Hola, chicos,
Todo está bien ?
En este post me gustaría empezar hablando de un tema que me gusta mucho que es el Performance Tuning, tema del que ya hablé en el 2da Reunión del Capítulo SQL Server ES – 10/06/2017.
Este tema siempre está entre los más buscados por los profesionales de bases de datos, desarrolladores y empresas que buscan consultoría DBA con experiencia. A diferencia de muchas áreas de la base de datos, Performance Tuning siempre requiere un análisis del problema y varias pruebas antes de tomar cualquier acción. Aunque existen buenas prácticas para esto, no existe una fórmula mágica o “receta fácil” que siempre resuelva los problemas de rendimiento, independientemente del escenario y el entorno.
Espero que les guste esta serie 🙂
¿Por qué es tan importante el ajuste del rendimiento?
- "En el mundo actual, la mayoría de las personas no tienen la paciencia para esperar mucho tiempo a que se cargue un sitio web y terminan visitando otro de inmediato". (escoladomarketingdigital.com.br)
- “En promedio, los usuarios abandonarán cualquier sitio web si no se carga en su teléfono en tres segundos” (Google)
- Una de las mayores razones del fracaso de Windows Vista fue el hecho de que era un sistema extremadamente pesado y lento (tecnoblog.net)
- "La tableta TouchPad de HP fue uno de los lanzamientos más esperados de 2011 y pronto se convirtió en el mayor fracaso del año. El dispositivo, creado para competir con el iPad de Apple, duró apenas siete semanas en el mercado antes de que HP tomara la decisión de ponerle fin, alegando como motivo las bajas ventas. ¿La razón? Los consumidores reconocieron inmediatamente que el teléfono celular era demasiado lento" (estadao.com.br)
- "El 55% de los estudiantes en Canadá admiten estar estresados por computadoras lentas, lo que resulta en el síndrome del reloj de arena". (nytimes.com)
- "El 66% de los estadounidenses se sienten estresados por los ordenadores lentos y el 23% se describe a sí mismo como muy estresado por ello". (Reuters.com)
En el escenario actual, los usuarios ya no tienen la paciencia de esperar a que se cargue una pantalla o a que se haga clic en un botón. Los usuarios quieren respuestas rápidas de los sistemas y para lograrlo, la base de datos debe proporcionar condiciones para que los sistemas puedan consultar los datos en la base de datos sin causar retrasos en el sistema.
Para ello, el DBA necesita tener el conocimiento para identificar posibles ralentizaciones, que pueden deberse a varios factores:
- Ausencia de índices en la tabla o índices ineficientes para una consulta determinada
- Fragmentación de índices o tablas.
- Cabellos
- Eventos de espera (Ej.: PAGEIOLATCH_EX, OLEDB, etc.)
- Consulta mal escrita
- CPU sobrecargada
- Alto tiempo de lectura del disco
- Volumen muy grande de información.
- contención tempdb
- Problemas de red
¿Cómo funciona el ajuste de rendimiento?
Para realizar un análisis de rendimiento de tuning, enumeraré las actividades que generalmente son necesarias para lograr su objetivo:
entender el problema
Esta actividad del proceso de ajuste del rendimiento consiste en identificar, de forma macro, el origen de la lentitud en el entorno. Si ya sabes qué rutina vas a intentar optimizar, este proceso ya está completo.
En esta actividad deberás consultar las rutinas y colecciones de datos de tu instancia para analizar, por ejemplo:
- Rutinas con alta duración de tiempo
- Rutinas que tienen un alto tiempo de CPU
- Rutinas con alto volumen de E/S (lecturas/escrituras)
- Análisis de registros del servidor
- Análisis de eventos de espera de instancia.
- Análisis del historial de bloqueos y puntos muertos
- Análisis del historial de rutinas ejecutándose en el momento de lentitud.
- Análisis del historial de bloqueos y puntos muertos
- Informes de fragmentación de índices y tablas.
- Informes de tablas sin actualización de estadísticas.
- informes de índice faltantes
Para poder comprender e identificar el problema es necesario disponer de todos (o buena parte) de los controles indicados anteriormente. Le proporcionarán datos e información sobre lo que sucede en su instancia cuando ocurre un problema de rendimiento.
preparar el diagnostico
Ahora que ha identificado qué está causando la lentitud, es el momento de descubrir por qué sucede. En este paso, analizaremos minuciosamente la rutina específica que tiene un rendimiento deficiente para desglosarla y descubrir consultas que se pueden optimizar.
