management Studio:
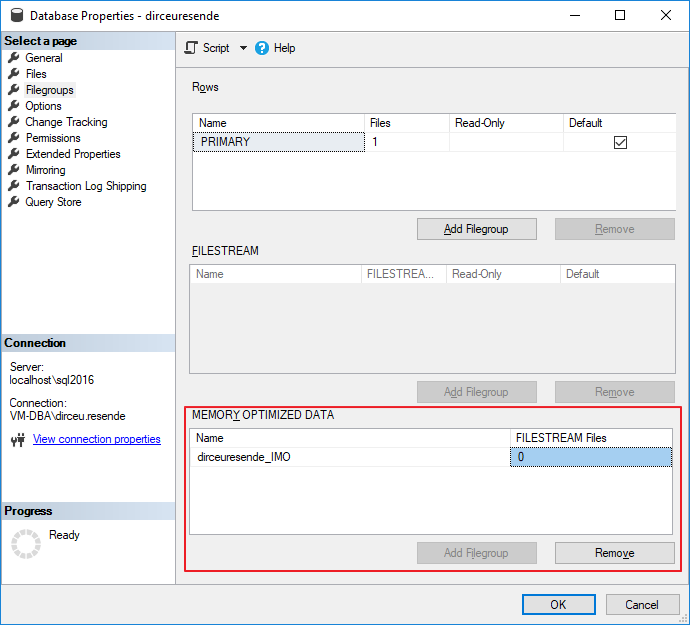
Pero al agregar un archivo al grupo de archivos, la interfaz SSMS (versión 17.5) aún no lo admite, no me muestra el grupo de archivos en memoria que ya se había creado y tengo que agregar el archivo usando comandos T-SQL.
Para agregar el grupo de archivos y también los archivos, puede usar el siguiente comando T-SQL:
USE [master]
GO
ALTER DATABASE [dirceuresende] ADD FILEGROUP [dirceuresende_IMO] CONTAINS MEMORY_OPTIMIZED_DATA
GO
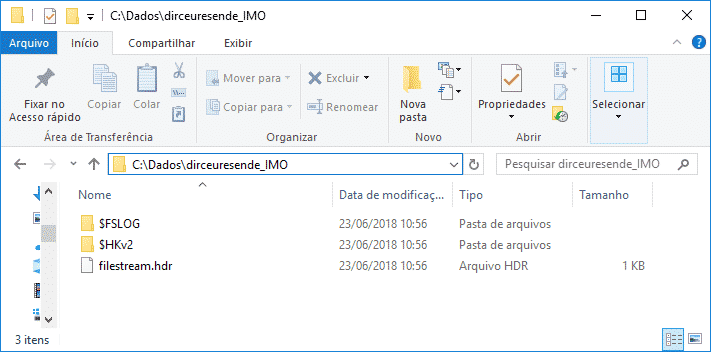
ALTER DATABASE [dirceuresende] ADD FILE ( NAME = [dirceuresende_dados_IMO], FILENAME = 'C:\Dados\dirceuresende_IMO\' ) TO FILEGROUP [dirceuresende_IMO]
GO
Tenga en cuenta que en In-Memory, a diferencia de un grupo de archivos común, no especifica la extensión del archivo porque, de hecho, se crea un directorio con varios archivos alojados en él.
IMPORTANTE: Hasta la versión actual (2017), no es posible eliminar un grupo de archivos de tipo MEMORY_OPTIMIZED_DATA, es decir, una vez creado, solo se puede eliminar si se descarta todo el banco. Por lo tanto, recomiendo crear una nueva base de datos solo para tablas en memoria.
OLTP en memoria: duradero versus no duradero
Ahora que hemos creado nuestro grupo de archivos y le hemos agregado al menos 1 archivo, podemos comenzar a crear nuestras tablas en memoria. Antes de comenzar, debo explicar que existen 2 tipos de tablas en memoria:
– Durable (DURABILIDAD = SCHEMA_AND_DATA): Los datos y las estructuras persistieron en el disco. Esto significa que si se reinicia el servidor o servicio SQL, los datos de su tabla en memoria seguirán estando disponibles para consultas. Este es el comportamiento predeterminado para las tablas en memoria.
