Hola, chicos,
¡Buen día!
En este post comentaré la estructura del índice, que ayuda mucho a optimizar las consultas, reduciendo IO y CPU y devolviendo información más rápidamente. Sin embargo, hay que tener mucho cuidado a la hora de crear índices, ya que ocupan mucho espacio en disco y si no están bien modelados pueden no ser tan efectivos.
Introducción
Un índice es una estructura en disco asociada con una tabla o vista, que acelera la recuperación de filas. Un índice contiene claves creadas a partir de una o más columnas, y estas claves se almacenan en una estructura (árbol B) que permite a SQL Server encontrar la fila o filas asociadas con los valores clave de forma rápida y eficiente.
Con la creación del índice, la base de datos creará una estructura de árbol ordenada para facilitar las búsquedas, donde el primer nivel es la raíz, los niveles intermedios contienen los árboles de índice y el último nivel contiene los datos y una lista doblemente enlazada que conecta las páginas de datos, que contiene un puntero de página anterior y una página siguiente, como se muestra en la siguiente imagen:
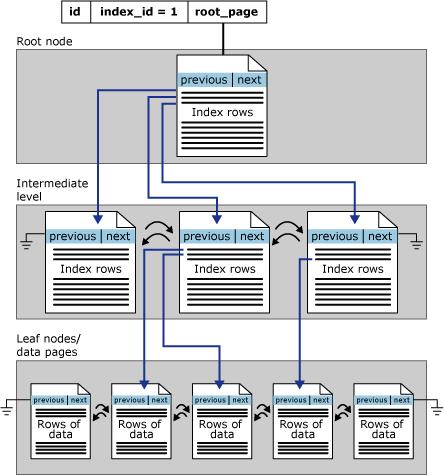
El uso de un índice no siempre generará un buen rendimiento, ya que elegir un índice incorrecto puede provocar un rendimiento insatisfactorio. Por lo tanto, el trabajo del optimizador de consultas es seleccionar un índice o una combinación de índices solo cuando mejora el rendimiento y evitar la recuperación indexada cuando degrada el rendimiento.
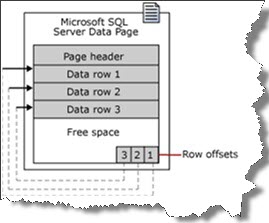
La página de datos contiene un encabezado con índice, con una lista doblemente enlazada que contiene un puntero a la página anterior y siguiente, un bloque con registros (datos) y en el pie de página hay ranuras de matriz que contienen las direcciones de memoria de las páginas con los datos.
Recomendaciones al crear un índice
Las siguientes tareas conforman la estrategia recomendada para la creación de índices:
- Comprender las características de las consultas más utilizadas. Por ejemplo, saber que una consulta utilizada con frecuencia une dos o más tablas le ayudará a determinar el mejor tipo de índice a utilizar.
- Comprender las características de las columnas utilizadas en las consultas. Por ejemplo, un índice es ideal para columnas que tienen un tipo de datos entero y también columnas únicas o no nulas. Para las columnas que tienen subconjuntos de datos bien definidos, puede utilizar un índice filtrado en SQL Server 2008 y versiones posteriores.
- Determine qué opciones de índice podrían aumentar el rendimiento al crear o mantener el índice. Por ejemplo, la creación de un índice agrupado en una tabla grande existente se beneficiaría de la opción de índice EN LÍNEA. La opción EN LÍNEA permite que continúe la actividad simultánea en los datos subyacentes mientras se crea o reconstruye el índice.
- Determine la mejor ubicación de almacenamiento para el índice. Un índice no agrupado se puede almacenar en el mismo grupo de archivos que la tabla subyacente o en un grupo de archivos diferente. La ubicación de almacenamiento del índice puede mejorar el rendimiento de las consultas al aumentar el rendimiento de E/S del disco. Por ejemplo, almacenar un índice no agrupado en un grupo de archivos que se encuentra en un disco diferente al grupo de archivos de la tabla puede mejorar el rendimiento porque se pueden leer varios discos al mismo tiempo.
