Hola, chicos,
¡Buen día!
En este post hablaré de un tema que no es nada nuevo en SQL Server, está presente desde SQL Server 2008, pero no veo mucha gente usándolo en sus consultas, que es la agrupación de datos (resumenización) usando ROLLUP, CUBE y GROUPING SETS.
Este tipo de recurso es especialmente útil para generar totales y subtotales sin tener que crear múltiples subconsultas, ya que permite realizar esta tarea en un solo comando, como lo demostraré a continuación.
Para crear una función de Autosuma en su conjunto de datos, tal como la implementa Excel, vea más en la publicación SQL Server: cómo crear una autosuma (igual que Excel) usando funciones de ventana
Base de prueba
Para los ejemplos de esta publicación, proporcionaré la base a continuación para que podamos crear un entorno de prueba y demostración.
IF (OBJECT_ID('tempdb..#Produtos') IS NOT NULL) DROP TABLE #Produtos
CREATE TABLE #Produtos (
Codigo INT IDENTITY(1, 1) NOT NULL PRIMARY KEY,
Ds_Produto VARCHAR(50) NOT NULL,
Ds_Categoria VARCHAR(50) NOT NULL,
Preco NUMERIC(18, 2) NOT NULL
)
IF (OBJECT_ID('tempdb..#Vendas') IS NOT NULL) DROP TABLE #Vendas
CREATE TABLE #Vendas (
Codigo INT IDENTITY(1, 1) NOT NULL PRIMARY KEY,
Dt_Venda DATETIME NOT NULL,
Cd_Produto INT NOT NULL
)
INSERT INTO #Produtos ( Ds_Produto, Ds_Categoria, Preco )
VALUES
( 'Processador i7', 'Informática', 1500.00 ),
( 'Processador i5', 'Informática', 1000.00 ),
( 'Processador i3', 'Informática', 500.00 ),
( 'Placa de Vídeo Nvidia', 'Informática', 2000.00 ),
( 'Placa de Vídeo Radeon', 'Informática', 1500.00 ),
( 'Celular Apple', 'Celulares', 10000.00 ),
( 'Celular Samsung', 'Celulares', 2500.00 ),
( 'Celular Sony', 'Celulares', 4200.00 ),
( 'Celular LG', 'Celulares', 1000.00 ),
( 'Cama', 'Utilidades do Lar', 2000.00 ),
( 'Toalha', 'Utilidades do Lar', 40.00 ),
( 'Lençol', 'Utilidades do Lar', 60.00 ),
( 'Cadeira', 'Utilidades do Lar', 200.00 ),
( 'Mesa', 'Utilidades do Lar', 1000.00 ),
( 'Talheres', 'Utilidades do Lar', 50.00 )
DECLARE @Contador INT = 1, @Total INT = 100
WHILE(@Contador <= @Total)
BEGIN
INSERT INTO #Vendas ( Cd_Produto, Dt_Venda )
SELECT
(SELECT TOP 1 Codigo FROM #Produtos ORDER BY NEWID()) AS Cd_Produto,
DATEADD(DAY, (CAST(RAND() * 364 AS INT)), '2017-01-01') AS Dt_Venda
SET @Contador += 1
END
En una simple agrupación de datos, simplemente filtrando las cantidades por categoría y producto, pudimos devolver esta vista utilizando la siguiente consulta:
SELECT
B.Ds_Categoria,
B.Ds_Produto,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
GROUP BY
B.Ds_Categoria,
B.Ds_Produto
ORDER BY
1, 2
Resumiendo los valores
¿Pero qué pasa si necesitas agrupar los datos creando un totalizador para cada categoría y al final un totalizador general? ¿Cómo lo harías?
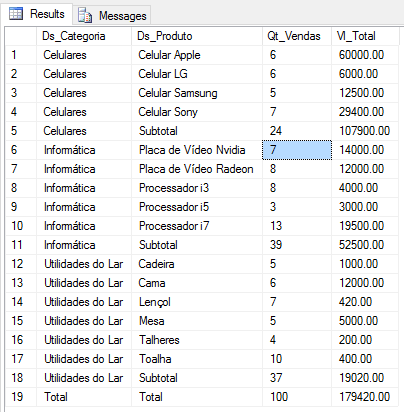
Usando UNION TODO
Una forma tradicional de satisfacer esta necesidad es utilizar subconsultas con UNION ALL, de modo que se devuelvan 3 conjuntos de resultados que contengan los datos analíticos, los totalizadores por categoría y luego la suma general. Cuanto mayor sea el número de filtros, más compleja será su subconsulta, ya que necesitará más consultas en cada nivel.
SELECT
*
FROM (
SELECT
B.Ds_Categoria,
B.Ds_Produto,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
GROUP BY
B.Ds_Categoria,
B.Ds_Produto
UNION ALL
SELECT
B.Ds_Categoria,
'Subtotal' AS Ds_Produto,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
GROUP BY
B.Ds_Categoria
UNION ALL
SELECT
'Total' AS Ds_Categoria,
'Total' AS Ds_Produto,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
) A
ORDER BY
(CASE WHEN A.Ds_Categoria = 'Total' THEN 1 ELSE 0 END),
A.Ds_Categoria,
(CASE WHEN A.Ds_Produto = 'Subtotal' THEN 1 ELSE 0 END),
A.Ds_Produto
Usando GRUPO POR ROLLUP
Una forma muy sencilla y práctica de solucionar este problema es utilizando la función ROLLUP() en GROUP BY, que ya crea agrupaciones y resúmenes según las columnas agrupadas en la función.
Al usar esta función, verá que crea los totalizadores justo debajo de cada grupo y el totalizador general en la última línea del conjunto de resultados.
Ejemplo 1:
SELECT
B.Ds_Categoria,
B.Ds_Produto,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
GROUP BY
ROLLUP(B.Ds_Categoria, B.Ds_Produto)
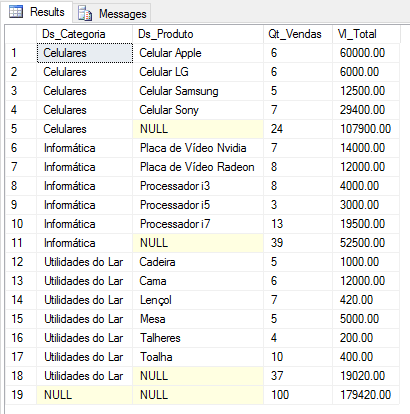
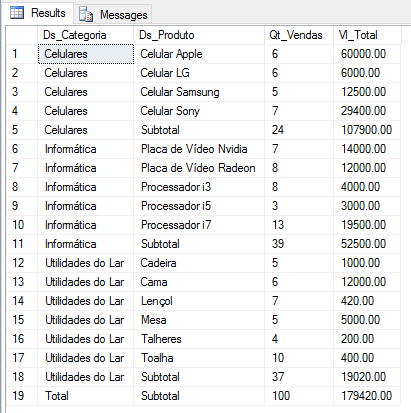
Como habrás notado, las líneas que contienen los resúmenes tienen un valor NULL en las columnas agrupadas. En este ejemplo, el subtotal por categoría tiene la columna Ds_Produto con valor NULL y en el total general, ambas columnas tienen valor NULL. Para que nuestra consulta produzca el mismo resultado que otra consulta con UNION ALL, simplemente necesitamos tratar estos valores NULL, como se muestra a continuación:
SELECT
ISNULL(B.Ds_Categoria, 'Total') AS Ds_Categoria,
ISNULL(B.Ds_Produto, 'Subtotal') AS Ds_Produto,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
GROUP BY
ROLLUP(B.Ds_Categoria, B.Ds_Produto)
Ejemplo 2:
SELECT
ISNULL(CONVERT(VARCHAR(10), MONTH(A.Dt_Venda)), 'Total') AS Mes_Venda,
ISNULL(B.Ds_Categoria, 'Subtotal') AS Ds_Categoria,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
GROUP BY
ROLLUP(MONTH(A.Dt_Venda), B.Ds_Categoria)