En esta actividad tenemos varias formas de ayudar con el análisis, como por ejemplo:
- Análisis del plan de ejecución, para identificar cómo se está realizando la consulta internamente (e identificar posibles anomalías, como la conversión implícita)
- Análisis de los índices utilizados, para garantizar que cubran las consultas más importantes (índice de cobertura)
- Uso de SET STATISTICS IO y TIME, para medir el número de lecturas/escrituras que se realizan para cada objeto consultado, así como el tiempo de respuesta de cada operación.
- En muchos casos, la estructura de la base de datos está optimizada, pero la consulta está mal escrita. Por lo tanto, la consulta puede sufrir cambios para optimizar el uso de los índices existentes.
- Analizar el histograma del índice para validar si realmente está siendo efectivo y tiene sentido
Aplicar consejos y técnicas de optimización
Una vez que haya identificado las consultas que están mostrando un bajo rendimiento, es hora de aplicar técnicas de ajuste del rendimiento, ya sea cambiando la consulta (query tuning), creando/cambiando índices, actualizando estadísticas, etc.
En esta etapa, probablemente necesitará probar más de una mejora para lograr el mejor resultado, dependiendo de su entorno. En muchos casos, necesitarás un cambio más para optimizar la consulta.
Pruebas, Pruebas, Pruebas y luego, ¡más Pruebas!
Este paso, junto con el paso Aplicar técnicas y consejos de optimización, son probablemente los que requerirán la mayor parte de su tiempo. Todo trabajo de ajuste del rendimiento requiere que los cambios se prueben y validen antes de aplicarlos al entorno.
Como mencioné anteriormente, no existe una “receta de pastel” que siempre sea más eficaz en todas las situaciones (aunque existen buenas prácticas que GENERALMENTE funcionan mejor). He visto varios casos en los que un cambio generó una enorme ganancia de rendimiento en un entorno y en el otro terminó sin tener efecto. Recuerde: Hay N factores que pueden influir en el desempeño de su banco y todos deben ser considerados.
Desde mi experiencia, te recomiendo: NUNCA apliques una mejora de rendimiento sin probarla A CONTINUACIÓN antes de aplicarla. Esto se recomienda especialmente si ha realizado cambios en la consulta para lograr un mejor rendimiento. En mi vida diaria, hago cambios en las consultas tanto en el aspecto estructural como en las reglas de negocio, por lo que las pruebas terminan siendo aún más importantes.
Aplicar optimización
En la etapa final del proceso de Performance Tuning, que generalmente es la más tranquila, aplicarás los cambios sugeridos a tu entorno luego de una intensa batería de pruebas ya realizadas.
Si tienes más de un entorno en tu empresa (Ej: DEV, HOM, PRD), es muy interesante subir los cambios por entorno, para poder observar el comportamiento del sistema después de los cambios.
Una parte sumamente importante de esta etapa es la recopilación de los resultados obtenidos luego de aplicar los cambios. Esta parte del proyecto Performance Tuning es vital para ganar confianza en el trabajo del DBA y poder mostrar las ventajas que se obtienen en el día a día invirtiendo tiempo (y en consecuencia, dinero) en este trabajo dentro de la empresa.
Ajuste del rendimiento: índices
Los índices de bases de datos son una de las estructuras más importantes (quizás la más) cuando se trata del rendimiento de las consultas. Los índices son estructuras de disco asociadas con una tabla o vista, que aceleran la recuperación de filas ordenando datos en forma de árboles binarios.
Usando una analogía, sería como el índice o resumen de un libro, permitiéndote buscar rápidamente lo que estás buscando. Aunque los índices son sumamente útiles y eficaces, hay que crearlos con mucho rigor y discreción: Los índices ocupan espacio en el disco, es decir, si creas muchos índices, pueden ocupar más espacio que la propia tabla.
Además, los índices aceleran las consultas, pero ralentizan las operaciones de escritura (INSERT, UPDATE, DELETE), porque estas operaciones necesitan actualizar la tabla y los datos de todos los índices relacionados. Si tiene una tabla que requiere mucha escritura y pocas lecturas (por ejemplo, tabla de registro/historial), es posible que esta tabla no sea una buena candidata para crear índices. ¡CUIDADOSO!
Algunos grandes candidatos para formar parte de un índice son las columnas computadas (calculadas) a las que se accede con frecuencia, columnas que forman parte de una clave externa (FK), columna de identidad de la tabla.
Se puede identificar otro gran candidato para crear un índice después de un análisis más profundo en el que se haya identificado una consulta muy pesada que se realiza con frecuencia en su entorno. En este caso, creará un índice específico para esta consulta, que tendrá todas las columnas utilizadas por esta consulta, en una técnica conocida como Índice de cobertura.