- Cree índices no agrupados en columnas utilizadas con frecuencia en predicados y condiciones JOIN en consultas. Sin embargo, evite agregar columnas innecesarias. Agregar muchas columnas de índice aumentará el espacio en disco y el rendimiento del mantenimiento del índice.
- Cubrir índices puede mejorar el rendimiento de las consultas porque todos los datos necesarios para satisfacer los requisitos de la consulta existen dentro del propio índice. Es decir, sólo se requieren páginas de índice, no páginas de datos de índice agrupados o de tablas, para recuperar los datos solicitados, lo que reduce las operaciones generales de E/S del disco. Por ejemplo, una consulta de las columnas a y b en una tabla que tiene un índice compuesto creado en las columnas a, b y c puede recuperar los datos especificados únicamente del índice.
- Escriba consultas que inserten o modifiquen tantas colas como sea posible en una sola declaración, en lugar de utilizar varias consultas para actualizar esas mismas colas. Utilizando una sola declaración, se puede explorar el mantenimiento optimizado del índice.
- Evalúe el tipo de consulta y cómo se utilizan las columnas en la consulta. Por ejemplo, una columna utilizada en una consulta de coincidencia exacta sería una buena candidata para un índice agrupado o no agrupado.
- Mantenga corta la longitud de la clave de índice para los índices agrupados. Además, los índices agrupados se benefician al crearse en columnas únicas o no nulas.
- Examinar la unicidad de la columna. Un índice único en lugar de un índice no único en la misma combinación de columnas proporciona información adicional al optimizador de consultas, lo que hace que el índice sea más útil.
- Examina la distribución de los datos en la columna. A menudo, una consulta larga se debe a la indexación de una columna con pocos valores únicos o al realizar una combinación en dicha columna. Por ejemplo, una guía telefónica física ordenada alfabéticamente por apellido no localizará rápidamente a una persona si todos en la ciudad se llaman Smith o Jones.
- Considere el orden de las columnas si el índice contiene varias columnas. La columna que se utiliza en la cláusula WHERE en un criterio de consulta igual (=), mayor que (>), menor que (>) o ENTRE, o que participa en una combinación, debe posicionarse en primer lugar. Las columnas adicionales deben ordenarse según su nivel de distinción, es decir, de más distinta a menos distinta.
Por ejemplo, si el índice se define como Apellido, Nombre, el índice es útil cuando el criterio de consulta es WHERE LastName = 'Smith' o WHERE LastName = Smith AND FirstName LIKE 'J%'. Sin embargo, el optimizador de consultas no usaría el índice para una consulta que haya buscado solo en Nombre (DONDE Nombre = 'Jane'). - Especifique el factor de relleno del índice. Cuando se crea o recrea un índice, el valor del factor de relleno determina el porcentaje de espacio en cada página a nivel de hoja que se llenará con datos, reservando el resto de cada página como espacio libre para crecimiento futuro. Por ejemplo, especificar un valor de factor de relleno de 80 significa que el 20 por ciento de cada página a nivel de hoja estará vacía, lo que proporciona espacio para que el índice se expanda a medida que se agregan datos a la tabla subyacente. Un valor de factor de relleno elegido correctamente puede reducir posibles divisiones de página al proporcionar suficiente espacio para la expansión del índice a medida que se agregan datos a la tabla subyacente. Para obtener más información sobre el factor de relleno, accede a este enlace.
- Considere indexar las columnas calculadas.
Índice agrupado o no agrupado
Índice agrupado
El índice CLUSTERED se monta sobre la propia tabla, creando una estructura de árbol ORDENADO para facilitar las búsquedas. Por este motivo solo se puede crear 1 índice de este tipo por tabla y no se puede utilizar INCLUDE de columnas en este tipo de índice. Cada hoja del índice del cluster tiene toda la información del registro.