– No duradero (DURABILIDAD = SCHEMA_ONLY): solo la estructura de la tabla se conserva en el disco y no se generan operaciones de registro. Esto significa que escribir operaciones en este tipo de tablas es MUCHO más rápido. Sin embargo, si se reinicia el servidor o servicio SQL, su tabla seguirá estando disponible para consultas, pero estará vacía, ya que los datos solo están disponibles en la memoria y se perdieron durante el bloqueo/reinicio.
Restricciones de OLTP en memoria
Ver contenidoPruebas con tablas OLTP en memoria
Ver contenidoSET STATISTICS TIME OFF
SET NOCOUNT ON
IF (OBJECT_ID('dirceuresende.dbo.Staging_Sem_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Sem_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Sem_JOIN
(
Contador INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH(BUCKET_COUNT = 100000),
Nome VARCHAR(50),
Idade INT,
[Site] VARCHAR(200)
)
WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
IF (OBJECT_ID('dirceuresende.dbo.Staging_Com_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Com_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Com_JOIN
(
Contador INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH(BUCKET_COUNT = 10000000),
[Dt_Venda] DATETIME,
[Vl_Venda] FLOAT(8),
[Nome_Cliente] VARCHAR(100),
[Nome_Produto] VARCHAR(100),
[Ds_Forma_Pagamento] VARCHAR(100)
)
WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
DECLARE
@Contador INT = 1,
@Total INT = 100000,
@Dt_Log DATETIME,
@Qt_Duracao_1 INT,
@Qt_Duracao_2 INT
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste simples
INSERT INTO dirceuresende.dbo.Staging_Sem_JOIN ( Contador, Nome, Idade, [Site] )
VALUES (@Contador, 'Dirceu Resende', 31, 'https://dirceuresende.com/')
SET @Contador += 1
END
SET @Qt_Duracao_1 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SET @Total = 10000
SET @Contador = 1
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste com JOIN
INSERT INTO dirceuresende.dbo.Staging_Com_JOIN
SELECT A.Dt_Venda, A.Vl_Venda, B.Ds_Nome AS Nome_Cliente, C.Ds_Nome AS Nome_Produto, D.Ds_Nome AS Ds_Forma_Pagamento
FROM dirceuresende.dbo.Fato_Venda A
JOIN dirceuresende.dbo.Dim_Cliente B ON A.Cod_Cliente = B.Codigo
JOIN dirceuresende.dbo.Dim_Produto C ON A.Cod_Produto = C.Codigo
JOIN dirceuresende.dbo.Dim_Forma_Pagamento D ON A.Cod_Forma_Pagamento = D.Codigo
SET @Contador += 1
END
SET @Qt_Duracao_2 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SELECT @Qt_Duracao_1 AS Duracao_Sem_JOIN, @Qt_Duracao_2 AS Duracao_Com_JOIN
Tenga en cuenta que especifiqué BUCKET_COUNT de la clave principal HASH del mismo tamaño que la cantidad de registros. Esta información es importante para evaluar la cantidad de memoria necesaria para asignar una tabla, como podemos aprender más en el artículo. desde este enlace aquí. El número ideal es igual al número de registros distintos de la tabla original para procesos de carga temporal (ETL) o de 2 a 5 veces este número para tablas transaccionales.
OLTP en memoria: duradero
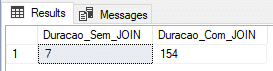
En este ejemplo, crearé las tablas usando el tipo Durable (DURABILITY = SCHEMA_AND_DATA) y veremos si la ganancia de rendimiento en la inserción de datos es tan eficiente como eso.
Resultado:
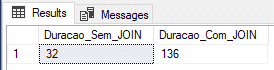
En la captura de pantalla anterior se demostró que el tiempo medido para la inserción sin join no fue muy satisfactorio, quedando muy por detrás de la inserción en tabla @variable y tabla #temporary, mientras que el tiempo con JOINS fue el mejor medido hasta el momento, pero no sorprendió en absoluto.
