
¿Qué pasa, chicos?
En esta publicación les traigo una solución simple, pero que realmente me gustó, porque me ayudó a reducir significativamente el tiempo de procesamiento de una canalización de Azure Data Factory (ADF) al cambiar el objetivo del servicio y cambiar el tamaño de una base de datos SQL de Azure usando comandos T-SQL antes de que comenzara el procesamiento y regresar al nivel original al final de todo el procesamiento.
Para cambiar el nivel de Azure SQL Database, puedes usar la interfaz de Azure Portal, Powershell, Azure CLI, Azure DevOps y una serie de alternativas más, además de nuestro querido Transact-SQL (T-SQL), que, en mi opinión, es la opción más fácil y práctica de todas.
Mira lo fácil que es:
ALTER DATABASE [dirceuresende]
MODIFY(SERVICE_OBJECTIVE = 'S3')
El problema con todas estas soluciones, especialmente en el escenario del que hablo, es que el cambio del Objetivo del Servicio, también conocido como Nivel de Servicio, no se realiza de inmediato, es decir, ejecutas el comando y Azure SQL cambiará el nivel en el momento que Azure considere oportuno. Puede tardar 1 segundo, 10 segundos, 60 segundos, etc... Y cuando cambia el nivel de Azure SQL Database, las sesiones se desconectan.
En el escenario que mencioné anteriormente, donde cambio el nivel antes de comenzar el procesamiento de datos, si simplemente ejecuto el comando T-SQL y continúo procesando, en el medio Azure cambiará el nivel, la conexión se interrumpirá durante unos segundos y la base de datos no estará disponible durante unos segundos.
También puedes usar Retry en todos los componentes de tu pipeline y así evitar que esto sea un problema para ti, porque cuando se caiga la conexión se activará el reintento y se realizarán operaciones nuevamente, pero tendrías que configurar el reintento en todos los componentes en lugar de configurarlo solo en el componente de upsizing, es posible que te hayan cobrado por movimiento de datos y uso de recursos ADF durante este tiempo que procesaste para nada. Además, pueden producirse efectos secundarios si un componente no está preparado para interrumpirse a mitad de ejecución y ejecutarse nuevamente.
Otra posible solución es colocar un operador de espera en Azure Data Factory y especificar cualquier momento que crea que es suficiente para que Azure cambie el nivel. Según mis pruebas, el tiempo necesario para que Azure SQL Database cambie el nivel suele ser de entre 50 y 90 segundos.
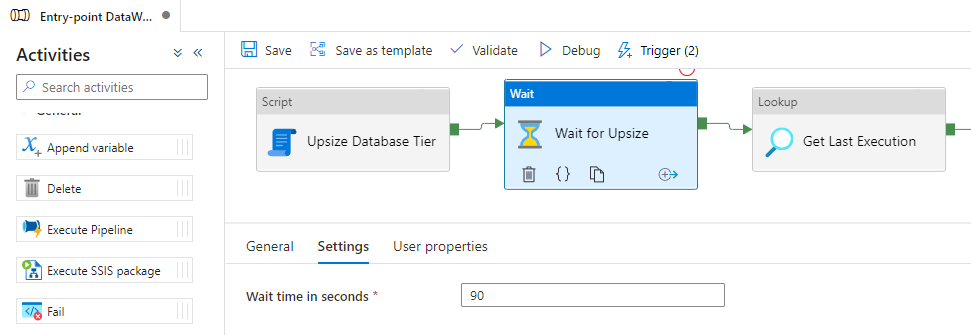
Si bien esto puede funcionar en algunos casos (y no en otros), esta solución no me parece muy confiable. Si el tiempo para cambiar el nivel excede el límite que definí, habré esperado mucho tiempo y todavía fallará en medio del procesamiento. Y si el cambio termina antes habré esperado mucho tiempo innecesariamente.
Busqué algunas soluciones para resolver mi problema y terminé enamorándome de la idea del MVP de Data Platform, Greg Low. en esta publicación aquí, pero elegí crear mi procedimiento con el objetivo de tener una solución más sencilla para intentar solucionar este problema.