Recomendaciones para la columna que conformará el índice agrupado:
- Campos numéricos (smallint, tinyint, int, bigint)
- Datos en crecimiento
- Valores únicos
- Valores que no se actualizan
- Datos que se utilizan frecuentemente en búsquedas, uniones, etc.
- Generalmente se creará en la clave principal.
Ejemplo clásico: Diccionario (Encontras la palabra y junto a ella ya tienes la definición).
Índice no agrupado
El índice NONCLUSTERED es una estructura ORDENADA separada, que contiene solo la columna indexada (y las columnas INCLUDE, si las hay) y una tabla puede tener N índices de este tipo. Si es necesario consultar alguna información que no está en el índice NONCLUSTERED, la información se localiza mediante el índice agrupado de la tabla (Key Lookup). Si la tabla no tiene un índice CLUSTERED, se utilizará el IAM (Mapa de asignación de índice) para localizar la información mediante RID (RowID – en la operación de búsqueda de RID).
Ejemplo clásico: Índice de un libro (Ubicas la página donde está el capítulo en el índice y luego vas a la página para ver la información).
Índice compuesto o con columnas incluidas
Una pregunta muy común al crear un índice, estas 2 formas de crear un índice funcionan de manera muy diferente:
- Índice compuesto: Es un índice que se compone de más de una columna. En este caso, la estructura de árbol del índice tendrá información sobre las columnas que forman parte del índice en todos los niveles y las búsquedas utilizando estas columnas se filtrarán más rápidamente.
- Índice con columna incluida.: Es un índice formado por una o más columnas y que incluye otras columnas. En este caso, la estructura del árbol de índice se ensamblará solo con las columnas que forman parte del índice, y solo en el último nivel del árbol (hoja) estará disponible la información de las columnas incluidas (ocupando menos espacio en disco que el índice compuesto). Se recomienda este tipo de índice para evitar operadores de búsqueda de claves, incluidas columnas que no forman parte del índice y que siempre se buscan, es decir, este índice y también el índice agrupado se utilizan para devolver otra información.
Cuándo utilizar un índice con columnas incluidas
Cuando hay columnas que se usan en SELECT solo para mostrar datos, pero que no se usan para filtros, es interesante agregar estas columnas en INCLUDE, ya que la información solo se registrará a nivel de hoja del índice (último índice), solo para visualización (debido a esto, este tipo de índice generalmente es más pequeño que el índice compuesto).
Si estas columnas no están presentes en el índice, será necesario utilizar otro índice (siempre en el índice agrupado o en el ROWID, si la tabla no está agrupada) o tener que escanear toda la tabla para encontrar esta información. Ver más detalles en este enlace
Ejemplo de creación de un índice con columna incluida
CREATE NONCLUSTERED INDEX SK01 ON dbo.Cliente(CPF) INCLUDE(RG, Nome)
Cuándo utilizar el índice compuesto
Cuando una consulta recurrente usa más de una columna en la cláusula WHERE, se puede usar un índice compuesto (con más de una columna). En esta situación, el plan de consulta utiliza el conjunto de columnas para filtrar, de modo que los índices más restrictivos (índices de igualdad) deben aparecer primero en la definición, antes de los índices menos restrictivos (desigualdades). Las otras columnas que componen el índice se copian en todas las hojas del árbol de índice (consumiendo más espacio).
Ejemplo de creación de un índice compuesto
CREATE NONCLUSTERED INDEX SK01 ON dbo.Cliente(CPF, RG)
¿Qué es y cómo evitar la búsqueda de claves y la búsqueda de RID?
Cuando se realiza una consulta sobre una tabla, el optimizador de consultas de SQL Server determinará el mejor método de acceso a los datos según las estadísticas recopiladas y elegirá el que tenga el menor costo.