Si quieres profundizar más en los índices en SQL Server, te recomiendo leer el post Comprender cómo funcionan los índices en SQL Server.
Ajuste del rendimiento: el plan de ejecución
El Plan de ejecución es una herramienta gráfica para ayudar al DBA/desarrollador a comprender cómo se realizan las consultas en la base de datos y cómo el optimizador de consultas las interpreta. Esta herramienta es sumamente importante para cualquiera que esté pensando en realizar un trabajo de optimización de consultas en la base de datos, ya que sólo entendiendo cómo se realiza la consulta internamente es posible identificar puntos de mejora.

Ejemplo de un plan de ejecución en análisis
¿Qué podemos extraer de un plan?
- ¿Estás usando índice?
- ¿Qué índice se utilizó?
- ¿Trabajo paralelo?
- ¿Qué tamaño tienen los datos?
- ¿Cuál es la operación de mayor costo?
- ¿Qué operador se utilizó?
¿Cómo leemos un plan?
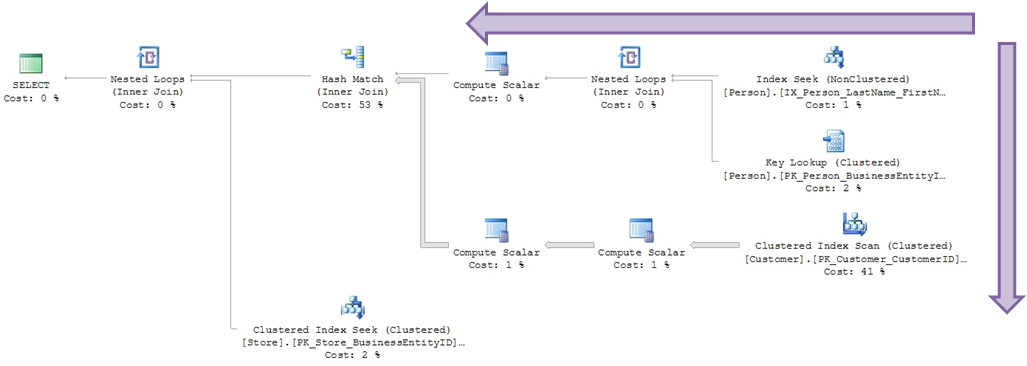
Las flechas indican el volumen de registros procesados:

Porcentaje del coste de cada operación

Información detallada a través de información sobre herramientas
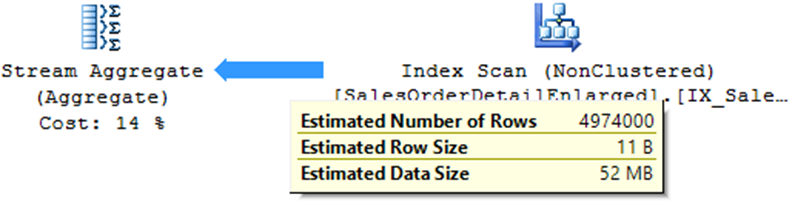
sugerencia de índice

¿Cuál es la diferencia entre el plan estimado y el actual?
Plan estimado:
- Útil para desarrollo donde no se puede ejecutar la consulta.
- Muy útil en escenarios donde la consulta original tarda mucho en procesarse
- No funciona con objetos temporales.
- No identifica algunas advertencias (Ej: E/S residuales)
- Basados en estadísticas (si están desactualizadas pueden distorsionar la realidad)
Plan actual:
- La consulta original se ejecuta en la base de datos.
- Al final de las operaciones se muestra el plan de ejecución que realmente utilizó el optimizador de consultas.
¿Cómo veo mi plan de ejecución de consultas?
Para poder visualizar el plan de ejecución de la consulta que vas a ejecutar, simplemente selecciona una de las 2 opciones marcadas en el cuadro a continuación:
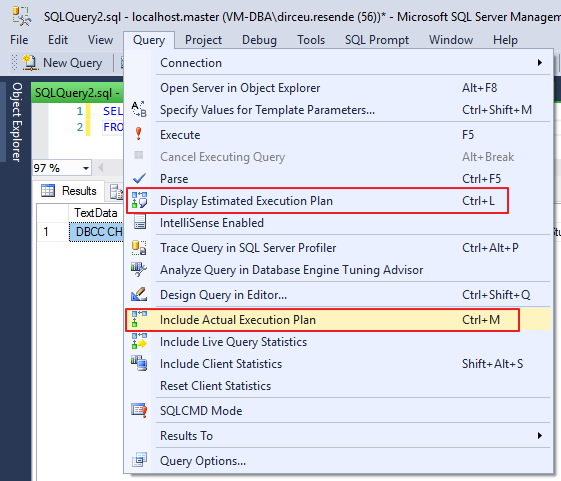
Opción en la interfaz para mostrar el plan de ejecución.