Código fuente del procedimiento almacenado
CREATE PROCEDURE dbo.stpAltera_Tier_DB (
@ServiceLevelObjective VARCHAR(50),
@TimeoutEmSegundos INT = 60
)
AS
BEGIN
SET NOCOUNT ON
DECLARE
@Query NVARCHAR(MAX),
@DataHoraLimite DATETIME2 = DATEADD(SECOND, @TimeoutEmSegundos, GETDATE()),
@ServiceLevelObjectiveAtual VARCHAR(20) = CONVERT(VARCHAR(100), DATABASEPROPERTYEX( DB_NAME(), 'ServiceObjective' ))
IF (@ServiceLevelObjectiveAtual <> @ServiceLevelObjective)
BEGIN
SET @Query = N'ALTER DATABASE [' + DB_NAME() + '] MODIFY (SERVICE_OBJECTIVE = ''' + @ServiceLevelObjective + ''');'
EXEC sp_executesql @Query;
WHILE ((DATABASEPROPERTYEX( DB_NAME(), 'ServiceObjective' ) <> @ServiceLevelObjective) AND GETDATE() <= @DataHoraLimite)
BEGIN
WAITFOR DELAY '00:00:00.500';
END
END
ENDUtilizar este procedimiento es muy sencillo:
EXEC dbo.stpAltera_Tier_DB
@ServiceLevelObjective = 'S3',
@TimeoutEmSegundos = 60
Luego de ejecutar el comando, el procedimiento esperará hasta que Azure realice el cambio, reevaluando cada 500 milisegundos si el cambio ya se realizó, respetando el límite de tiempo definido. Si se alcanza el límite, el procedimiento finalizará su ejecución incluso si el cambio aún no ha surtido efecto. Si el cambio entra en vigor antes del límite de tiempo, el procedimiento finalizará su ejecución tan pronto como se cambie el nivel, evitando pérdidas de tiempo.
