
¡Hola, chicos!
En este artículo, quiero explicarles exactamente qué significa el mensaje "La cadena o los datos binarios se truncarían", cómo podemos identificar qué cadena está causando el error, cómo ocultar este mensaje de error (si lo desea), qué ha impactado el cambio en sys.messages en este tema desde SQL Server 2016+ ¡y mucho más!
Entonces, si tiene dificultades para identificar y corregir las apariciones de este mensaje de error, hoy será la última vez que esto seguirá siendo un problema para usted.
¿Qué es "los datos de cadena o binarios se truncarían"?
Uno de los errores más comunes de SQL Server, el mensaje "La cadena o los datos binarios se truncarían" ocurre cuando un valor intenta insertarse o actualizarse en una tabla y es mayor que el tamaño máximo de campo.
Ejemplo 1: tamaño máximo de campo de 10 caracteres, cadena de 10:
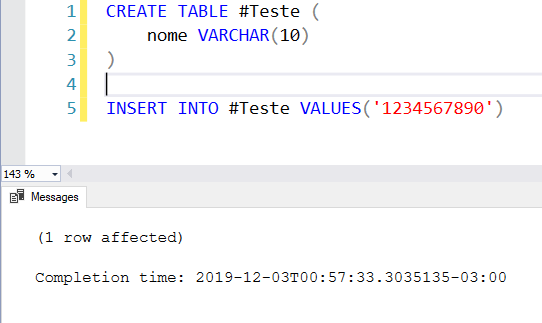
Ejemplo 2: tamaño máximo de campo de 10 caracteres, cadena de 11:
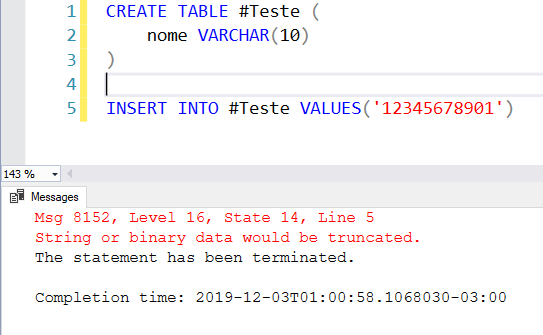
Ejemplo 3: Difícil identificar el error
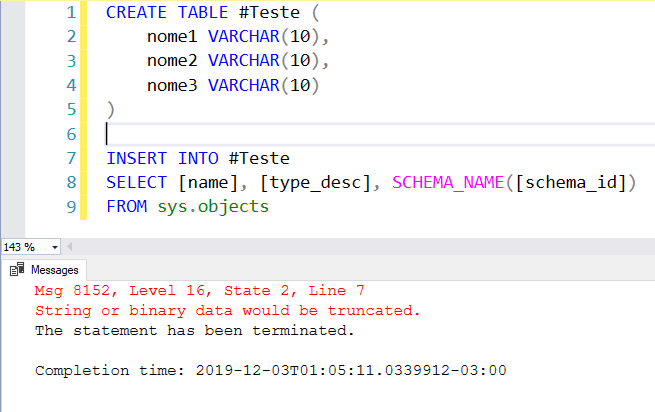
Mira el ejemplo 3. Ya no estoy insertando un valor fijo, sino de otra tabla. Este tipo de situación puede parecer simple en un escenario como el de los ejemplos 1 y 2, pero cuando inserta varios registros, especialmente tomando datos de varias columnas, es difícil identificar qué registro y qué columna está causando este mensaje de error y esta tarea puede terminar tomando más tiempo del que le gustaría.
Cómo evitar el truncamiento de cadenas
Si desea ignorar el truncamiento de cadenas en un momento u operación determinada, tiene la opción de hacerlo en SQL Server, como ya se demostró en el artículo. SQL Server: ¿por qué NO utilizar SET ANSI_WARNINGS OFF?. No recomiendo usar esta técnica de ninguna manera, ya que es una solución que solo es enmascarar el problema y no corregirlo, pero me gustaría demostrar que existe y que es posible hacerlo.
