¡Hola, chicos!
En esta publicación, me gustaría demostrar algunas formas de identificar consultas lentas o pesadas, que terminan consumiendo muchos recursos de la máquina y tardan mucho en devolver resultados, ya sea debido al uso excesivo de CPU, memoria o disco.
El propósito de este artículo es ayudarle con identificación de consultas que tienen posibles problemas de rendimiento. Una vez que haya identificado cuáles son estas consultas, debe evaluar si es necesario agregar más hardware a la máquina o iniciar actividades de ajuste de consultas y rendimiento (que no es el enfoque de esta publicación).
Análisis de eventos de espera
Ver contenidoUn buen punto de partida para nuestro análisis es consultar el DMV sys.dm_os_wait_stats, con la siguiente consulta:
SELECT *
FROM sys.dm_os_wait_stats
ORDER BY wait_time_ms DESC
Resultado:
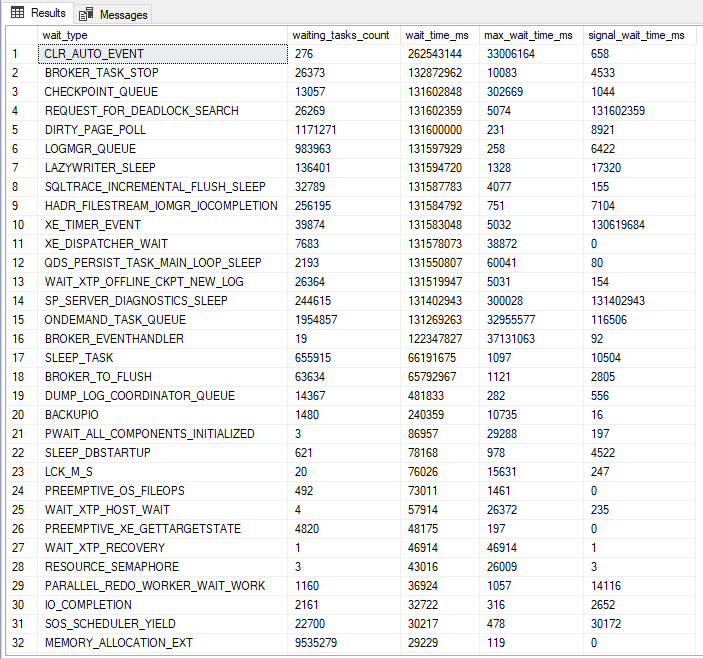
Esta consulta mostrará qué eventos de espera tomaron más tiempo, es decir, evaluará, entre todo lo que se ejecutó en la instancia, qué provocó que estas consultas esperaran más recursos, ya sea disco, CPU, memoria, red, etc. Esto es muy útil para identificar dónde está nuestro mayor cuello de botella de procesamiento.
el grande Pablo Randal puso a disposición una versión de esta consulta, que trae algunas estadísticas sobre estos eventos de espera, como el% del tiempo de espera y un enlace a la explicación de qué es este evento de espera, y también filtra eventos que generalmente son solo advertencias y no problemas, lo que facilita identificar lo que realmente está molestando a nuestra instancia.
Siguiente guión:
;WITH [Waits]
AS ( SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
( [wait_time_ms] - [signal_wait_time_ms] ) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM([wait_time_ms]) OVER () AS [Percentage],
ROW_NUMBER() OVER ( ORDER BY
[wait_time_ms] DESC
) AS [RowNum]
FROM
sys.dm_os_wait_stats
WHERE
[wait_type] NOT IN (
-- These wait types are almost 100% never a problem and so they are
-- filtered out to avoid them skewing the results. Click on the URL
-- for more information.