Como el índice agrupado es la tabla en sí y genera un gran volumen de datos, generalmente se utiliza para la consulta el índice no agrupado de menor costo. Esto puede crear un problema, ya que la consulta a menudo selecciona columnas donde no todas están indexadas, lo que hace que se use un índice no agrupado para buscar la información indexada (Index Seek NonClustered) y el índice agrupado para devolver la información restante, donde el índice no agrupado tiene un puntero a la posición exacta de la información en el índice agrupado (o el ROWID, si la tabla no tiene un índice agrupado).
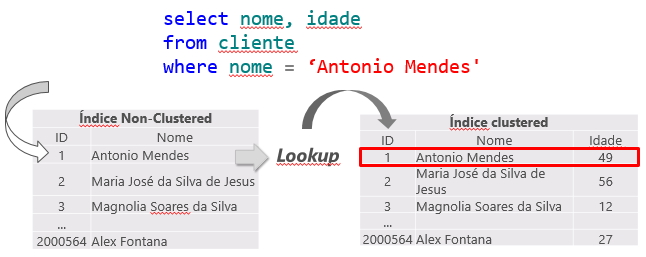
Esta operación se llama Búsqueda de claves, en el caso de tablas con índice agrupado o Búsqueda RID (RID = ID de fila) para tablas que no tienen un índice agrupado (llamadas tablas HEAP) y debido a que genera 2 operaciones de lectura para una sola consulta, se debe evitar siempre que sea posible.
Búsqueda de claves
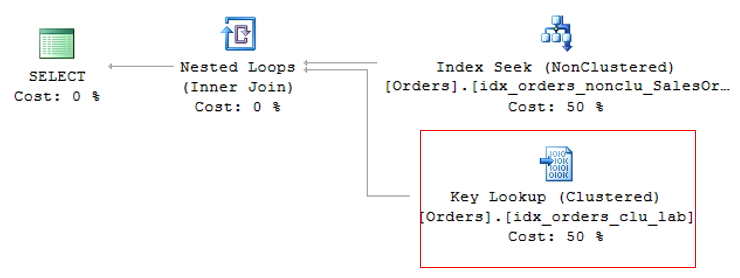
Búsqueda RID
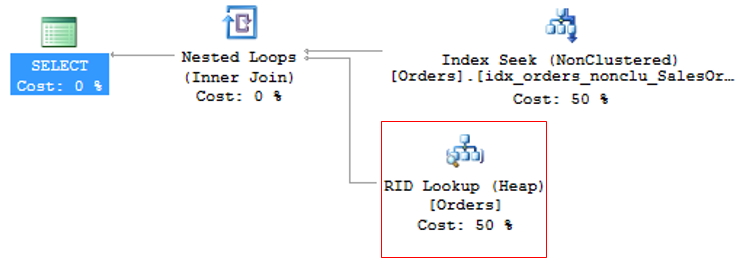
Para evitar KeyLookup, basta con utilizar la técnica del índice de cobertura, que consiste en agregar las columnas principales que se utilizan en las consultas de tablas al índice NonClustered (INCLUDE). Esto significa que el optimizador de consultas puede obtener toda la información leyendo solo el índice elegido, sin tener que leer también el índice agrupado.
Sin embargo, se debe prestar gran atención a la modelización de los índices. No se recomienda agregar todas las columnas de la tabla al índice no agrupado, ya que será tan grande que ya no será efectivo y el optimizador de consultas puede incluso decidir no usarlo y preferir el operador Index Scan, que lee todo el índice secuencialmente, perjudicando el rendimiento de la consulta.
Para evitar la búsqueda RID, simplemente cree el índice agrupado en la tabla y preste atención a los eventos de búsqueda de claves que puedan surgir.
Índices únicos (exclusivos)
Un índice único garantiza que la clave del índice no contenga valores duplicados y, por lo tanto, cada fila de la tabla sea única de alguna manera.
Los índices únicos de varias columnas garantizan que cada combinación de valores en la clave de índice sea única. Por ejemplo, si se crea un índice único en una combinación de columnas Apellido, Nombre y Segundo Nombre, no hay dos filas en la tabla que puedan tener la misma combinación de valores que esas columnas.