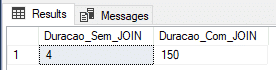
OLTP en memoria: no duradero
En este ejemplo, crearé las tablas usando el tipo No duradero (DURABILITY = SCHEMA_ONLY) y veremos si la ganancia de rendimiento en la inserción de datos es tan eficiente como eso.
Resultado:
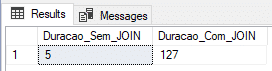
Aquí logramos encontrar un resultado muy interesante, con el tiempo más corto con JOIN y el segundo tiempo más corto sin JOIN.
OLTP en memoria: no duradero (todo en memoria)
Finalmente intentaré reducir el tiempo de carga con joins, creando todas las tablas involucradas para memoria y probando si esto nos dará una buena ganancia de rendimiento.
Guión utilizado:
SET STATISTICS TIME OFF
SET NOCOUNT ON
--------------------------------------------------------
-- Migrando tabelas em disco para In-Memory OLTP
--------------------------------------------------------
SET IDENTITY_INSERT dbo.Dim_Cliente_IMO OFF
GO
SET IDENTITY_INSERT dbo.Dim_Produto_IMO OFF
GO
SET IDENTITY_INSERT dbo.Dim_Forma_Pagamento_IMO OFF
GO
IF (OBJECT_ID('dirceuresende.dbo.Fato_Venda_IMO') IS NOT NULL) DROP TABLE dirceuresende.dbo.Fato_Venda_IMO
CREATE TABLE [dbo].[Fato_Venda_IMO]
(
[Codigo] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED,
[Cod_Cliente] [int] NULL,
[Cod_Produto] [int] NULL,
[Cod_Forma_Pagamento] [int] NULL,
[Dt_Venda] [datetime] NULL,
[Vl_Venda] [float] NULL
) WITH( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
INSERT INTO dbo.Fato_Venda_IMO
SELECT * FROM dbo.Fato_Venda
------------------------------------------------------
IF (OBJECT_ID('dirceuresende.dbo.Dim_Cliente_IMO') IS NOT NULL) DROP TABLE dirceuresende.dbo.Dim_Cliente_IMO
CREATE TABLE [dbo].[Dim_Cliente_IMO]
(
[Codigo] [int] NOT NULL IDENTITY(1, 1) PRIMARY KEY NONCLUSTERED,
[Ds_Nome] [varchar] (100) COLLATE Latin1_General_CI_AI NULL,
[Dt_Nascimento] [datetime] NULL,
[Sg_Sexo] [varchar] (20) COLLATE Latin1_General_CI_AI NULL,
[Sg_UF] [varchar] (2) COLLATE Latin1_General_CI_AI NULL
) WITH( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
SET IDENTITY_INSERT dbo.Dim_Cliente_IMO ON
INSERT INTO dbo.Dim_Cliente_IMO
(
Codigo,
Ds_Nome,
Dt_Nascimento,
Sg_Sexo,
Sg_UF
)
SELECT * FROM dbo.Dim_Cliente
SET IDENTITY_INSERT dbo.Dim_Cliente_IMO OFF
------------------------------------------------------
IF (OBJECT_ID('dirceuresende.dbo.Dim_Produto_IMO') IS NOT NULL) DROP TABLE dirceuresende.dbo.Dim_Produto_IMO
CREATE TABLE [dbo].[Dim_Produto_IMO]
(
[Codigo] [int] NOT NULL IDENTITY(1, 1) PRIMARY KEY NONCLUSTERED,
[Ds_Nome] [varchar] (100) COLLATE Latin1_General_CI_AI NULL,
[Peso] [int] NULL,
[Categoria] [varchar] (50) COLLATE Latin1_General_CI_AI NULL,
[Preco] [float] NULL
) WITH( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
SET IDENTITY_INSERT dbo.Dim_Produto_IMO ON
INSERT INTO dbo.Dim_Produto_IMO
(
Codigo,
Ds_Nome,
Peso,
Categoria,
Preco
)
SELECT * FROM dbo.Dim_Produto
SET IDENTITY_INSERT dbo.Dim_Produto_IMO OFF