Sin embargo, tienen comportamientos diferentes: Al seleccionar la opción “Incluir Plan de Ejecución Actual”, las consultas realizadas a partir de ese momento devolverán el plan generado al final de la ejecución.
La opción “Mostrar plan de ejecución estimado” se debe utilizar al seleccionar las consultas en las que se desea ver el plan estimado.
Independientemente de la forma elegida, una vez seleccionada la opción, simplemente ejecute su consulta (Plan actual) o visualice el plan de las consultas seleccionadas (Plan estimado) para visualizar el plan de ejecución gráficamente en su Management Studio (SSMS):
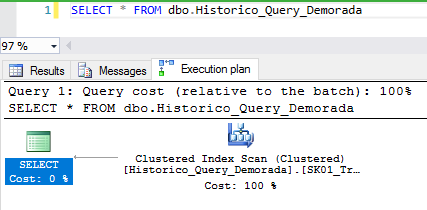
Otra forma de ver el plan de ejecución estimado es mediante comandos SET:
SET SHOWPLAN_ALL OFF
GO
SET SHOWPLAN_XML ON
GO
SELECT * FROM dbo.Historico_Query_Demorada
GO
SET SHOWPLAN_XML OFF
GO
SET SHOWPLAN_ALL ON
GO
SELECT * FROM dbo.Historico_Query_Demorada
Resultado:

Para ver gráficamente el plan de ejecución, simplemente haga clic en el XML generado:

¿Cómo ver el plan de ejecución de una consulta en ejecución?
Para ver el plan de ejecución de consultas en ejecución, simplemente ejecute la siguiente consulta:
SELECT
A.session_id,
B.command,
A.login_name,
C.query_plan
FROM
sys.dm_exec_sessions AS A WITH (NOLOCK)
LEFT JOIN sys.dm_exec_requests AS B WITH (NOLOCK) ON A.session_id = B.session_id
OUTER APPLY sys.dm_exec_query_plan(B.[plan_handle]) AS C
WHERE
A.session_id > 50
AND A.session_id <> @@SPID
AND (A.[status] != 'sleeping' OR (A.[status] = 'sleeping' AND A.open_transaction_count > 0))
Si desea conocer toda la información sobre la ejecución de consultas, incluido el uso de CPU, tempdb, lecturas, escrituras, el plan de ejecución de consultas en sí y mucho más, eche un vistazo a la versión simplificada de sp_whoisactive que puse a disposición en la publicación. SQL Server: consulta para devolver consultas en ejecución (sp_WhoIsActive sin consumir TempDB).
¿Cómo ver los planes de ejecución en caché?
Generalmente, cuando ejecuta una consulta, SQL Server generará un plan de ejecución para ella y dejará este plan almacenado en el caché de la base de datos, de modo que en caso de que la misma consulta se ejecute nuevamente, el optimizador de consultas no necesita analizar la consulta y generar un nuevo plan. Por lo tanto, es posible ver los planes que se guardan en caché en SQL Server.
Vale la pena recordar que cada vez que se reinicia la instancia, los planes almacenados en caché se descartan. Además, SQL Server solo conserva los planes más utilizados, ya que no puede almacenar los planes para cada consulta ya realizada en la instancia.
Para ver los planes almacenados en caché, simplemente utilice la siguiente consulta:
SELECT
cp.objtype AS ObjectType,
OBJECT_NAME(st.objectid, st.dbid) AS ObjectName,
cp.usecounts AS ExecutionCount,
st.text AS QueryText,
qp.query_plan AS QueryPlan
FROM
sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) AS st
ORDER BY
ExecutionCount DESC
Resultado:
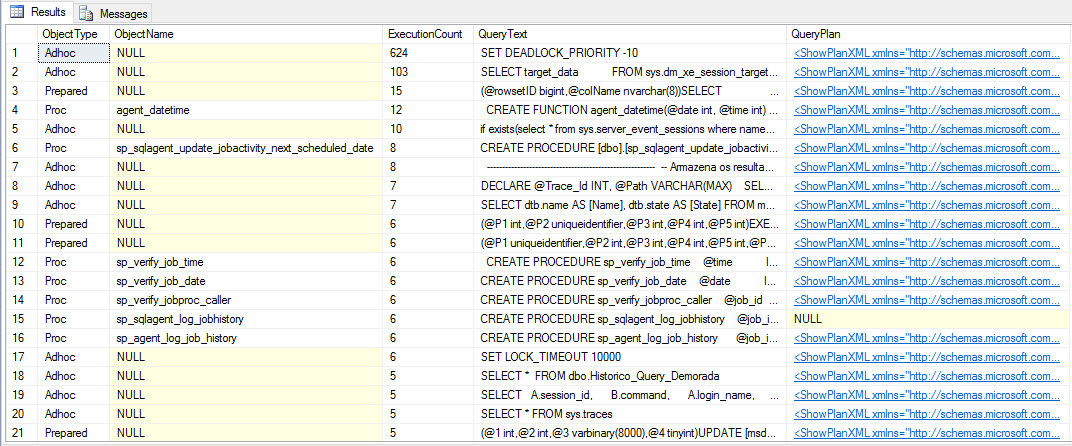
¿Cómo eliminar planes de ejecución almacenados en caché?