Para ejecutar este procedimiento a través de Azure Data Factory, utilizaremos el “nuevo” componente Script, disponible el 6 de marzo de 2022:
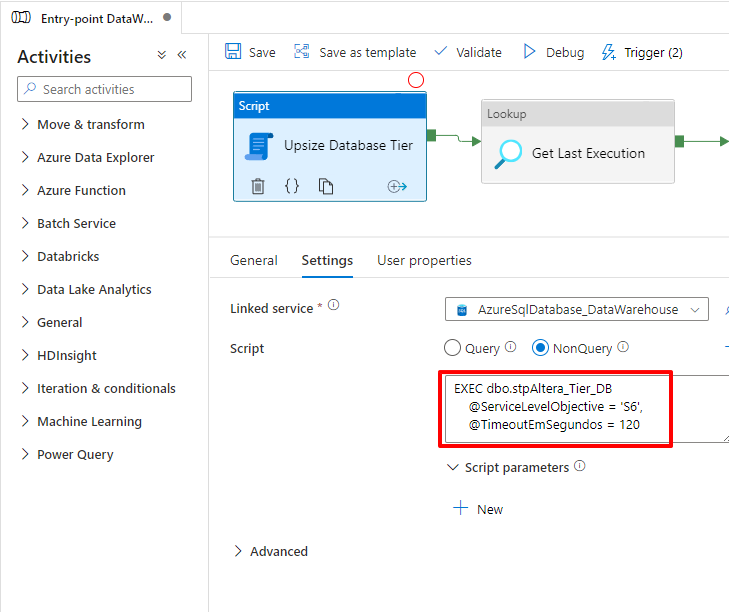
Como Azure SQL Database elimina todas las conexiones y la base de datos no está disponible durante unos segundos, incluso con este tratamiento, el procedimiento devolverá un error porque su sesión en sí fue eliminada:
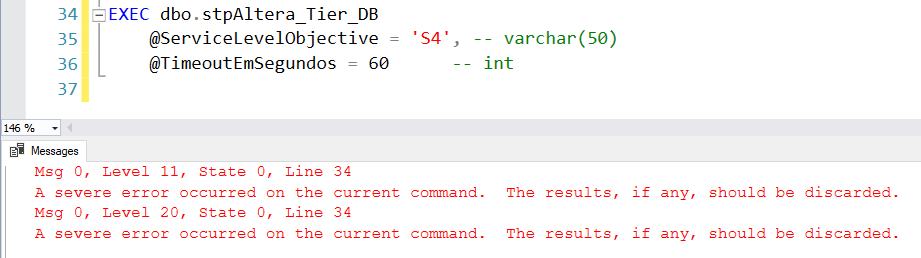
En Azure Data Factory también habrá un error al ejecutar este procedimiento cuando se realice el intercambio:
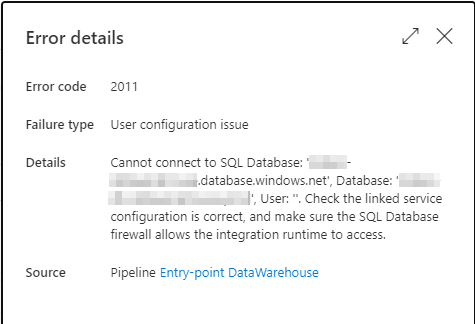
Para que esta solución funcione definiremos un Reintento para este bloque de Script, de modo que cuando falle (y fallará), entre al Reintento, espere otros 10 segundos y ejecute nuevamente el Procedimiento.
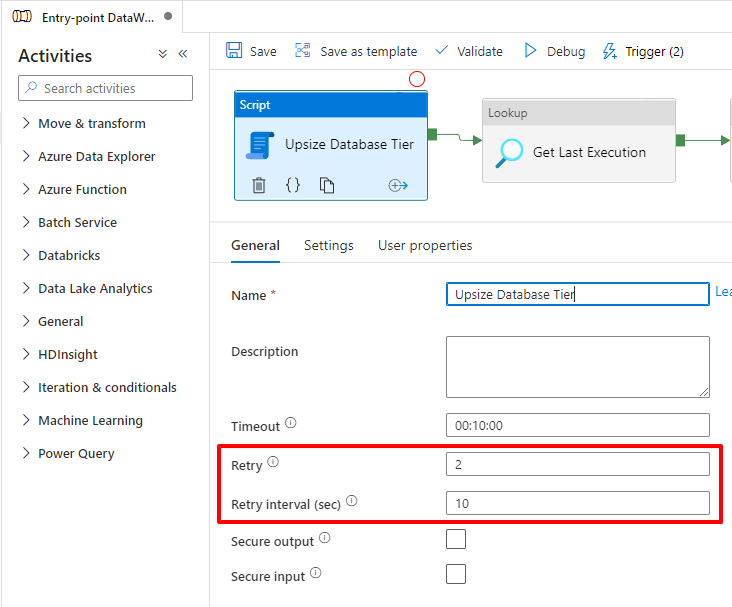
En la segunda ejecución del procedimiento almacenado, como el cambio se realizará en el mismo nivel que la ejecución anterior, el comando se ejecutará instantáneamente y Azure simplemente ignorará el comando y devolverá la ejecución exitosa, como se muestra a continuación:

Y con eso, su banco ahora tiene el nuevo nivel y puede comenzar a procesar los datos. Al final del procesamiento, reduzco la escala para devolver el nivel al valor original, pero esta vez, no necesito esperar a que finalice el cambio, ya que no procesaré nada más.
