Fala galera!!!
Neste artigo, eu gostaria de compartilhar com vocês algo que vejo bastante no dia a dia quando estou realizando consultoria de Tuning, que são consultas demoradas, com alto consumo de I/O e CPU, e que utilizam funções no WHERE ou JOIN em tabelas com muitos registros e como podemos utilizar uma técnica bem simples de indexação de coluna calculada (ou computada) para resolver esse problema.
Conforme eu comento no artigo Entendendo o funcionamento dos índices no SQL Server, ao utilizar funções em cláusulas WHERE ou JOINS, nós estamos ferindo o conceito de SARGability da consulta, ou seja, estamos fazendo com que essa consulta passe a não utilizar operações de Seek nos índices, uma vez que o SQL Server precisa ler toda a tabela, aplicar a função desejada para depois, comparar os valores e retornar os resultados.
O que eu quero nesse artigo, é demonstrar a vocês esse cenário acontecendo, como identificar isso e algumas possíveis soluções para melhorar a performance das consultas. Então, vamos lá!
Criando a base de demonstração desse artigo
Para criar essa tabela de exemplo parecida com a minha (os dados são aleatórios, né.. rs), para conseguir acompanhar o artigo e simular esses cenários, você pode utilizar o script abaixo:
IF (OBJECT_ID('_Clientes') IS NOT NULL) DROP TABLE _Clientes
CREATE TABLE _Clientes (
Id_Cliente INT IDENTITY(1,1),
Dados_Serializados VARCHAR(MAX)
)
INSERT INTO _Clientes ( Dados_Serializados )
SELECT
CONVERT(VARCHAR(19), DATEADD(SECOND, (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 199999999, '2015-01-01'), 121) + '|' +
CONVERT(VARCHAR(20), CONVERT(INT, (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 9)) + '|' +
CONVERT(VARCHAR(20), CONVERT(INT, (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 10)) + '|' +
CONVERT(VARCHAR(20), CONVERT(INT, 0.459485495 * (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0)) * 1999)
GO 10000
INSERT INTO _Clientes ( Dados_Serializados )