Como mencioné anteriormente, mantener los planes de ejecución en caché es una buena práctica para evitar que el optimizador de consultas tenga que analizar consultas y generar nuevos planes de ejecución innecesariamente. Sin embargo, en varias situaciones es importante que puedas eliminar un plan específico del caché o incluso todos los planes.
Para borrar todo el caché de su instancia, simplemente ejecute el siguiente comando:
DBCC FREEPROCCACHE
GO
Para borrar todo el caché de una base de datos determinada, ejecute este comando:
DECLARE @DbID INT = (SELECT database_id FROM sys.databases WHERE [name] = 'dirceuresende')
DBCC FLUSHPROCINDB (@DbID)
GO
Para eliminar el caché de un procedimiento o función almacenados, simplemente ejecute un comando de modificación de procedimiento/alteración de función y se recreará el plan.
Una opción interesante es la sugerencia CON RECOMPILE, que cuando se usa al cambiar un objeto, hace que se cree un nuevo plan de ejecución con cada llamada a ese objeto.
ALTER PROCEDURE [dbo].[stpTeste]
WITH RECOMPILE -- A cada execução, será gerado um novo plano
AS
BEGIN
SELECT 1
END
Otra forma de forzar la recompilación de un objeto y generar un nuevo plan de ejecución es mediante el procedimiento almacenado interno sp_recompile:
sp_recompile @objname = 'dbo.stpBusca_Rastreamento_Correios'

¿Quiénes son los principales operadores del Plan de Ejecución?
En esta sesión, enumeraré los operadores más comunes que verá con más frecuencia durante sus análisis.
Escaneo de mesa
– Operador que consiste en leer TODOS los datos de la tabla para encontrar la información que se debe devolver.
– Sucede en una tabla sin un índice de clúster
– En general, operación de alto costo.
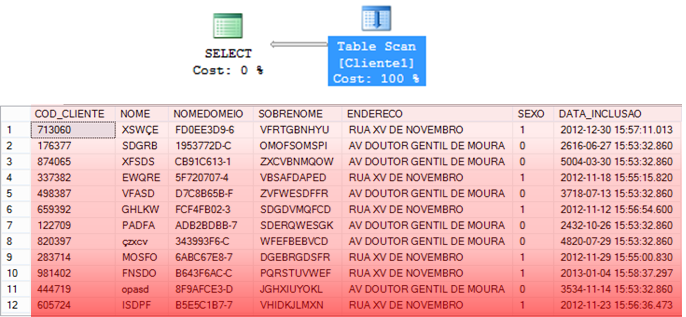
Escaneo de índice agrupado
– Operador que consiste en leer TODOS los datos del índice CLUSTERED para encontrar la información que se debe devolver.
– Por lo general suele ser un poco más rápido que Table Scan, pues los datos ya están ordenados en el índice.
– El escaneo de índice puede ser un reflejo de una búsqueda costosa
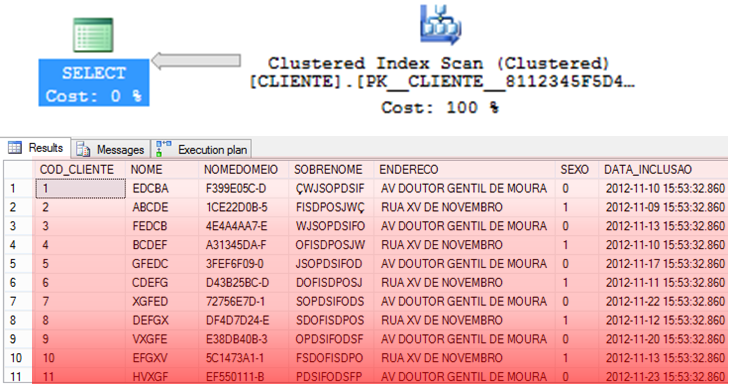
Búsqueda de índice agrupado y búsqueda de índice no agrupado
– Algoritmo que tiende a ser extremadamente eficiente para devolver registros específicos.