No puede crear un índice único en una sola columna si tiene NULL en más de una fila. De manera similar, no puede crear un índice único en varias columnas si la combinación de columnas tiene NULL en más de una fila, ya que estos se tratan como valores duplicados para fines de indexación.
Internamente, cuando crea una restricción PRIMARY KEY, se crea automáticamente un índice agrupado único en la columna. La gran diferencia entre PRIMARY KEY y un solo índice es que una tabla solo puede tener 1 PRIMARY KEY, pero varios índices únicos.
Ejemplo de creación de un índice único:
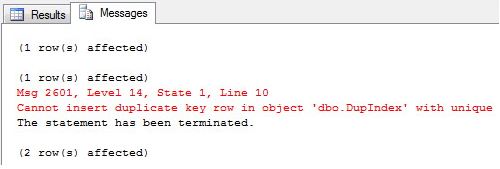
CREATE UNIQUE NONCLUSTERED INDEX SK01 ON dbo.Clientes(CPF)
Al intentar insertar un CPF en una tabla de clientes que ya existe, se mostrará un error en la pantalla de SQL Server y se cancelará la ejecución:
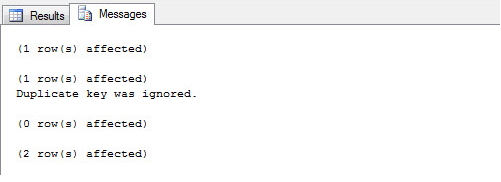
Usando el parámetro IGNORE_DUP_KEY = ON, puede permitir que el banco simplemente ignore el registro duplicado y simplemente muestre una advertencia en la pantalla:
CREATE UNIQUE NONCLUSTERED INDEX SK01 ON dbo.Clientes(CPF)
WITH(IGNORE_DUP_KEY = ON)
Reconstruir/reorganizar índices cuando sea necesario
El motor de base de datos de SQL Server mantiene automáticamente índices cada vez que se realizan operaciones de entrada, actualización o eliminación en los datos subyacentes. Con el tiempo, estas modificaciones pueden hacer que la información del índice quede dispersa por toda la base de datos (fragmentada). La fragmentación ocurre cuando los índices tienen páginas donde el orden lógico, basado en el valor clave, no coincide con el orden físico del archivo de datos. Los índices con mucha fragmentación pueden degradar el rendimiento de las consultas y provocar una respuesta lenta de la aplicación.
Identificar la fragmentación del índice
El primer paso para elegir qué método de fragmentación utilizar es analizar el índice para determinar el grado de fragmentación. Con la función del sistema sys.dm_db_index_physical_stats, puede detectar fragmentación en un índice específico, en todos los índices de una tabla o vista indexada, en todos los índices de una base de datos o en todos los índices de todas las bases de datos. Para índices particionados, sys.dm_db_index_physical_stats también proporciona información de fragmentación por partición.
SELECT
OBJECT_NAME(B.object_id) AS TableName,
B.name AS IndexName,
A.index_type_desc AS IndexType,
A.avg_fragmentation_in_percent
FROM
sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED') A
INNER JOIN sys.indexes B WITH(NOLOCK) ON B.object_id = A.object_id AND B.index_id = A.index_id
WHERE
A.avg_fragmentation_in_percent > 30
AND OBJECT_NAME(B.object_id) NOT LIKE '[_]%'
AND A.index_type_desc != 'HEAP'
ORDER BY
A.avg_fragmentation_in_percent DESC
Una vez identificado el nivel de fragmentación del índice, puedes elegir qué método se utilizará para desfragmentarlo:
– REORGANIZAR: Se utiliza cuando el nivel de fragmentación está entre el 5% y el 30%. Este método no hace que el índice no esté disponible, ya que el índice no se elimina, solo se reorganiza.
– REBUILD: Se utiliza cuando el nivel de fragmentación es superior al 30%. Este método de forma predeterminada hace que el índice no esté disponible, ya que elimina y vuelve a crear el índice. Para evitar la falta de disponibilidad, puede utilizar el parámetro ONLINE al ejecutar REBUILD.