Cuando utiliza el comando SET ANSI_WARNINGS OFF, evita que el motor de SQL Server genere este error durante la ejecución, lo que provoca que el texto de 14 caracteres se trunque y se almacene en la columna de 10 caracteres. Los caracteres sobrantes serán silenciosamente descartado, ignorando y enmascarando un problema en el registro de datos en su sistema, sin que nadie lo sepa.
Ejemplo:
SET NOCOUNT ON
SET ANSI_WARNINGS OFF
IF ((@@OPTIONS & 8) > 0) PRINT 'SET ANSI_WARNINGS is ON'
IF (OBJECT_ID('tempdb..#Teste') IS NOT NULL) DROP TABLE #Teste
CREATE TABLE #Teste ( Nome VARCHAR(10) )
INSERT INTO #Teste
VALUES ('Dirceu Resende') -- 14 caracteres
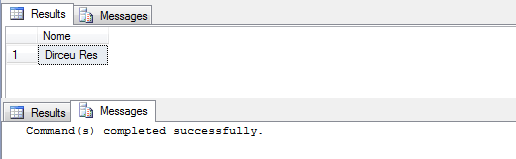
SELECT * FROM #Teste
Regrese con SET ANSI_WARNINGS ON (predeterminado):

Regrese con SET ANSI_WARNINGS OFF:
Los datos de cadena o binarios se truncarían en SQL Server 2019
SQL Server 2019 se lanzó el 4 de noviembre de 2019, durante Microsoft Ignite, y con él, se lanzó oficialmente una amplia gama de nuevas funciones.
Una de estas nuevas características son los nuevos mensajes disponibles en sys.messages, que ya les había compartido en mi artículo. SQL Server 2019: lista de nuevas funciones y características desde finales de agosto de 2018:

Con este cambio, ahora es mucho más fácil identificar exactamente dónde se está produciendo el truncamiento de valores:
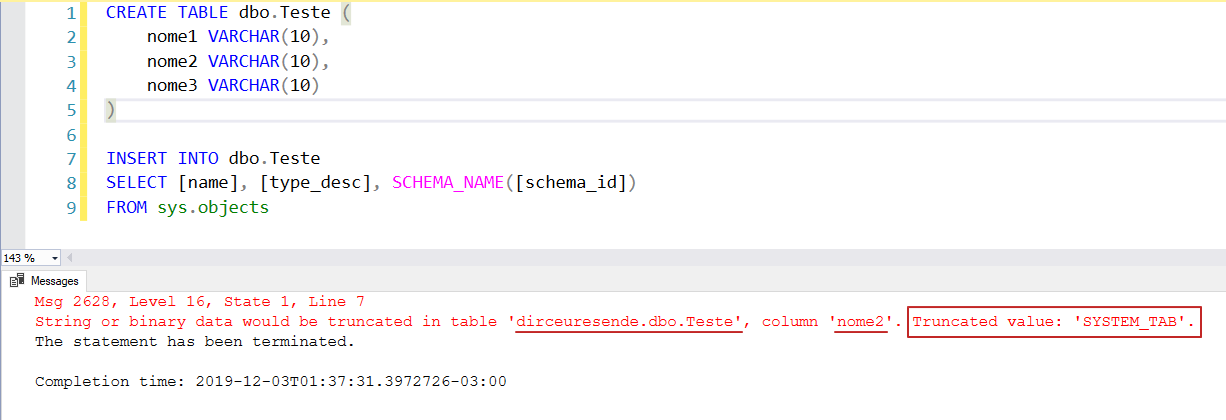
Es decir, este nuevo comportamiento solo funcionará automáticamente en SQL Server 2019, si la base de datos de conexión está en modo de compatibilidad 150 en adelante.