N'BROKER_EVENTHANDLER', -- https://www.sqlskills.com/help/waits/BROKER_EVENTHANDLER
N'BROKER_RECEIVE_WAITFOR', -- https://www.sqlskills.com/help/waits/BROKER_RECEIVE_WAITFOR
N'BROKER_TASK_STOP', -- https://www.sqlskills.com/help/waits/BROKER_TASK_STOP
N'BROKER_TO_FLUSH', -- https://www.sqlskills.com/help/waits/BROKER_TO_FLUSH
N'BROKER_TRANSMITTER', -- https://www.sqlskills.com/help/waits/BROKER_TRANSMITTER
N'CHECKPOINT_QUEUE', -- https://www.sqlskills.com/help/waits/CHECKPOINT_QUEUE
N'CHKPT', -- https://www.sqlskills.com/help/waits/CHKPT
N'CLR_AUTO_EVENT', -- https://www.sqlskills.com/help/waits/CLR_AUTO_EVENT
N'CLR_MANUAL_EVENT', -- https://www.sqlskills.com/help/waits/CLR_MANUAL_EVENT
N'CLR_SEMAPHORE', -- https://www.sqlskills.com/help/waits/CLR_SEMAPHORE
N'CXCONSUMER', -- https://www.sqlskills.com/help/waits/CXCONSUMER
-- Maybe comment these four out if you have mirroring issues
N'DBMIRROR_DBM_EVENT', -- https://www.sqlskills.com/help/waits/DBMIRROR_DBM_EVENT
N'DBMIRROR_EVENTS_QUEUE', -- https://www.sqlskills.com/help/waits/DBMIRROR_EVENTS_QUEUE
N'DBMIRROR_WORKER_QUEUE', -- https://www.sqlskills.com/help/waits/DBMIRROR_WORKER_QUEUE
N'DBMIRRORING_CMD', -- https://www.sqlskills.com/help/waits/DBMIRRORING_CMD
N'DIRTY_PAGE_POLL', -- https://www.sqlskills.com/help/waits/DIRTY_PAGE_POLL
N'DISPATCHER_QUEUE_SEMAPHORE', -- https://www.sqlskills.com/help/waits/DISPATCHER_QUEUE_SEMAPHORE
N'EXECSYNC', -- https://www.sqlskills.com/help/waits/EXECSYNC
N'FSAGENT', -- https://www.sqlskills.com/help/waits/FSAGENT
N'FT_IFTS_SCHEDULER_IDLE_WAIT', -- https://www.sqlskills.com/help/waits/FT_IFTS_SCHEDULER_IDLE_WAIT
N'FT_IFTSHC_MUTEX', -- https://www.sqlskills.com/help/waits/FT_IFTSHC_MUTEX
-- Maybe comment these six out if you have AG issues
N'HADR_CLUSAPI_CALL', -- https://www.sqlskills.com/help/waits/HADR_CLUSAPI_CALL
N'HADR_FILESTREAM_IOMGR_IOCOMPLETION', -- https://www.sqlskills.com/help/waits/HADR_FILESTREAM_IOMGR_IOCOMPLETION
N'HADR_LOGCAPTURE_WAIT', -- https://www.sqlskills.com/help/waits/HADR_LOGCAPTURE_WAIT
N'HADR_NOTIFICATION_DEQUEUE', -- https://www.sqlskills.com/help/waits/HADR_NOTIFICATION_DEQUEUE
N'HADR_TIMER_TASK', -- https://www.sqlskills.com/help/waits/HADR_TIMER_TASK
N'HADR_WORK_QUEUE', -- https://www.sqlskills.com/help/waits/HADR_WORK_QUEUE
N'KSOURCE_WAKEUP', -- https://www.sqlskills.com/help/waits/KSOURCE_WAKEUP
N'LAZYWRITER_SLEEP', -- https://www.sqlskills.com/help/waits/LAZYWRITER_SLEEP