SELECT Dados_Serializados
FROM _Clientes
GO 9
CREATE CLUSTERED INDEX SK01_Pedidos ON _Clientes(Id_Cliente)
CREATE NONCLUSTERED INDEX SK02_Pedidos ON _Clientes(Dados_Serializados)
GO
Demonstração utilizando função nativa
Para demonstrar como uma consulta pode ficar lenta simplesmente pelo fato de utilizar função no WHERE ou JOIN, vou utilizar a query abaixo inicialmente:
SELECT *
FROM _Clientes
WHERE Dados_Serializados = '2016-11-22 04:49:06|2|0|0'
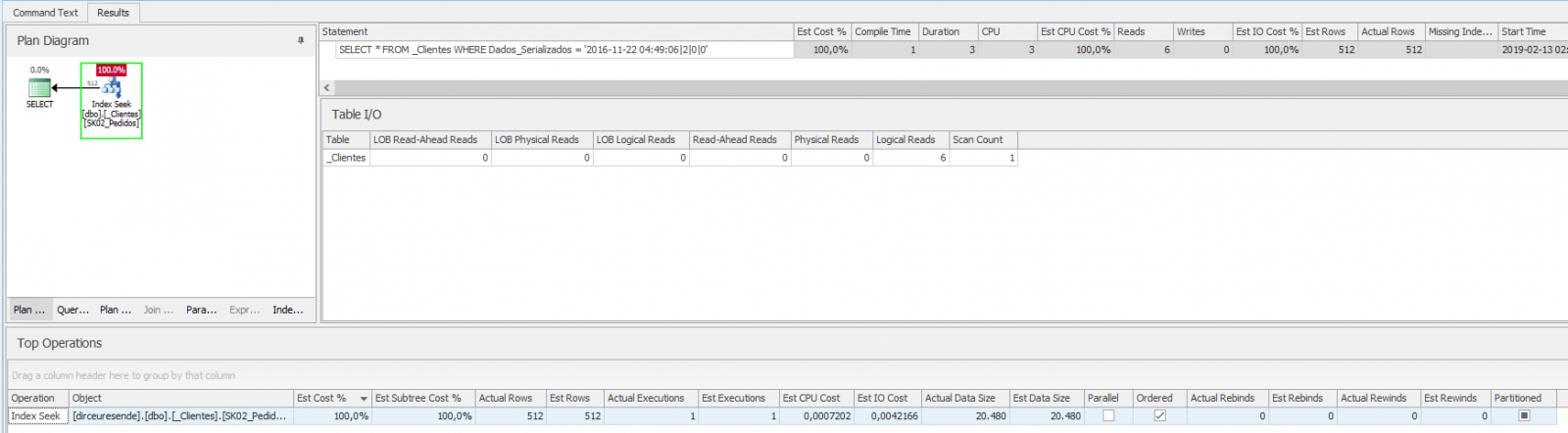
Se analisarmos o plano de execução dessa consulta, vemos que ela está utilizando o operador Index Seek, fazendo apenas 6 leituras e 512 registros. Analisando as informações de CPU e IO, podemos concluir que 3ms de CPU (compile) e 3ms de tempo de execução estão bem aceitáveis:
Agora vamos utilizar uma função nessa mesma consulta:
SELECT *
FROM _Clientes
WHERE SUBSTRING(Dados_Serializados, 1, 10) = '2016-11-22'
Análise da execução:
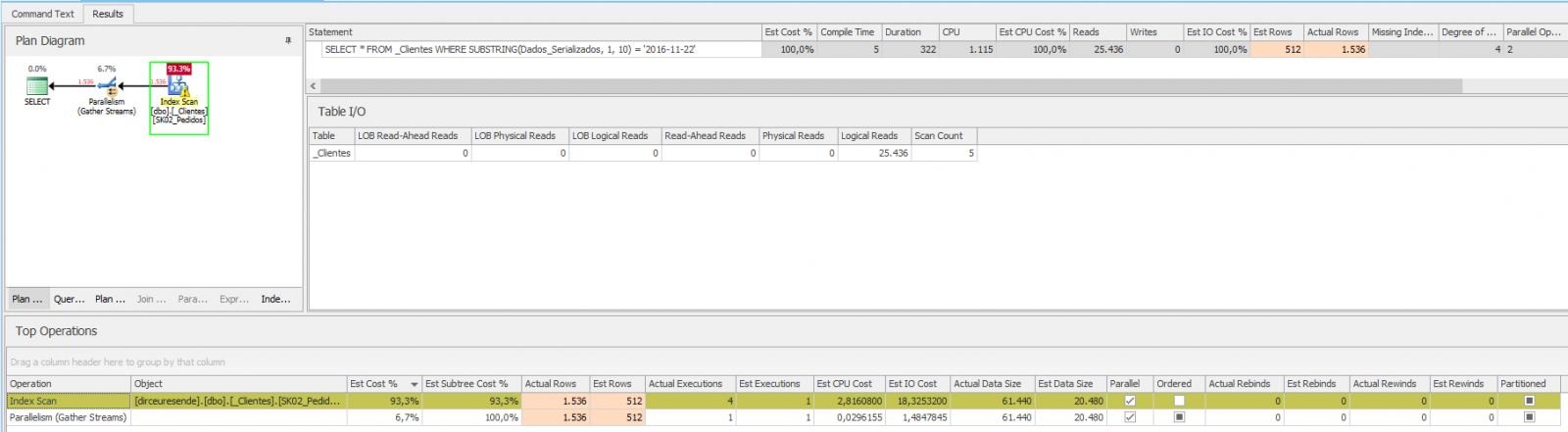
Ou seja, o resultado ficou péssimo.. Index Scan, tempo de cpu alto, tempo de execução alto, muitas leituras lógicas. Tudo isso por causa da função utilizada, que deixou de utilizar o operador Index Seek e passou a fazer Index Scan.
Para resolver isso, é bem simples, especialmente porque essa função do jeito que está montada (igual a um LEFT), está nos ajudando, pois nesses casos, nós podemos substituir a função pelo LIKE ‘texto%’ tranquilamente, pois o SQL Server irá utilizar a operação de Seek no índice:
SELECT *
FROM _Clientes
WHERE Dados_Serializados LIKE '2016-11-22%'Análise da execução:

Podemos notar que ao utilizar o LIKE ‘texto%’, o índice foi utilizado com a operação Seek, fazendo com que a nossa consulta volte a ser performática.
LIKE e o SARGability
IMPORTANTE: Ao contrário do LIKE ‘texto%’, se você adicionar o símbolo de ‘%’ antes do texto, para filtrar tudo que contenha ou termine com uma determinada expressão, o índice não será utilizado com o operador Seek, e sim o Scan.