Qué cambió a partir de SQL Server 2016+
Con los cambios necesarios para esta implementación en SQL Server 2019, Microsoft terminó lanzando este nuevo mensaje también en las versiones 2016 (comenzando con SP2 Cumulative Update 6) y 2017 (comenzando con Cumulative Update 12). Y para poder utilizar este nuevo mensaje, podemos utilizar 2 formas diferentes:
Forma 1: uso del parámetro de inicialización -T460
La primera y más práctica forma es habilitar traceflag 460 en toda la instancia usando el parámetro de inicialización -T460 en el servicio SQL Server:
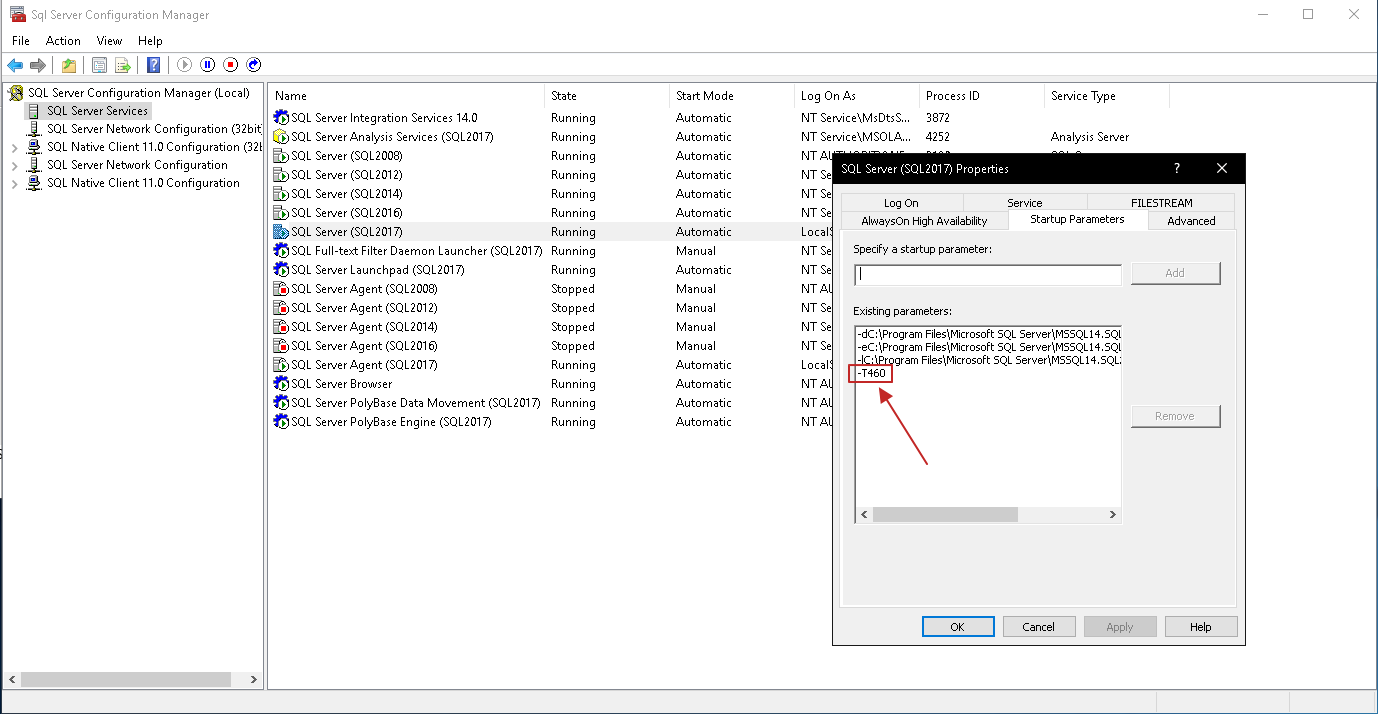
Una vez agregado será necesario reiniciar el servicio y a partir de ese momento el nuevo mensaje estará funcionando por defecto, sin necesidad de realizar ningún cambio en la consulta:
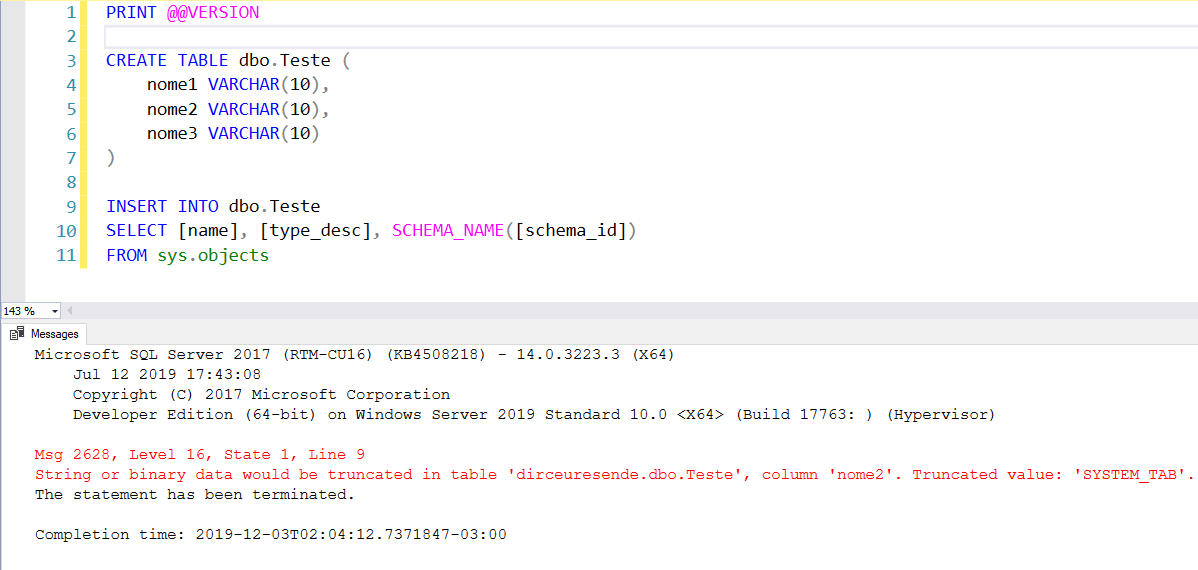
Forma 2: usando traceflag 460
Una forma que no requiere reiniciar el servicio SQL Server y tampoco requiere cambiar el código es usando el comando DBCC TRACEON, que le permite activar este traceflag a nivel de sesión y a nivel de instancia (global):
Nivel de sesión (solo afecta a tu sesión):
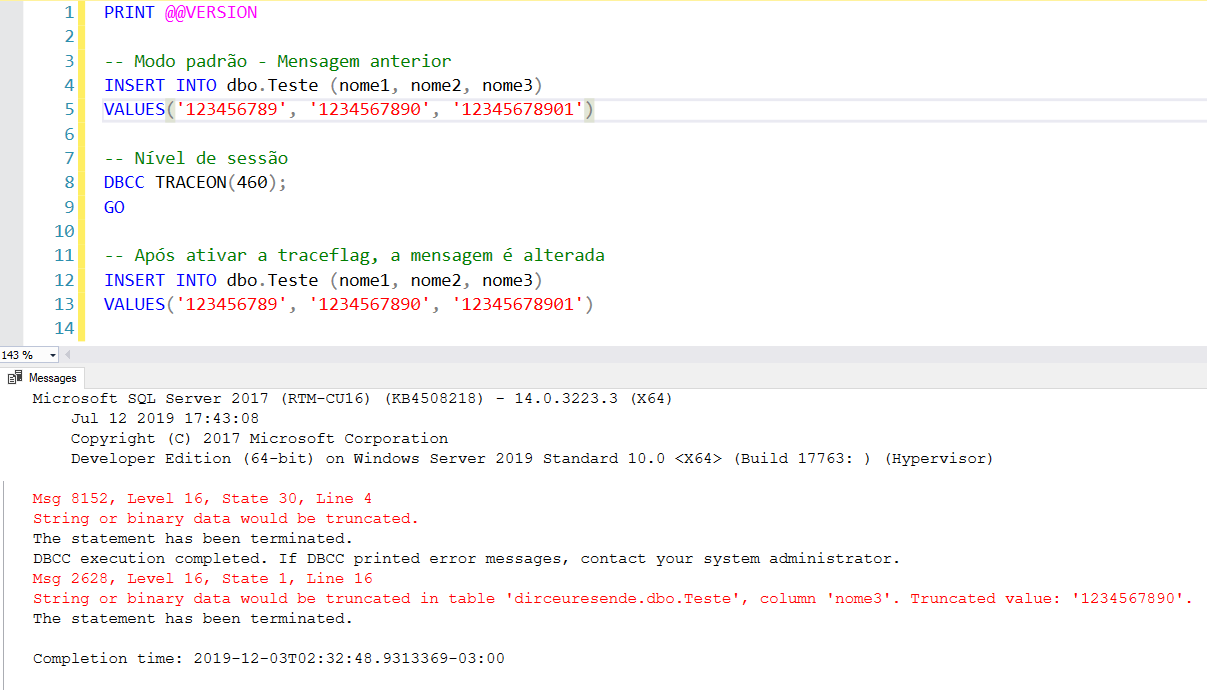
Nivel de instancia (global – afecta a todas las sesiones):
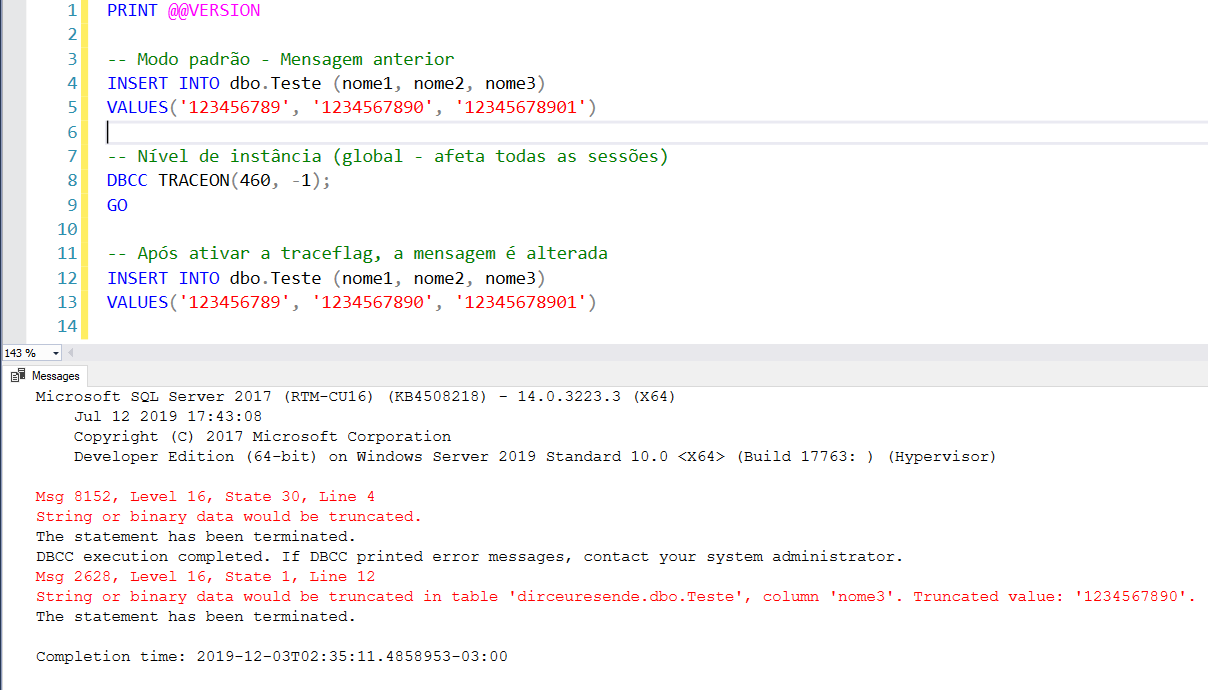
Guión utilizado:
PRINT @@VERSION
CREATE TABLE dbo.Teste (
nome1 VARCHAR(10),
nome2 VARCHAR(10),
nome3 VARCHAR(10)
)
-- Modo padrão - Mensagem anterior
INSERT INTO dbo.Teste (nome1, nome2, nome3)
VALUES('123456789', '1234567890', '12345678901')
-- Nível de instância (global - afeta todas as sessões)