N'LOGMGR_QUEUE', -- https://www.sqlskills.com/help/waits/LOGMGR_QUEUE
N'MEMORY_ALLOCATION_EXT', -- https://www.sqlskills.com/help/waits/MEMORY_ALLOCATION_EXT
N'ONDEMAND_TASK_QUEUE', -- https://www.sqlskills.com/help/waits/ONDEMAND_TASK_QUEUE
N'PARALLEL_REDO_DRAIN_WORKER', -- https://www.sqlskills.com/help/waits/PARALLEL_REDO_DRAIN_WORKER
N'PARALLEL_REDO_LOG_CACHE', -- https://www.sqlskills.com/help/waits/PARALLEL_REDO_LOG_CACHE
N'PARALLEL_REDO_TRAN_LIST', -- https://www.sqlskills.com/help/waits/PARALLEL_REDO_TRAN_LIST
N'PARALLEL_REDO_WORKER_SYNC', -- https://www.sqlskills.com/help/waits/PARALLEL_REDO_WORKER_SYNC
N'PARALLEL_REDO_WORKER_WAIT_WORK', -- https://www.sqlskills.com/help/waits/PARALLEL_REDO_WORKER_WAIT_WORK
N'PREEMPTIVE_XE_GETTARGETSTATE', -- https://www.sqlskills.com/help/waits/PREEMPTIVE_XE_GETTARGETSTATE
N'PWAIT_ALL_COMPONENTS_INITIALIZED', -- https://www.sqlskills.com/help/waits/PWAIT_ALL_COMPONENTS_INITIALIZED
N'PWAIT_DIRECTLOGCONSUMER_GETNEXT', -- https://www.sqlskills.com/help/waits/PWAIT_DIRECTLOGCONSUMER_GETNEXT
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP', -- https://www.sqlskills.com/help/waits/QDS_PERSIST_TASK_MAIN_LOOP_SLEEP
N'QDS_ASYNC_QUEUE', -- https://www.sqlskills.com/help/waits/QDS_ASYNC_QUEUE
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP', -- https://www.sqlskills.com/help/waits/QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP
N'QDS_SHUTDOWN_QUEUE', -- https://www.sqlskills.com/help/waits/QDS_SHUTDOWN_QUEUE
N'REDO_THREAD_PENDING_WORK', -- https://www.sqlskills.com/help/waits/REDO_THREAD_PENDING_WORK
N'REQUEST_FOR_DEADLOCK_SEARCH', -- https://www.sqlskills.com/help/waits/REQUEST_FOR_DEADLOCK_SEARCH
N'RESOURCE_QUEUE', -- https://www.sqlskills.com/help/waits/RESOURCE_QUEUE
N'SERVER_IDLE_CHECK', -- https://www.sqlskills.com/help/waits/SERVER_IDLE_CHECK
N'SLEEP_BPOOL_FLUSH', -- https://www.sqlskills.com/help/waits/SLEEP_BPOOL_FLUSH
N'SLEEP_DBSTARTUP', -- https://www.sqlskills.com/help/waits/SLEEP_DBSTARTUP
N'SLEEP_DCOMSTARTUP', -- https://www.sqlskills.com/help/waits/SLEEP_DCOMSTARTUP
N'SLEEP_MASTERDBREADY', -- https://www.sqlskills.com/help/waits/SLEEP_MASTERDBREADY
N'SLEEP_MASTERMDREADY', -- https://www.sqlskills.com/help/waits/SLEEP_MASTERMDREADY
N'SLEEP_MASTERUPGRADED', -- https://www.sqlskills.com/help/waits/SLEEP_MASTERUPGRADED
N'SLEEP_MSDBSTARTUP', -- https://www.sqlskills.com/help/waits/SLEEP_MSDBSTARTUP
N'SLEEP_SYSTEMTASK', -- https://www.sqlskills.com/help/waits/SLEEP_SYSTEMTASK