Para entender o motivo disso, faça uma analogia com um índice de um dicionário: Para achar todas as palavras do dicionário que começam com ‘test’ é muito simples, basta ir na letra T, depois na letra ‘e’, depois na letra ‘s’ e por aí vai até encontrar as palavras desejadas.. Quando a próxima palavra da lista for maior que ‘test’, podemos encerrar a busca.
Já para identificar todas as palavras do dicionário que contenham a palavra ‘test’ ou terminem com ‘test’, teremos que olhar todas as palavras do dicionário para conseguir identificá-las.
Facilitou o entendimento de como os índices funcionam? Se ainda tiver dúvidas, leia o meu artigo Entendendo o funcionamento dos índices no SQL Server.
Mas e se fosse a função RIGHT, por exemplo? Será que a nossa consulta não vai utilizar a operação de Seek no índice mesmo?
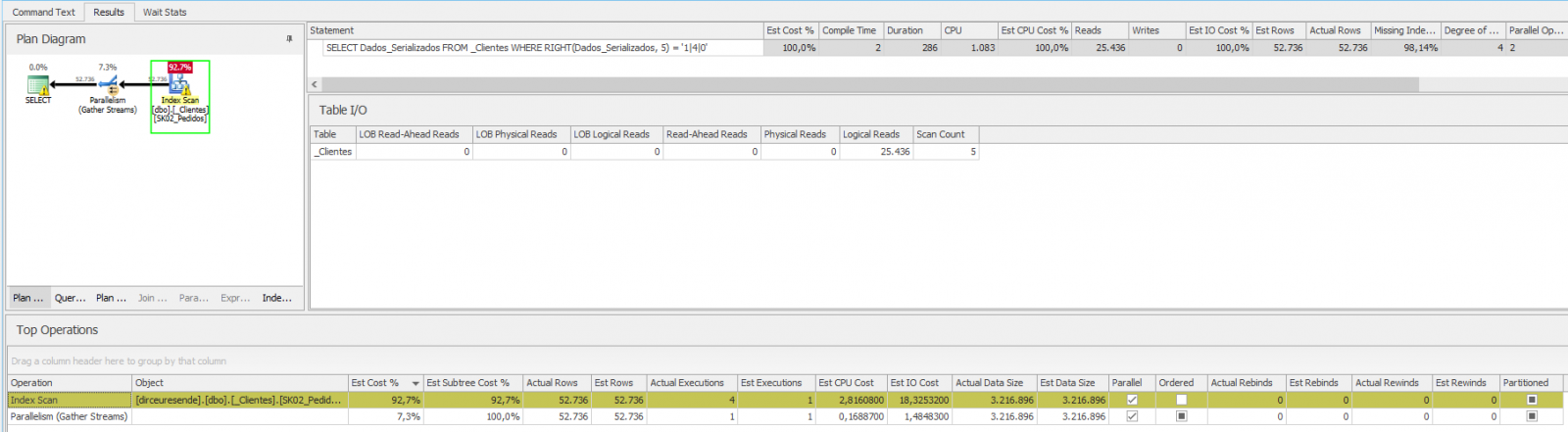
Como vimos acima, a consulta ficou bem ruim, com alto número de logical reads, tempo de execução e de CPU. Para resolver esse problema, vamos utilizar o recurso de coluna calculada e indexando essa coluna calculada:
-- Cria a nova coluna calculada
ALTER TABLE _Clientes ADD Right_5 AS (RIGHT(Dados_Serializados, 5))
GO
-- Cria um índice para a nova coluna criada
CREATE NONCLUSTERED INDEX SK03_Clientes ON dbo._Clientes(Right_5)
GO
-- Executa a consulta nova
SELECT Right_5
FROM _Clientes
WHERE Right_5 = '1|4|0'
Análise da execução:
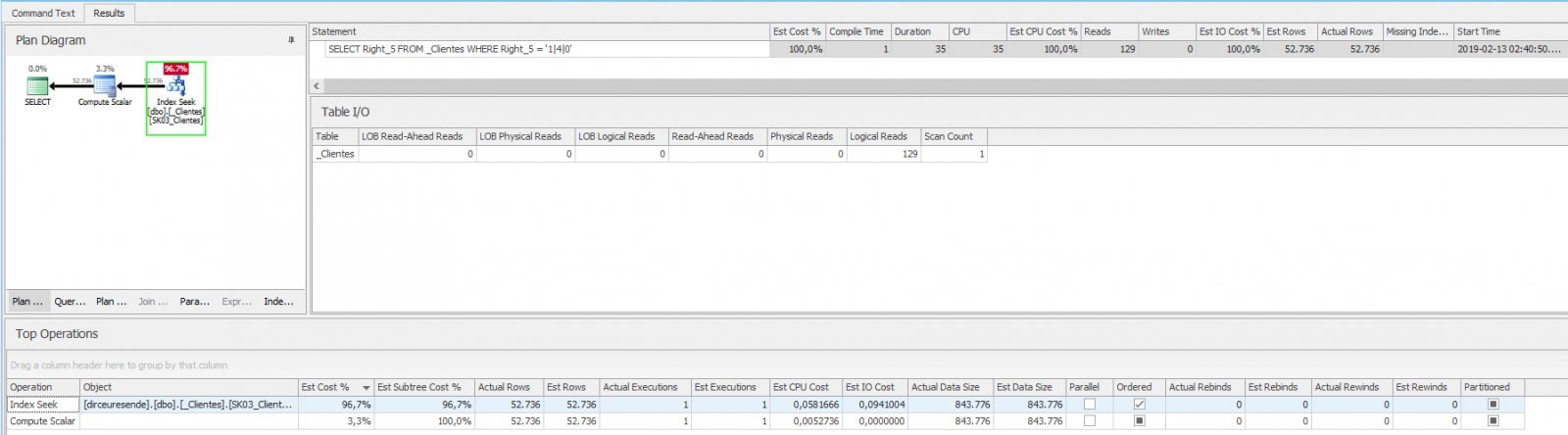
Wow! A consulta ficou bem mais rápida agora! Isso acontece porque na criação do índice, ele já calculou esses dados para a coluna toda e os deixou ordenados. Com isso, as consultas ficam muito mais rápidas que ter que calcular isso em tempo real para depois comparar os valores.
Considerações sobre criação de índices e determinismo de funções de sistema