------------------------------------------------------
IF (OBJECT_ID('dirceuresende.dbo.Dim_Forma_Pagamento_IMO') IS NOT NULL) DROP TABLE dirceuresende.dbo.Dim_Forma_Pagamento_IMO
CREATE TABLE [dbo].[Dim_Forma_Pagamento_IMO]
(
[Codigo] [int] NOT NULL IDENTITY(1, 1) PRIMARY KEY NONCLUSTERED,
[Ds_Nome] [varchar] (100) COLLATE Latin1_General_CI_AI NULL
) WITH( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
SET IDENTITY_INSERT dbo.Dim_Forma_Pagamento_IMO ON
INSERT INTO dbo.Dim_Forma_Pagamento_IMO
(
Codigo,
Ds_Nome
)
SELECT * FROM dbo.Dim_Forma_Pagamento
SET IDENTITY_INSERT dbo.Dim_Forma_Pagamento_IMO OFF
--------------------------------------------------------
-- Inicitando os testes
--------------------------------------------------------
IF (OBJECT_ID('dirceuresende.dbo.Staging_Sem_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Sem_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Sem_JOIN
(
Contador INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH(BUCKET_COUNT = 100000),
Nome VARCHAR(50),
Idade INT,
[Site] VARCHAR(200)
)
WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
IF (OBJECT_ID('dirceuresende.dbo.Staging_Com_JOIN') IS NOT NULL) DROP TABLE dirceuresende.dbo.Staging_Com_JOIN
CREATE TABLE dirceuresende.dbo.Staging_Com_JOIN
(
Contador INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH(BUCKET_COUNT = 10000000),
[Dt_Venda] DATETIME,
[Vl_Venda] FLOAT(8),
[Nome_Cliente] VARCHAR(100),
[Nome_Produto] VARCHAR(100),
[Ds_Forma_Pagamento] VARCHAR(100)
)
WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY );
GO
DECLARE
@Contador INT = 1,
@Total INT = 100000,
@Dt_Log DATETIME,
@Qt_Duracao_1 INT,
@Qt_Duracao_2 INT
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste simples
INSERT INTO dirceuresende.dbo.Staging_Sem_JOIN ( Contador, Nome, Idade, [Site] )
VALUES (@Contador, 'Dirceu Resende', 31, 'https://dirceuresende.com/')
SET @Contador += 1
END
SET @Qt_Duracao_1 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SET @Total = 10000
SET @Contador = 1
SET @Dt_Log = GETDATE()
WHILE(@Contador <= @Total)
BEGIN
-- Teste com JOIN
INSERT INTO dirceuresende.dbo.Staging_Com_JOIN
SELECT A.Dt_Venda, A.Vl_Venda, B.Ds_Nome AS Nome_Cliente, C.Ds_Nome AS Nome_Produto, D.Ds_Nome AS Ds_Forma_Pagamento
FROM dirceuresende.dbo.Fato_Venda_IMO A
JOIN dirceuresende.dbo.Dim_Cliente_IMO B ON A.Cod_Cliente = B.Codigo
JOIN dirceuresende.dbo.Dim_Produto_IMO C ON A.Cod_Produto = C.Codigo
JOIN dirceuresende.dbo.Dim_Forma_Pagamento_IMO D ON A.Cod_Forma_Pagamento = D.Codigo
SET @Contador += 1
END
SET @Qt_Duracao_2 = DATEDIFF(SECOND, @Dt_Log, GETDATE())
SELECT @Qt_Duracao_1 AS Duracao_Sem_JOIN, @Qt_Duracao_2 AS Duracao_Com_JOIN
Resultado:
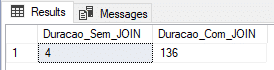
Conclusión
En las pruebas anteriores, quedó claro que, para este escenario, OLTP en memoria termina siendo la mejor solución, tanto para el ejemplo más simple, simplemente insertar datos, como para insertar datos con combinaciones.