N'SLEEP_TASK', -- https://www.sqlskills.com/help/waits/SLEEP_TASK
N'SLEEP_TEMPDBSTARTUP', -- https://www.sqlskills.com/help/waits/SLEEP_TEMPDBSTARTUP
N'SNI_HTTP_ACCEPT', -- https://www.sqlskills.com/help/waits/SNI_HTTP_ACCEPT
N'SP_SERVER_DIAGNOSTICS_SLEEP', -- https://www.sqlskills.com/help/waits/SP_SERVER_DIAGNOSTICS_SLEEP
N'SQLTRACE_BUFFER_FLUSH', -- https://www.sqlskills.com/help/waits/SQLTRACE_BUFFER_FLUSH
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP', -- https://www.sqlskills.com/help/waits/SQLTRACE_INCREMENTAL_FLUSH_SLEEP
N'SQLTRACE_WAIT_ENTRIES', -- https://www.sqlskills.com/help/waits/SQLTRACE_WAIT_ENTRIES
N'WAIT_FOR_RESULTS', -- https://www.sqlskills.com/help/waits/WAIT_FOR_RESULTS
N'WAITFOR', -- https://www.sqlskills.com/help/waits/WAITFOR
N'WAITFOR_TASKSHUTDOWN', -- https://www.sqlskills.com/help/waits/WAITFOR_TASKSHUTDOWN
N'WAIT_XTP_RECOVERY', -- https://www.sqlskills.com/help/waits/WAIT_XTP_RECOVERY
N'WAIT_XTP_HOST_WAIT', -- https://www.sqlskills.com/help/waits/WAIT_XTP_HOST_WAIT
N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG', -- https://www.sqlskills.com/help/waits/WAIT_XTP_OFFLINE_CKPT_NEW_LOG
N'WAIT_XTP_CKPT_CLOSE', -- https://www.sqlskills.com/help/waits/WAIT_XTP_CKPT_CLOSE
N'XE_DISPATCHER_JOIN', -- https://www.sqlskills.com/help/waits/XE_DISPATCHER_JOIN
N'XE_DISPATCHER_WAIT', -- https://www.sqlskills.com/help/waits/XE_DISPATCHER_WAIT
N'XE_TIMER_EVENT' -- https://www.sqlskills.com/help/waits/XE_TIMER_EVENT
)
AND [waiting_tasks_count] > 0 )
SELECT
MAX([W1].[wait_type]) AS [WaitType],
CAST(MAX([W1].[WaitS]) AS DECIMAL(16, 2)) AS [Wait_S],
CAST(MAX([W1].[ResourceS]) AS DECIMAL(16, 2)) AS [Resource_S],
CAST(MAX([W1].[SignalS]) AS DECIMAL(16, 2)) AS [Signal_S],
MAX([W1].[WaitCount]) AS [WaitCount],
CAST(MAX([W1].[Percentage]) AS DECIMAL(5, 2)) AS [Percentage],
CAST(( MAX([W1].[WaitS]) / MAX([W1].[WaitCount])) AS DECIMAL(16, 4)) AS [AvgWait_S],
CAST(( MAX([W1].[ResourceS]) / MAX([W1].[WaitCount])) AS DECIMAL(16, 4)) AS [AvgRes_S],
CAST(( MAX([W1].[SignalS]) / MAX([W1].[WaitCount])) AS DECIMAL(16, 4)) AS [AvgSig_S],
CAST('https://www.sqlskills.com/help/waits/' + MAX([W1].[wait_type]) AS XML) AS [Help/Info URL]
FROM
[Waits] AS [W1]
INNER JOIN [Waits] AS [W2] ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY
[W1].[RowNum]
HAVING
SUM([W2].[Percentage]) - MAX([W1].[Percentage]) < 95; -- percentage threshold
GO
Resultado: (mucho más “limpio”, ¿verdad?”