Observação 1: Fique atento ao fato que a criação do índice vai consumir espaço em disco e incluir uma coluna em uma tabela, mesmo que calculada, deve ser testada antes para garantir que isso não vá gerar nenhum erro durante uma operação de insert que não esteja especificando os campos, por exemplo.
Observação 2: Um ponto muito importante a se destacar, é que criar colunas calculadas persistidas em disco e indexar colunas calculadas só é possível ao se utilizar função determinísticas.
Todas as funções que existem no SQL Server são determinísticas ou não determinísticas. O determinismo de uma função é definido pelos dados retornados pela função. O seguinte descreve o determinismo de uma função:
- Uma função é considerada determinística se sempre retorna o mesmo conjunto de resultados quando é chamado com o mesmo conjunto de valores de entrada.
- Uma função é considerada não determinística se não retornar o mesmo conjunto de resultados quando for chamada com o mesmo conjunto de valores de entrada.
Isso pode soar um pouco complicado, mas na verdade não é. Veja, por exemplo, as funções DATEDIFF e GETDATE. DATEDIFF é determinístico porque sempre retornará os mesmos dados sempre que for executado com os mesmos parâmetros de entrada. O GETDATE não é determinístico porque nunca retornará a mesma data toda vez que for executado.
Demonstração utilizando função definida pelo usuário (UDF)
Se utilizando função nativa no WHERE/JOIN já piora a performance das nossas consultas, utilizando função personalizada do usuário o cenário é ainda pior. Para esse post, vou utilizar a função fncSplit (com schema binding):
SELECT Dados_Serializados
FROM _Clientes
WHERE dbo.fncSplit(Dados_Serializados, '|', 3) = '1'Análise da execução:

Como você pode observar, essa consulta simples, numa tabela de 10.000 registros, demorou cerca de 35 segundos para ser executada, consumindo quase 15s de CPU. Foram feitas cerca de 240 mil leituras lógicas, sendo processadas 610 mil linhas para retornar as 1.040 linhas do resultado final. Resumo: Tá muito ruim!