Desfragmentando el índice
Desfragmentar un índice fragmentado (REORGANIZAR)
ALTER INDEX SK01 ON dbo.Logins
REORGANIZE
Desfragmentar todos los índices de la tabla (REORGANIZE)
ALTER INDEX ALL ON dbo.Logins
REORGANIZE
Desfragmentar todos los índices de la tabla (REBUILD)
ALTER INDEX ALL ON dbo.Logins
REBUILD
Desfragmentar todos los índices de la tabla (RECONSTRUIR – COMPLETAR)
ALTER INDEX ALL ON dbo.Logins
REBUILD WITH (FILLFACTOR = 80, SORT_IN_TEMPDB = ON, STATISTICS_NORECOMPUTE = ON, ONLINE = ON)
Para obtener más información sobre Reconstruir y Reorganizar, accede a este enlace.
Vistas del catálogo de índice y DMV
A continuación se muestra una lista de DMV y vistas de catálogos de índices que se pueden utilizar para obtener información de uso y estadísticas de índices:
DMV
- sys.dm_db_column_store_row_group_physical_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_index_operative_stats
- sys.dm_db_index_physical_stats
- sys.dm_db_index_usage_stats
- sys.dm_db_missing_index_columns
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
Vistas de catálogo
- sys.index_columns
- índices del sistema
- sys.sysindexes
- sys.sysindexkeys
- sys.xml_indexes
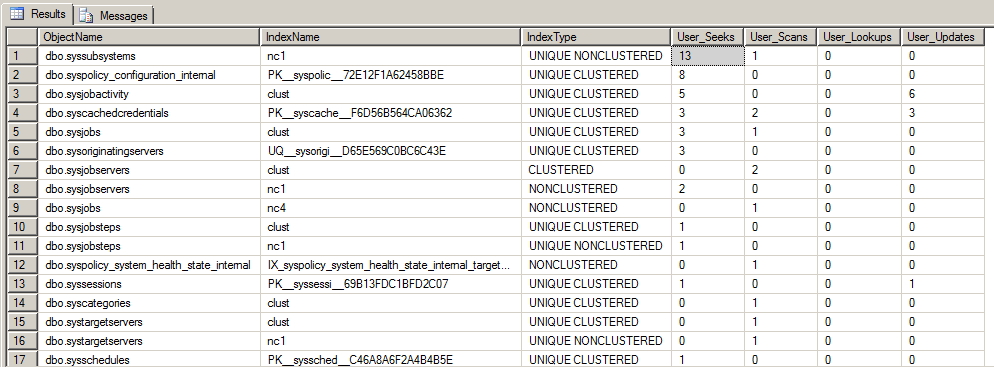
Verificar el uso del índice
Con la consulta a continuación, es posible identificar el uso de índices en la base de datos, mostrando lecturas con Index Seek (índice bien usado), Index Scan (Posible problema en el modelado de índices), Lookups y Updates (número de veces que se actualizó el índice con nuevos registros)
SELECT
ObjectName = OBJECT_SCHEMA_NAME(idx.object_id) + '.' + OBJECT_NAME(idx.object_id),
IndexName = idx.name,
IndexType = CASE WHEN is_unique = 1 THEN 'UNIQUE ' ELSE '' END + idx.type_desc,
User_Seeks = us.user_seeks,
User_Scans = us.user_scans,
User_Lookups = us.user_lookups,
User_Updates = us.user_updates
FROM
sys.indexes idx
LEFT JOIN sys.dm_db_index_usage_stats us ON idx.object_id = us.object_id AND idx.index_id = us.index_id AND us.database_id = DB_ID()
WHERE
OBJECT_SCHEMA_NAME(idx.object_id) != 'sys'
ORDER BY
us.user_seeks + us.user_scans + us.user_lookups DESC
Ayudándole a identificar el mejor candidato para el índice agrupado
Con la consulta siguiente, es posible dejar que SQL nos ayude a definir el mejor índice candidato para agruparlo en la tabla. Analizando el DMV dm_db_index_usage_stats, la consulta identifica el índice no agrupado que tiene más lecturas de búsqueda que el agrupado (en la consulta, definí un porcentaje del 150%) y el número de búsquedas es menor que las búsquedas del índice agrupado.