Resumen de la prueba:
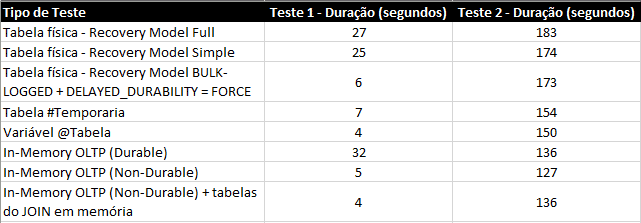
* Prueba 1 = INSERTAR solo / Prueba 2 = INSERTAR con JOINS
Si comparamos los resultados con las tablas físicas, el resultado es muy expresivo y un gran incentivo para su uso en escenarios de BI, especialmente porque, en los ejemplos presentados, las tablas tenían solo 100k registros en una VM con 4 núcleos y 8GB de RAM.
La tendencia es que cuanto mejor sea el hardware y mayor el volumen de datos, mayor será la diferencia de rendimiento entre las tablas físicas y las tablas en memoria. Sin embargo, el resultado no fue tan expresivo en comparación con la variable de tipo tabla, lo que incluso tiene sentido, ya que ambas se almacenan completamente en la memoria.
Está claro que una tabla en memoria tiene varias ventajas sobre la variable de tipo tabla, especialmente la vida útil, ya que la variable de tipo tabla solo está disponible durante la ejecución por lotes y la tabla en memoria está disponible mientras el servicio SQL Server permanezca activo.
Como los resultados de la prueba no me convencieron, decidí aumentar el volumen de datos. En lugar de 100.000, ¿qué tal si insertamos lotes de 20 registros, sumando un total de 1 millón de registros insertados por prueba y repitiendo 2 veces más para cada forma de evaluación?
Veamos los resultados:
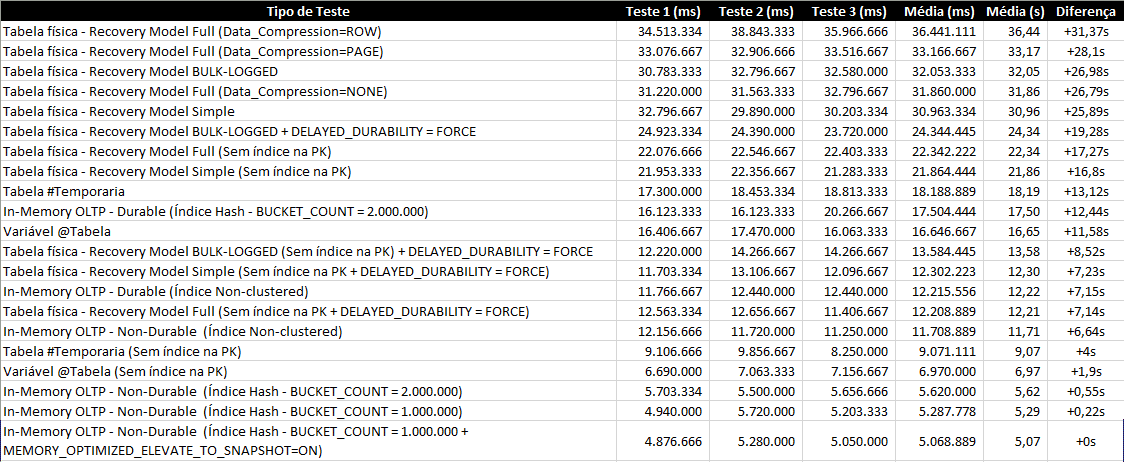
En este artículo, solo demostré su potencial para escritura, pero In-Memory OLTP también tiene muy buen rendimiento para lectura, especialmente si se accede mucho a la tabla.
Espero que te haya gustado esta publicación. Si no estaba familiarizado con OLTP en memoria, espero haber demostrado parte del potencial de esta excelente característica de SQL Server.
Un abrazo y ¡hasta la próxima!

Comentários (0)
Carregando comentários…