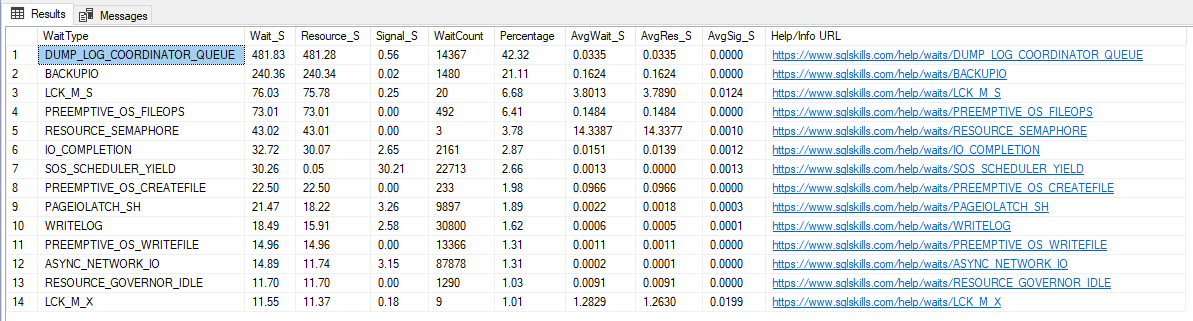
Para hacerle la vida más fácil, a continuación enumeraré algunos eventos comunes y sus posibles causas:
- ASYNC_NETWORK_IO/NETWORKIO: Los eventos wait networkio (SQL 2000) y async_network_io (SQL 2005+) pueden indicar problemas relacionados con la red (raramente), pero a menudo pueden indicar que una aplicación cliente no está procesando los resultados de SQL Server con la suficiente rapidez. Este evento suele aparecer en casos RBAR (Fila por fila agonizante).
- PAQUETE CX: Evento generalmente vinculado a la ejecución de consultas mediante procesamiento paralelo, puede indicar que un hilo ya completó su procesamiento y está esperando que los otros hilos del proceso completen la ejecución. Si este evento tiene un tiempo de espera muy alto, puede ser interesante revisar la configuración del evento. MAXDOP, evalúe si la sugerencia OPCIÓN(MAXDOP x) puede ser útil en algunas consultas, reevalúe los índices utilizados por las consultas que consumen la mayor cantidad de disco (probablemente aquellas que usan paralelismo) e intente asegurarse de que se estén utilizando argumentos sargables.
- DTC: Este evento de espera no es local. Cuando se utiliza el Coordinador de transacciones distribuidas de Microsoft (MS-DTC), se abre una transacción en varios sistemas al mismo tiempo y la transacción solo se completa cuando se ejecuta en todos esos sistemas.
- OLEDB: Este evento de espera indica que el proceso ha realizado una llamada a un proveedor OLEDB y está esperando que ese proceso llame al servidor de destino y devuelva datos. Este evento también se genera cuando ejecutamos comandos en otras instancias usando Servidores Vinculados (llamadas remotas), comandos BULK INSERT y consultas FULLTEXT-SEARCH. No hay nada que hacer en la instancia local, pero en casos de llamadas remotas a otras instancias, puede analizar la instancia de destino e intentar identificar el motivo del retraso en el procesamiento y la devolución de datos.
- PAGEIOLATCH_*: Este evento ocurre cuando SQL Server está esperando leer datos en el disco/almacenamiento de páginas que no están en la memoria, lo que genera contención en el disco. Para reducir este evento de E/S, puede intentar aumentar la velocidad del disco (para reducir este tiempo), agregar más memoria (para asignar más páginas) o intentar identificar y ajustar aquellas consultas que generan este evento de E/S.
Una causa muy común que genera este evento es la falta de índices óptimos para esta consulta en particular, lo cual se puede resolver creando nuevos índices con la ayuda de Missing Index DMV para evitar operaciones de escaneo (Lea el post Comprender cómo funcionan los índices en SQL Server para entender mejor esto).
- PAGELATCH_*: Las causas más comunes de este evento son la contención de tempdb en instancias muy sobrecargadas. La espera PAGELATCH_UP generalmente ocurre cuando varios subprocesos intentan acceder al mismo mapa de bits, mientras que el evento PAGELATCH_EX ocurre cuando los subprocesos intentan insertar datos en la misma página del disco y el evento PAGELATCH_SH indica que algún subproceso está intentando leer datos de una página que se está modificando.