Usando GRUPO POR CUBO
Al igual que la función ROLLUP(), la función CUBE() permite crear totalizadores agrupados de una forma muy práctica y sencilla y su sintaxis es la misma que la función ROLLUP.
Usando esta función, verás que la diferencia entre esta y ROLLUP es que la función CUBE crea totalizadores para cada tipo de agrupación.
Ejemplo:
SELECT
ISNULL(CONVERT(VARCHAR(10), MONTH(A.Dt_Venda)), 'Total') AS Mes_Venda,
ISNULL(B.Ds_Categoria, 'Subtotal') AS Ds_Categoria,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
GROUP BY
CUBE(MONTH(A.Dt_Venda), B.Ds_Categoria)
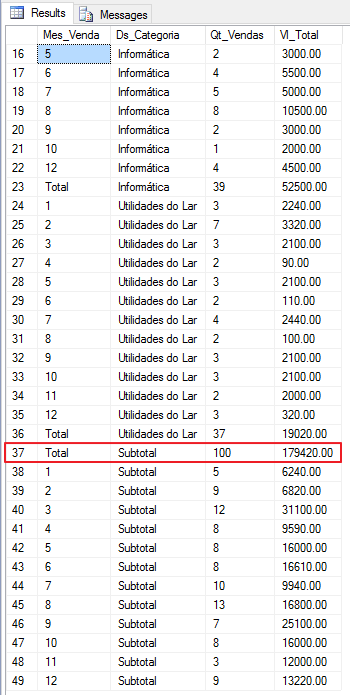
Vea que usando la función CUBE() puedo obtener el totalizador general, el totalizador de la columna Month_Venda y el totalizador de la columna Categoría. Es decir, en la función CUBO genera todas las posibilidades de combinación entre las columnas utilizadas en la función.
Uso de GRUPO POR CONJUNTOS DE AGRUPACIÓN
Usar la función GROUPING SETS en GROUP BY nos permite generar totalizadores de nuestros datos usando las columnas insertadas en la función, de manera que genere diferentes totalizadores en una sola consulta. A diferencia de las funciones ROLLUP y CUBE, la función GROUPING SETS no devuelve un totalizador general.
Ejemplo 1:
SELECT
ISNULL(B.Ds_Produto, 'Total') AS Ds_Produto,
ISNULL(B.Ds_Categoria, 'Subtotal') AS Ds_Categoria,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
GROUP BY
GROUPING SETS(B.Ds_Categoria, B.Ds_Produto)
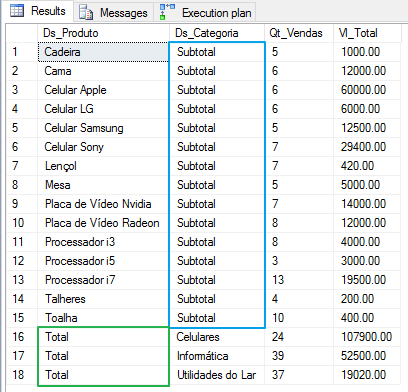
En este ejemplo, la función CONJUNTOS DE AGRUPACIÓN devuelve el totalizador por producto y luego el totalizador por categoría, donde necesitarías ejecutar 2 consultas para mostrar esta misma vista.
Ejemplo 2:
SELECT
MONTH(A.Dt_Venda) AS Mes_Venda,
B.Ds_Categoria,
B.Ds_Produto,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
GROUP BY
GROUPING SETS(MONTH(A.Dt_Venda), B.Ds_Categoria, B.Ds_Produto)
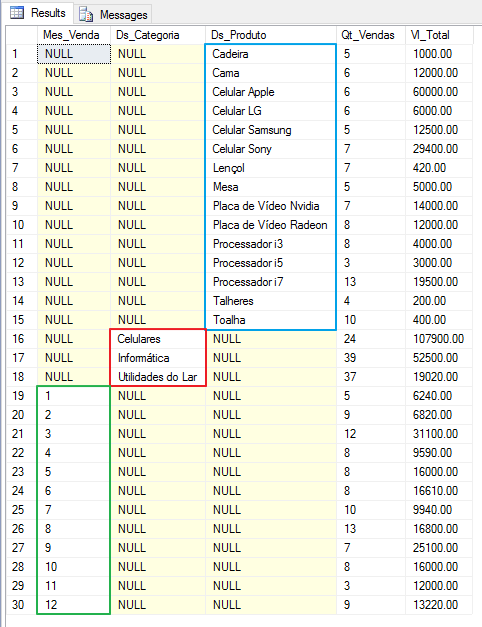
En este ejemplo, la función CONJUNTOS DE AGRUPACIÓN devolvió la suma de los valores agrupados por las 3 columnas que utilicé en la función: Suma por Mes_Ventas, Suma por Producto y Suma por Categoría. Para reproducir este mismo resultado, necesitaría crear una consulta con 3 consultas. Si hubiera 10 columnas, la consulta necesitaría 10 consultas diferentes para generar este resultado, lo que logramos con una sola consulta usando la función GROUPING SETS.