No se recomienda utilizar únicamente el resultado de esta consulta para esta definición. Debería servir para indicar una posible mejora en el intercambio de índices y el DBA debe realizar un análisis detallado para confirmar esta indicación.
SELECT
TableName = OBJECT_NAME(idx.object_id),
NonUsefulClusteredIndex = idx.name,
ShouldBeClustered = nc.nonclusteredname,
Clustered_User_Seeks = c.user_seeks,
NonClustered_User_Seeks = nc.user_seeks,
Clustered_User_Lookups = c.user_lookups,
DatabaseName = DB_NAME(c.database_id)
FROM
sys.indexes idx
LEFT JOIN sys.dm_db_index_usage_stats c ON idx.object_id = c.object_id AND idx.index_id = c.index_id
JOIN (
SELECT
idx.object_id,
nonclusteredname = idx.name,
ius.user_seeks
FROM
sys.indexes idx
JOIN sys.dm_db_index_usage_stats ius ON idx.object_id = ius.object_id AND idx.index_id = ius.index_id
WHERE
idx.type_desc = 'nonclustered' AND ius.user_seeks = (
SELECT
MAX(user_seeks)
FROM
sys.dm_db_index_usage_stats
WHERE
object_id = ius.object_id AND type_desc = 'nonclustered'
)
GROUP BY
idx.object_id,
idx.name,
ius.user_seeks
) nc ON nc.object_id = idx.object_id
WHERE
idx.type_desc IN ( 'clustered', 'heap' )
AND nc.user_seeks > ( c.user_seeks * 1.50 ) -- 150%
AND nc.user_seeks >= ( c.user_lookups * 0.75 ) -- 75%
ORDER BY
nc.user_seeks DESC

Identificar índices faltantes
Una de las tareas diarias de un DBA es identificar índices faltantes en la base de datos, lo que puede sugerir una mejora en el rendimiento de las consultas que se ejecutan con frecuencia. Con la consulta a continuación, podemos facilitar un poco esta tarea, porque al consultar los DMV de índice que faltan, podemos identificar estos datos rápidamente.
SELECT
mid.statement,
migs.avg_total_user_cost * ( migs.avg_user_impact / 100.0 ) * ( migs.user_seeks + migs.user_scans ) AS improvement_measure,
OBJECT_NAME(mid.object_id),
'CREATE INDEX [missing_index_' + CONVERT (VARCHAR, mig.index_group_handle) + '_' + CONVERT (VARCHAR, mid.index_handle) + '_' + LEFT(PARSENAME(mid.statement, 1), 32) + ']' + ' ON ' + mid.statement + ' (' + ISNULL(mid.equality_columns, '') + CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(mid.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement,
migs.*,
mid.database_id,
mid.[object_id]
FROM
sys.dm_db_missing_index_groups mig
INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle
WHERE
migs.avg_total_user_cost * ( migs.avg_user_impact / 100.0 ) * ( migs.user_seeks + migs.user_scans ) > 10
ORDER BY
migs.avg_total_user_cost * migs.avg_user_impact * ( migs.user_seeks + migs.user_scans ) DESC
Analizando el histograma del índice
Un punto muy importante a considerar después de crear el índice es analizar su histograma. Con esta función, es posible identificar qué tan granulares son los datos de la tabla y qué tan selectivo es nuestro índice, por lo que cuanto más selectivo sea, mejor se utilizará.
Un ejemplo de esto es crear un índice en la columna Sexo en una tabla de clientes y la distribución de datos es del 50% para cada uno de los valores. En esta situación, el índice no está siendo muy selectivo y el banco tendrá que hacer muchas lecturas para devolver la información. Para observar la cantidad de registros para cada valor, mire la columna EQ_ROWS.