– Como los datos ya están ordenados en el índice, puedes utilizar algoritmos más eficientes como QuickSort y ShellSort.
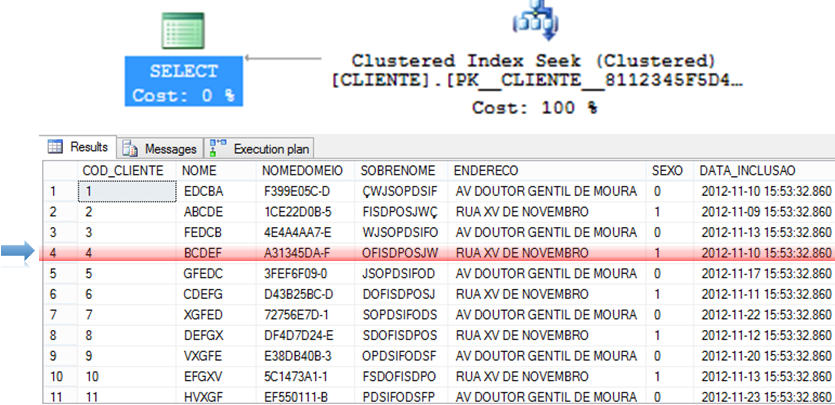
Búsqueda de claves y búsqueda de RID
Cuando se realiza una consulta sobre una tabla, el optimizador de consultas de SQL Server determinará el mejor método de acceso a los datos según las estadísticas recopiladas y elegirá el que tenga el menor costo.
Como el índice agrupado es la tabla en sí y genera un gran volumen de datos, generalmente se utiliza para la consulta el índice no agrupado de menor costo. Esto puede crear un problema, ya que la consulta a menudo selecciona columnas donde no todas están indexadas, lo que hace que se use un índice no agrupado para buscar la información indexada (Index Seek NonClustered) y el índice agrupado para devolver la información restante, donde el índice no agrupado tiene un puntero a la posición exacta de la información en el índice agrupado (o el ROWID, si la tabla no tiene un índice agrupado).
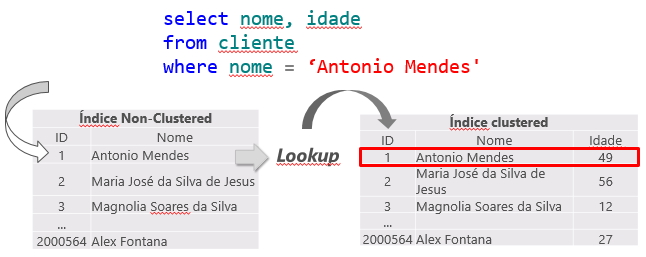
Esta operación se llama Búsqueda de claves, en el caso de tablas con índice agrupado o Búsqueda RID (RID = ID de fila) para tablas que no tienen un índice agrupado (llamadas tablas HEAP) y debido a que genera 2 operaciones de lectura para una sola consulta, se debe evitar siempre que sea posible.
Búsqueda de claves
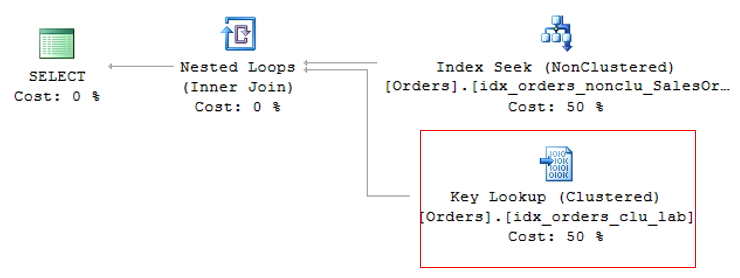
Búsqueda RID
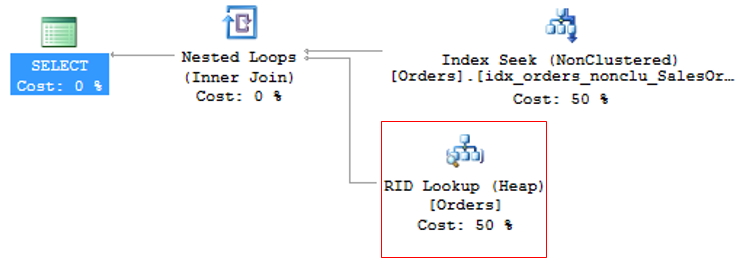
Para evitar KeyLookup, basta con utilizar la técnica del índice de cobertura, que consiste en agregar las columnas principales que se utilizan en las consultas de tablas al índice NonClustered (INCLUDE). Esto significa que el optimizador de consultas puede obtener toda la información leyendo solo el índice elegido, sin tener que leer también el índice agrupado.