Nota: Las 3 funciones presentadas en esta publicación aceptan N columnas como parámetros, sin limitarse a solo 2 columnas.
Rendimiento y rendimiento
Ahora que hemos visto cómo funcionan las 3 funciones y visto lo práctico que es su uso, ahorrando muchas líneas de código, analicemos si son eficaces o no.
Intentaré utilizar la misma consulta para todos los casos, aunque en algunos el resultado (output) es diferente, ya que realmente tiene objetivos diferentes, pero solo para demostrar el costo y el plan de ejecución de cada uno.
UNION TODO (Consulta de ejemplo):
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
(19 filas afectadas)
Mesa 'Mesa de Trabajo'. Recuento de escaneo 0, lecturas lógicas 0, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
Tabla '#Productos'. Recuento de escaneo 2, lecturas lógicas 204, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
Tabla '#Ventas'. Recuento de escaneo 3, lecturas lógicas 64, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
(1 fila(s) afectada(s))
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 79 ms.
Tiempo de análisis y compilación de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
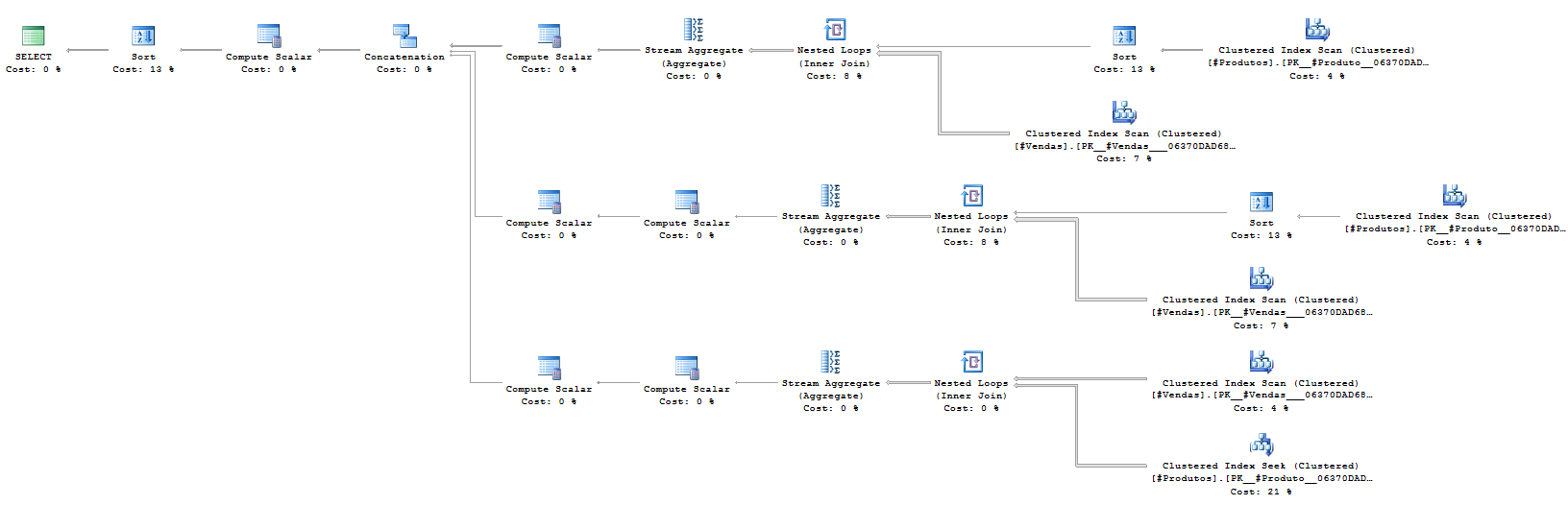
GRUPO POR ROLLUP (Consulta del ejemplo 1)
Tiempo de análisis y compilación de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tiempo de análisis y compilación de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
(19 filas afectadas)
Tabla '#Ventas'. Recuento de escaneo 1, lecturas lógicas 31, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
Mesa 'Mesa de Trabajo'. Recuento de escaneo 0, lecturas lógicas 0, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
Tabla '#Productos'. Recuento de escaneo 1, lecturas lógicas 2, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
(1 fila(s) afectada(s))
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 57 ms.
Tiempo de análisis y compilación de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.