Para visualizar el histograma del índice, puede utilizar el procedimiento DBCC:
-- DBCC SHOW_STATISTICS(Nome_da_Tabela, Nome_do_Indice)
DBCC SHOW_STATISTICS(Logins, SK01)
En el siguiente ejemplo podemos observar el caso de un índice muy selectivo, que tiene una densidad del 0,4% y contiene varios datos diferentes. Cuando se utiliza este índice, devolverá un volumen muy pequeño de datos.
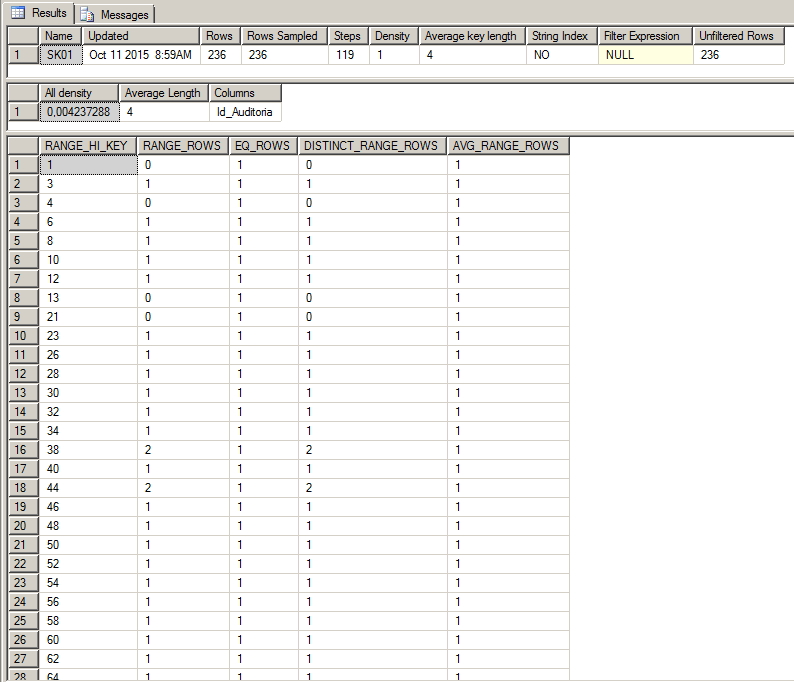
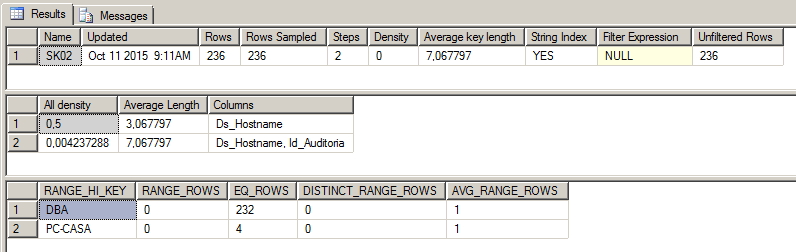
En el siguiente ejemplo, podemos identificar un índice no selectivo, con una densidad del 50% (solo 2 valores distintos), representando uno de estos valores ("DBA") el 98% (232 registros de un total de 236) de los datos recopilados. En otras palabras, si se utiliza este índice y la consulta se realiza buscando la palabra 'DBA', el índice necesitaría devolver el 98% de los datos del índice y el optimizador SQL preferiría realizar una operación de escaneo de índice en lugar de búsqueda de índice.
¡Eso es todo amigos!
¡Hasta la próxima!
sql, servidor sql, índice, índice, crear índice, no agrupado, agrupado, incluir, múltiples columnas, índice compuesto, cómo crear, cómo funciona, crear índices, cómo hacerlo, búsqueda de claves, montón, iam, búsqueda de eliminación

Comentarios (0)
Cargando comentarios...