Sin embargo, se debe prestar gran atención a la modelización de los índices. No se recomienda agregar todas las columnas de la tabla al índice no agrupado, ya que será tan grande que ya no será efectivo y el optimizador de consultas puede incluso decidir no usarlo y preferir el operador Index Scan, que lee todo el índice secuencialmente, perjudicando el rendimiento de la consulta.
Para evitar la búsqueda RID, simplemente cree el índice agrupado en la tabla y preste atención a los eventos de búsqueda de claves que puedan surgir.
Clasificar
– Operador que suele ser muy pesado en consultas, especialmente con grandes volúmenes de datos.
– Procesamiento línea por línea
– ORDENAR POR o DISTINTO
– Generalmente se puede descartar y ordenar en la aplicación (lucha DBA x DEV)
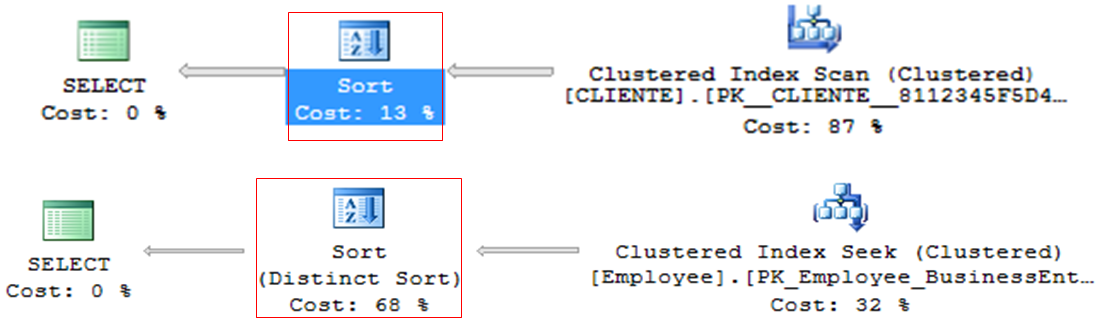
Agregado de corriente
– Consultas con agrupación (GROUP BY, DISTINCT, etc.)
– Operador que suele ser muy pesado en las consultas.
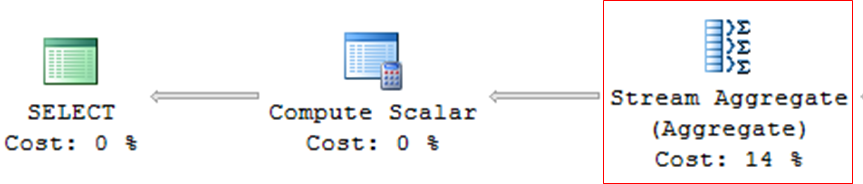
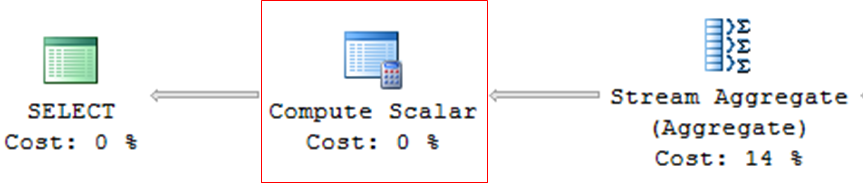
Calcular escalar
– Operador utilizado en consultas con expresiones, cálculos matemáticos o conversiones (CAST, CONVERT)
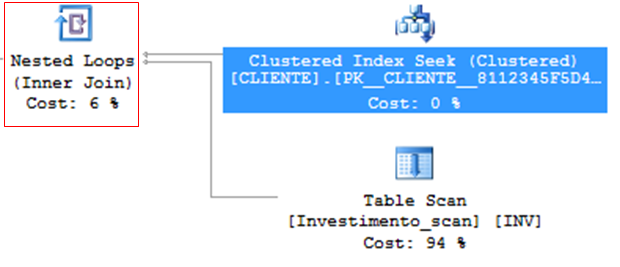
Bucles anidados
– Algoritmo muy eficiente
– Ideal para escenarios con pocos registros
– Para cada fila de la tabla exterior, escanéelas todas en la tabla interior.
– Bajo consumo de CPU y memoria.