DBCC TRACEON(460, -1);
GO
-- Nível de sessão (afeta apenas a sua sessão)
DBCC TRACEON(460);
GO
-- Após ativar a traceflag, a mensagem é alterada
INSERT INTO dbo.Teste (nome1, nome2, nome3)
VALUES('123456789', '1234567890', '12345678901')Identificar el truncamiento de cadenas antes de SQL Server 2016
Si está utilizando una versión anterior a 2016 y tiene dificultades para identificar qué valores exceden el límite de una columna, le compartiré un script simple que puede identificar este tipo de error incluso en versiones anteriores de SQL Server, creando una tabla “clonada” de la original, con el tamaño de las columnas establecido al máximo, insertando los datos en esta nueva tabla y comparando el tamaño utilizado con el tamaño de las columnas de la tabla original.
Ejemplo de una situación en la que se puede utilizar el script:
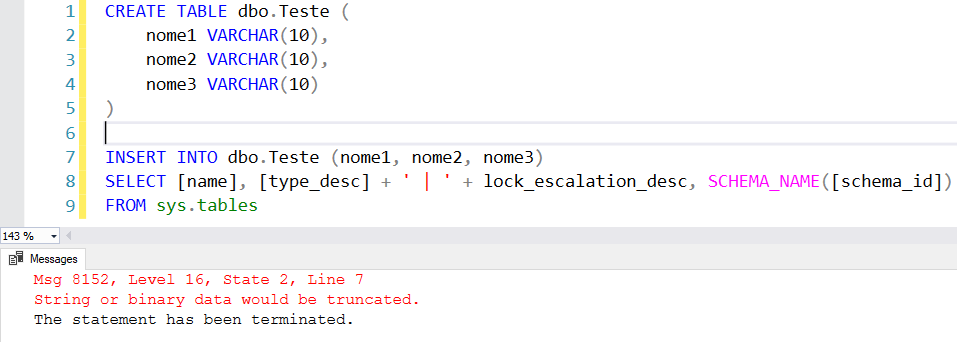
Intenté ejecutar mi comando INSERT y me dio un error en algún valor, en alguna columna, que no sé cuál es. Ahora es el momento de pensar en el trabajo que llevará identificar esto, especialmente si tienes alrededor de 100 columnas en lugar de solo estas 3 en el ejemplo... Tener que insertar los datos en una tabla "clon" y consultar y comparar el tamaño más grande de cada columna... Parece laborioso...
Para facilitar el trabajo de identificación de esta columna, compartiré con usted el siguiente script, que realiza esta identificación por usted. Recuerde cambiar el nombre de la tabla fuente y el script INSERT/UPDATE en la tabla clonada con su script original.