Por lo tanto, puedo utilizar la forma más básica para volver al nivel anterior:
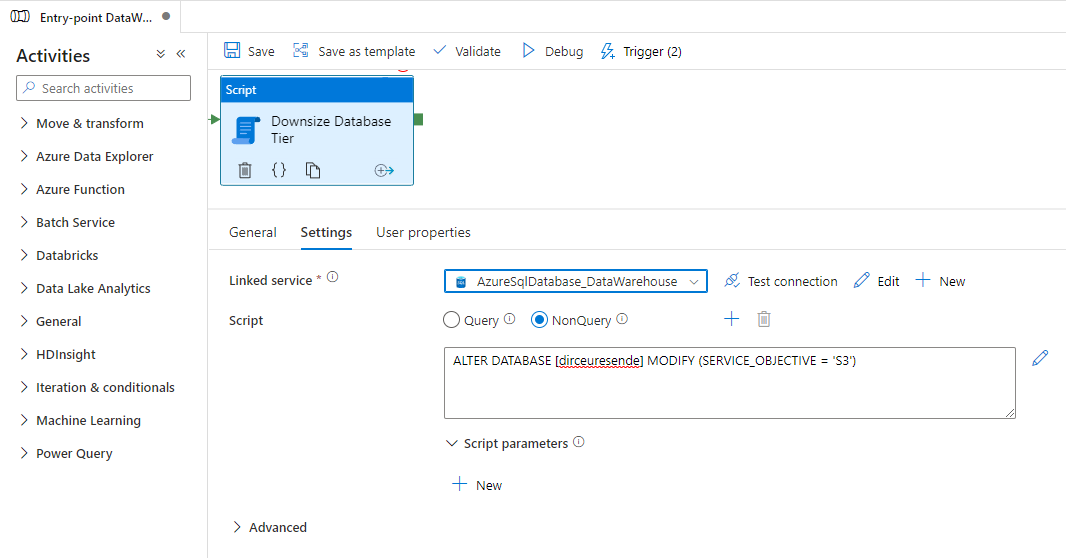
Para ser muy honesto contigo, pensando primero en la simplicidad, al final ni siquiera el Procedimiento Almacenado es necesario. Como la conexión siempre se interrumpe, puedo simplemente colocar un IF simple con un RETARDO DE ESPERA muy largo dentro del bloque Script y tener el mismo comportamiento:
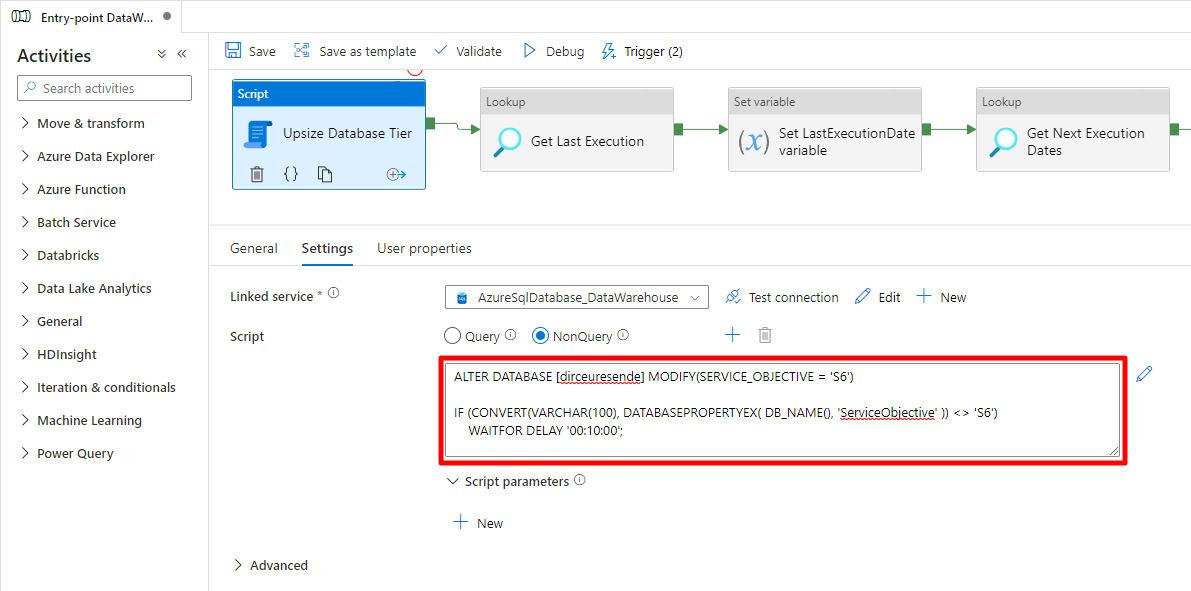
ALTER DATABASE [dirceuresende] MODIFY(SERVICE_OBJECTIVE = 'S6')
IF (CONVERT(VARCHAR(100), DATABASEPROPERTYEX( DB_NAME(), 'ServiceObjective' )) <> 'S6')
WAITFOR DELAY '00:10:00';
Bloque de guión:
Resultado de la ejecución:
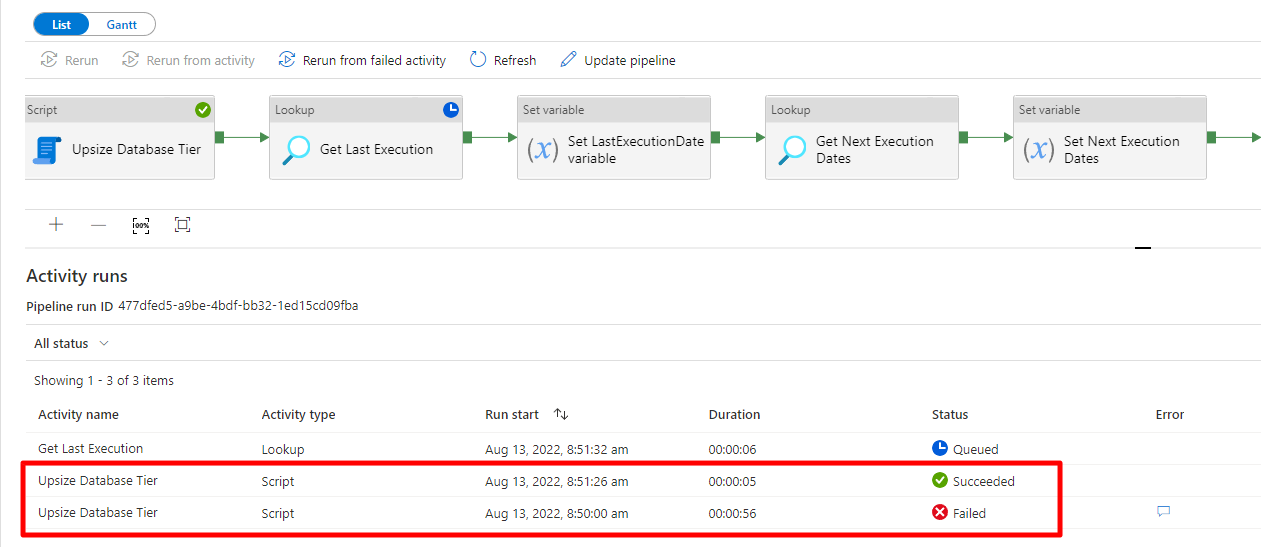
Y al igual que al usar el Procedimiento Almacenado, la rutina dio un error en la primera ejecución, esperando hasta que el cambio de nivel se hiciera efectivo en el banco. Cuando esto ocurre, la conexión se interrumpe y la ejecución devuelve un error.
Azure Data Factory espera 10 segundos (el tiempo que configuré) después del error y vuelve a intentarlo. Esta vez la ejecución es muy rápida, ya que el nivel ya ha sido cambiado al nivel elegido. Esta segunda ejecución es exitosa y el ciclo de la canalización continúa normalmente.
El comportamiento terminó siendo el mismo que el Procedimiento, pero mucho más simple. Puse una espera muy larga (10 minutos), que acabará siendo el tiempo límite que tendrá Azure para realizar el cambio, que es mucho más que suficiente. Al finalizar antes el cambio, el ciclo continúa sin tener que esperar esos 10 minutos.
Resultó que la solución era incluso más sencilla de lo que pensaba. Ahora puede aumentar el nivel de su Azure SQL Database antes de iniciar el procesamiento ETL usando Azure Data Factory, para que el procesamiento sea más rápido y, al final del procesamiento, regrese al nivel original, pagando más solo durante el tiempo que estuvo procesando datos. Una forma inteligente de tener un rendimiento mucho mejor pagando mucho menos 🙂
Espero que te haya gustado este consejo y hasta la próxima.

Comentarios (0)
Cargando comentarios...