- IO_COMPLECIÓN: Este evento de espera ocurre cuando SQL Server está esperando que las operaciones de E/S completen el procesamiento, que no son lecturas de índices o datos en el disco, sino lecturas de asignaciones de mapas de bits del disco (GAM, SGAM, PFS), registro de transacciones, escritura de búferes de clasificación en el disco, lectura de encabezados VLF del registro de transacciones, lectura/escritura de unión de fusión/spools ansiosos en el disco, etc.
Es normal que ocurra este evento, ya que generalmente aparece justo antes de iniciar una operación que requiere E/S, pero puede ser un problema si el tiempo de espera es muy alto y su lista de esperas más grandes incluye ASYNC_IO_COMPLETION, LOGMGR, WRITELOG o PAGEIOLATCH_*.
Cuando hay un problema de E/S en la instancia, el registro de SQL Server generalmente muestra mensajes que dicen "Las solicitudes de E/S están tardando más de lo esperado".
Para solucionar este problema, busque consultas que tengan tiempos de lectura/escritura de disco muy altos, incluidos los contadores promedio de disco. tiempo de lectura, promedio de disco. tiempo de escritura, promedio longitud de la cola del disco, proporción de aciertos de la caché del búfer, páginas libres del búfer, esperanza de vida de la página del búfer y máquina: memoria utilizada
- SOS_SCHEDULER_YIELD: Este evento ocurre cuando SqlOS (SOS) está esperando a que terminen de procesarse más recursos de CPU, lo que puede indicar que el servidor está experimentando una sobrecarga de CPU y no puede procesar todas las tareas solicitadas. Sin embargo, esto no siempre indica que se trate de un problema general con la instancia, ya que puede indicar que una consulta específica requiere más CPU.
Si su consulta tiene algunos inhibidores de paralelismo (Ej.: HINT MAXDOP(1), funciones UDF en serie, consultas de tablas del sistema, etc.), puede hacer que el procesamiento se realice usando solo 1 núcleo de CPU, lo que significa que se puede generar el evento SOS_SCHEDULER_YIELD, incluso si el servidor tiene varios núcleos disponibles para procesar y con un bajo uso de CPU en la instancia.
Para intentar identificar esto, intente encontrar las consultas que consumen más CPU y/o cuyo tiempo de CPU es menor que el tiempo de ejecución (cuando se produce paralelismo, a veces la consulta consume decenas de CPU y se ejecuta en 2 segundos, lo que significa que se ha paralelizado en varios núcleos de CPU).
- ESCRIBIR REGISTRO: Cuando una transacción está esperando el evento WRITELOG, esto significa que está esperando que SQL Server capture datos del caché de registro y los escriba en el disco (en el registro de transacciones). Como esta operación implica escribir en el disco, que generalmente es una operación mucho más lenta que el acceso a la memoria o el procesamiento de la CPU, este tipo de evento puede ser bastante común en instancias que no tienen un disco muy rápido. Si encuentra este evento con frecuencia, una alternativa para reducir esta espera es utilizar la función Durabilidad retrasada, disponible a partir de SQL Server 2014
- LCK*: Un evento muy común que no está directamente relacionado con el rendimiento, este evento ocurre cuando una transacción está alterando un objeto y coloca un bloqueo en ese objeto, para evitar que cualquier otra transacción pueda modificar o acceder a los datos mientras se está procesando. Por lo tanto, si otra transacción intenta acceder a este objeto, tendrá que esperar a que se elimine este bloqueo para continuar con el procesamiento, generando precisamente este evento de espera. Esto muchas veces se confunde con un problema de rendimiento, porque en realidad la consulta tardará el tiempo necesario hasta que se libere el bloqueo y pueda procesar sus datos, provocando que el usuario tenga una sensación de lentitud en el entorno, especialmente si es una consulta muy utilizada en el sistema. En este caso conviene analizar la sesión que está generando el bloqueo para valorar por qué tarda tanto en procesar y liberar el objeto.