DECLARE @Nome_Tabela VARCHAR(255) = 'Teste'
-- Crio uma tabela com a mesma estrutura
IF (OBJECT_ID('tempdb..#Tabela_Clonada') IS NOT NULL) DROP TABLE #Tabela_Clonada
SELECT *
INTO
#Tabela_Clonada
FROM
dbo.Teste -- Tabela original (LEMBRE-SE DE ALTERAR AQUI TAMBÉM)
WHERE
1=2 -- Não quero copiar os dados
-- Agora, vou alterar todas as colunas varchar/char/nvarchar/nchar para varchar(max)
DECLARE @Query VARCHAR(MAX) = ''
SELECT
@Query += 'ALTER TABLE #Tabela_Clonada ALTER COLUMN [' + B.[name] + '] ' + UPPER(C.[name]) + '(MAX); '
FROM
sys.tables A
JOIN sys.columns B ON B.[object_id] = A.[object_id]
JOIN sys.types C ON B.system_type_id = C.system_type_id
WHERE
A.[name] = @Nome_Tabela
AND B.system_type_id IN (167, 175, 231, 239) -- varchar/char/nvarchar/nchar
AND B.max_length > 0
EXEC(@Query)
------------------------------------------------------------------------------------------------------------------
-- Faço a inserção dos dados que estão apresentando erro na tabela temporária (LEMBRE-SE DE ALTERAR AQUI TAMBÉM)
------------------------------------------------------------------------------------------------------------------
INSERT INTO #Tabela_Clonada
-- Alterar esse SELECT aqui pelo seu
SELECT [name], [type_desc] + ' | ' + lock_escalation_desc, SCHEMA_NAME([schema_id])
FROM sys.tables
-- Crio uma tabela temporária com o tamanho máximo de caracteres de cada coluna
SET @Query = ''
SELECT
@Query = @Query + 'SELECT ' + QUOTENAME(A.[name], '''') + ' AS coluna, ' + QUOTENAME(B.[name], '''') + ' AS tipo, MAX(DATALENGTH(' + QUOTENAME(A.[name]) + ')) AS tamanho FROM #Tabela_Clonada UNION '
FROM
tempdb.sys.columns A
JOIN sys.types B on B.system_type_id = A.system_type_id and B.[name] <> 'sysname'
WHERE
A.[object_id] = OBJECT_ID('tempdb..#Tabela_Clonada')
AND B.system_type_id IN (167, 175, 231, 239) -- varchar/char/nvarchar/nchar
SET @Query = LEFT(@Query, LEN(@Query)-6)
IF (OBJECT_ID('tempdb..#Tamanho_Maximo_Coluna') IS NOT NULL) DROP TABLE #Tamanho_Maximo_Coluna
CREATE TABLE #Tamanho_Maximo_Coluna (
coluna VARCHAR(255),
tipo VARCHAR(255),
tamanho INT
)
INSERT INTO #Tamanho_Maximo_Coluna
EXEC(@Query)
-- E por fim, faço a comparação dos dados de uma tabela pela outra
SELECT
B.[name] AS coluna,
C.[name] AS tipo,
B.max_length AS tamanho_atual,
D.tamanho AS tamanho_necessario
FROM
sys.tables A
JOIN sys.columns B ON B.[object_id] = A.[object_id]
JOIN sys.types C ON B.system_type_id = C.system_type_id
JOIN #Tamanho_Maximo_Coluna D ON B.[name] = D.coluna
WHERE
A.[name] = @Nome_Tabela
AND B.system_type_id IN (167, 175, 231, 239) -- varchar/char/nvarchar/nchar
AND B.max_length < D.tamanho
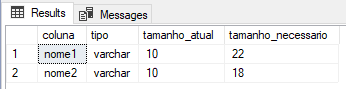
Al ejecutar este script, tendremos información exacta sobre qué columnas son demasiado pequeñas para los datos que están recibiendo y cuál es el tamaño ideal para poder almacenar estos datos.
Espero que hayas disfrutado de este artículo, un fuerte abrazo y ¡nos vemos en el próximo post!
Abrazos
Referencias:
- SQL Server 2019: lista de nuevas funciones y características
- SQL Server: ¿por qué NO utilizar SET ANSI_WARNINGS OFF?
- ¿Cómo estuvo el SQL Server 2019 News Live en el canal dotNET?
- https://www.sqlshack.com/sql-truncate-enhancement-silent-data-truncation-in-sql-server-2019/
- https://imasters.com.br/banco-de-dados/adeus-string-binary-data-truncated
- https://www.brentozar.com/archive/2019/03/how-to-fix-the-error-string-or-binary-data-would-be-truncated/

Comentarios (0)
Cargando comentarios...