Para tentar melhorar a performance dessa consulta, vamos utilizar a mesma solução do exemplo anterior, criando uma coluna calculada e indexando essa coluna:
-- Cria a nova coluna calculada
ALTER TABLE _Clientes ADD Coluna_Teste AS (dbo.fncSplit(Dados_Serializados, '|', 3))
GO
-- Cria um índice para a nova coluna criada
CREATE NONCLUSTERED INDEX SK04_Clientes ON dbo._Clientes(Coluna_Teste) INCLUDE(Dados_Serializados)
GO
-- Executa a consulta nova
SELECT Dados_Serializados
FROM _Clientes
WHERE Coluna_Teste = '1'
Antes de analisar a execução deste teste, preciso fazer um alerta sobre a criação de coluna calculada persistida em disco utilizando função definida pelo usuário (UDF) e criação de índices nessas colunas calculadas:
Determinismo de função definida pelo usuário (UDF)
Importante: Quando você cria uma função definida pelo usuário (UDF), o SQL Server registra o determinismo. O determinismo de uma função definida pelo usuário é determinado em como você cria a função. Uma função definida pelo usuário é considerada determinística se todos os critérios a seguir forem atendidos:
- A função é vinculada ao esquema (schema-bound) para todos os objetos de banco de dados aos quais faz referência.
- Qualquer função chamada pela função definida pelo usuário é determinística. Isso inclui todas as funções definidas pelo usuário e do sistema.
- A função não faz referência a nenhum objeto de banco de dados que esteja fora de seu escopo. Isso significa que a função não pode referenciar tabelas externas, variáveis ou cursores.
Quando você cria uma função, o SQL Server aplica todos esses critérios para a função para determinar seu determinismo. Se uma função não passar em nenhuma dessas verificações, a função será marcada como não determinística. Às vezes, essas verificações podem produzir funções marcadas como não determinísticas, mesmo quando você espera que elas sejam marcadas como determinísticas.
No caso deste exemplo, caso eu não inclua o parâmetro WITH SCHEMABINDING na declaração da fncSplit, iremos nos deparar com a seguinte mensagem de erro:
Column ‘Coluna_Teste’ in table ‘dbo._Clientes’ cannot be used in an index or statistics or as a partition key because it is non-deterministic.
Análise da execução:
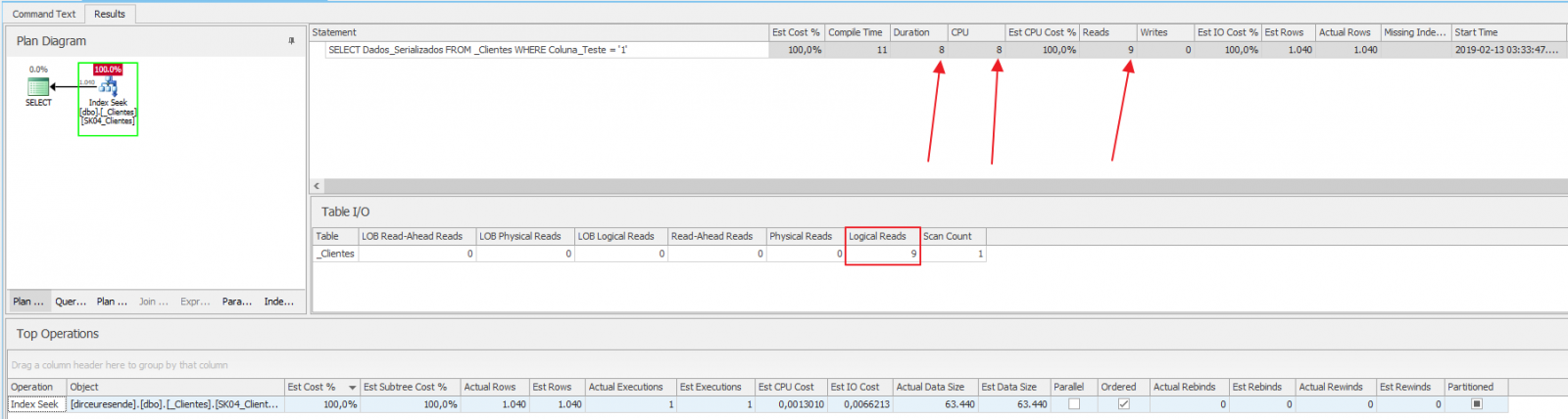
Wow!! De 32 segundos nossa consulta caiu para 8ms!! A quantidade de CPU caiu de 14.974 para 8 e a quantidade logical reads caiu de 240.061 para 9! Esse tuning aí foi realmente bem efetivo. Aposto que se você fizer algo parecido em um cliente, você receberá belos elogios 🙂
Antes de finalizar este artigo, gostaria de deixar um último recado para vocês:
Como sempre falo: Ao aplicar técnicas de performance tuning, SEMPRE TESTE!
Bom pessoal, espero que vocês tenham gostado desse artigo.
Um grande abraço e até mais!

Comentários (0)
Carregando comentários...