GRUPO POR CUBO (Consulta del ejemplo 1)
Tiempo de análisis y compilación de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tiempo de análisis y compilación de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 6 ms.
(49 filas afectadas)
Mesa 'Mesa de Trabajo'. Recuento de escaneo 2, lecturas lógicas 71, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
Tabla '#Productos'. Recuento de escaneo 0, lecturas lógicas 200, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
Tabla '#Ventas'. Recuento de escaneo 1, lecturas lógicas 2, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
(1 fila(s) afectada(s))
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 210 ms.
Tiempo de análisis y compilación de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.

AGRUPAR POR CONJUNTOS DE AGRUPACIÓN (consulta del ejemplo 1)
Tiempo de análisis y compilación de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tiempo de análisis y compilación de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 5 ms.
(18 filas afectadas)
Mesa 'Mesa de Trabajo'. Recuento de escaneo 2, lecturas lógicas 35, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
Tabla '#Ventas'. Recuento de escaneo 1, lecturas lógicas 31, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
Tabla '#Productos'. Recuento de escaneo 1, lecturas lógicas 2, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura anticipada lob 0.
(1 fila(s) afectada(s))
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 58 ms.
Tiempo de análisis y compilación de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.

Ejecutando las 4 consultas juntas:
Plan de ejecución del explorador SQL Sentry Plan

Plan de ejecución de SQL Server Management Studio

Es decir, con estas pruebas y utilizando esta masa de datos, podemos decir que las consultas realizadas con estas funciones tienen más rendimiento que utilizar subconsultas con varias consultas para devolver datos agrupados. Esto no significa que esta afirmación siempre será cierta, dependerá mucho de tu entorno y de tu masa de datos.
Espero que te haya gustado esta publicación.
¡Un abrazo!

Comentarios (0)
Cargando comentarios...