– La variable de tabla (@Table) SIEMPRE usará Nested Loops, independientemente del número de registros, porque al no tener estadísticas, el número estimado de filas siempre es 1 (a menos que lo fuerces con una pista).
Cómo funciona internamente:
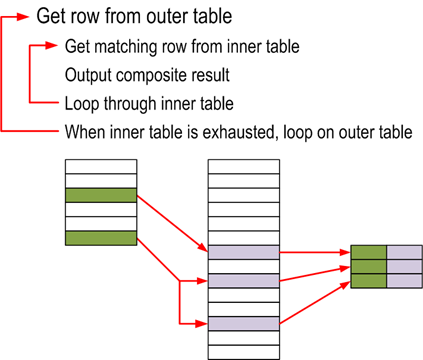
Algoritmo utilizado:
for each row R1 in the outer table
for each row R2 in the inner table
if R1 joins with R2
return (R1, R2)
Fusionar Unirse
– Eficiente, pero necesita datos ordenados
– Ideal para escenarios con muchos registros
– Si los datos no están ordenados, Merge Join puede solicitar la clasificación a través de Sort Merge Join
– Si ambas tablas no tienen un índice único, se produce la combinación de combinación de muchos a muchos: tablas sin PK, use tempdb, menos eficiente
– Merge Join y su impacto en TEMPDB – Consumo mucho mayor que Nested Loop, ya que las coincidencias se realizan en la memoria y el volumen de datos suele ser mayor también.
– En general consume poca CPU y memoria. A menudo se encuentra en consultas con índices de cobertura.
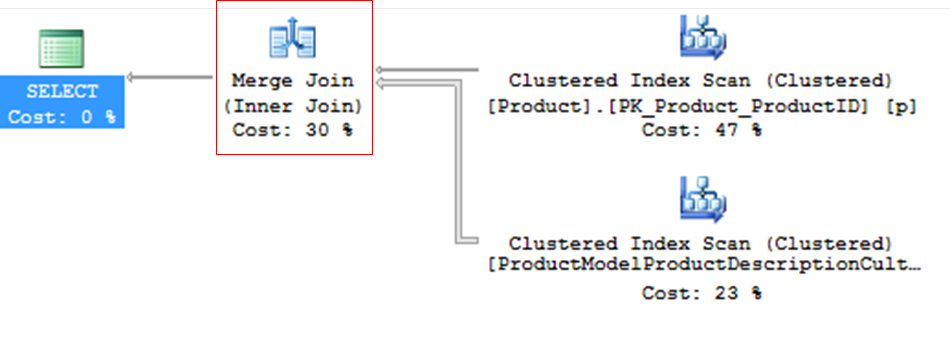
Cómo funciona internamente:
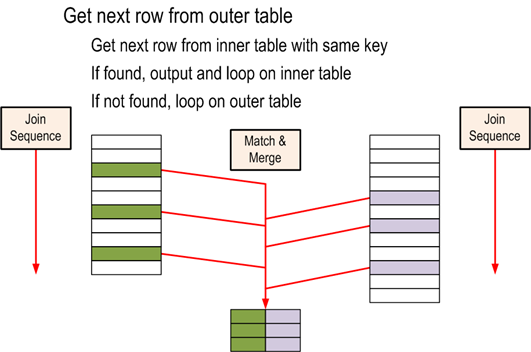
Algoritmo utilizado:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
return (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Algunos consejos para solucionar problemas
– Búsqueda: Resolver con índice de cobertura o INCLUIR
– ¡El escaneo de índice puede ser un reflejo de una búsqueda costosa! ¡Prestar atención!
– Tenga cuidado con las conversiones, especialmente las conversiones en la cláusula WHERE. ¡Pueden ser mortales para tu cita!
– Preste atención a las estadísticas obsoletas: número estimado <> número actual

– Rastreo de parámetros: Ocurre cuando un mismo SP tiene diferentes tipos de comportamiento según los parámetros informados, por lo que el plan utilizado no es el adecuado. Intente crear procedimientos diferentes para cada parámetro o agregar una cláusula CON RECOMPILE o Sugerencia OPCIÓN (RECOMPILE).
¡Bueno, eso es todo, amigos!
Esta publicación es solo una introducción al "arte" del ajuste del rendimiento y debía publicarse hace aproximadamente 3 meses, cuando di mi charla en la segunda reunión de SQL Server ES y no escribí esta publicación para complementar la presentación para aquellos que no asistieron.
Espero volver pronto con nuevos posts sobre este tema que me parece tan interesante.
Un abrazo y ¡hasta la próxima!

Comentarios (0)
Cargando comentarios...