Para profundizar en el análisis de los eventos de espera, recomiendo leer los posts a continuación:
– https://www.sqlskills.com/help/sql-server-performance-tuning-using-wait-statistics/
– https://www.sqlskills.com/blogs/erin/the-accidental-dba-day-25-of-30-wait-statistics-analysis/
– Espera estadísticas, o por favor dime dónde te duele.
– Lista de tipos de espera comunes
– Uso de estadísticas de espera para descubrir por qué SQL Server es lento
– ¿Cuál es el tipo de espera más preocupante?
Cómo identificar consultas de larga duración utilizando Extended Event (XE)
Ver contenido
De esta forma, junto con el análisis de eventos de espera, podremos comenzar el trabajo de identificación de posibles atacantes al consumo de CPU, Disco o tiempo de ejecución.
Cómo identificar consultas de larga duración utilizando Trace
Ver contenido
De esta forma, junto con el análisis de eventos de espera, podremos comenzar el trabajo de identificación de posibles atacantes al consumo de CPU, Disco o tiempo de ejecución.
Cómo identificar consultas ad hoc "pesadas" con el DMV
Ver contenidoUtilizando las estadísticas de la base de datos y DMV sys.dm_exec_query_stats, podemos consultar las consultas que se ejecutaron en la instancia y aplicar los filtros y ordenamiento de tiempo de ejecución, disco y CPU, permitiéndonos identificar el número de veces que se ejecutó esta consulta, el tiempo promedio de ejecución y el tiempo de la última ejecución, además de informar la consulta completa (texto) que se está ejecutando y también la sección específica de este objeto/consulta (TSQL) de estas estadísticas recolectadas y también el plan de ejecución de esta. consulta.
Consulta utilizada (Ordenación por tiempo de ejecución):
SELECT TOP 100
DB_NAME(C.[dbid]) as [database],
B.[text],
(SELECT CAST(SUBSTRING(B.[text], (A.statement_start_offset/2)+1,
(((CASE A.statement_end_offset
WHEN -1 THEN DATALENGTH(B.[text])
ELSE A.statement_end_offset
END) - A.statement_start_offset)/2) + 1) AS NVARCHAR(MAX)) FOR XML PATH(''), TYPE) AS [TSQL],
C.query_plan,
A.last_execution_time,
A.execution_count,
A.total_elapsed_time / 1000 AS total_elapsed_time_ms,
A.last_elapsed_time / 1000 AS last_elapsed_time_ms,
A.min_elapsed_time / 1000 AS min_elapsed_time_ms,
A.max_elapsed_time / 1000 AS max_elapsed_time_ms,
((A.total_elapsed_time / A.execution_count) / 1000) AS avg_elapsed_time_ms,
A.total_worker_time / 1000 AS total_worker_time_ms,
A.last_worker_time / 1000 AS last_worker_time_ms,
A.min_worker_time / 1000 AS min_worker_time_ms,
A.max_worker_time / 1000 AS max_worker_time_ms,
((A.total_worker_time / A.execution_count) / 1000) AS avg_worker_time_ms,
A.total_physical_reads,
A.last_physical_reads,
A.min_physical_reads,
A.max_physical_reads,
A.total_logical_reads,
A.last_logical_reads,
A.min_logical_reads,
A.max_logical_reads,
A.total_logical_writes,
A.last_logical_writes,
A.min_logical_writes,
A.max_logical_writes
FROM
sys.dm_exec_query_stats A
CROSS APPLY sys.dm_exec_sql_text(A.[sql_handle]) B
OUTER APPLY sys.dm_exec_query_plan (A.plan_handle) AS C
ORDER BY
A.total_elapsed_time DESC
Resultado:
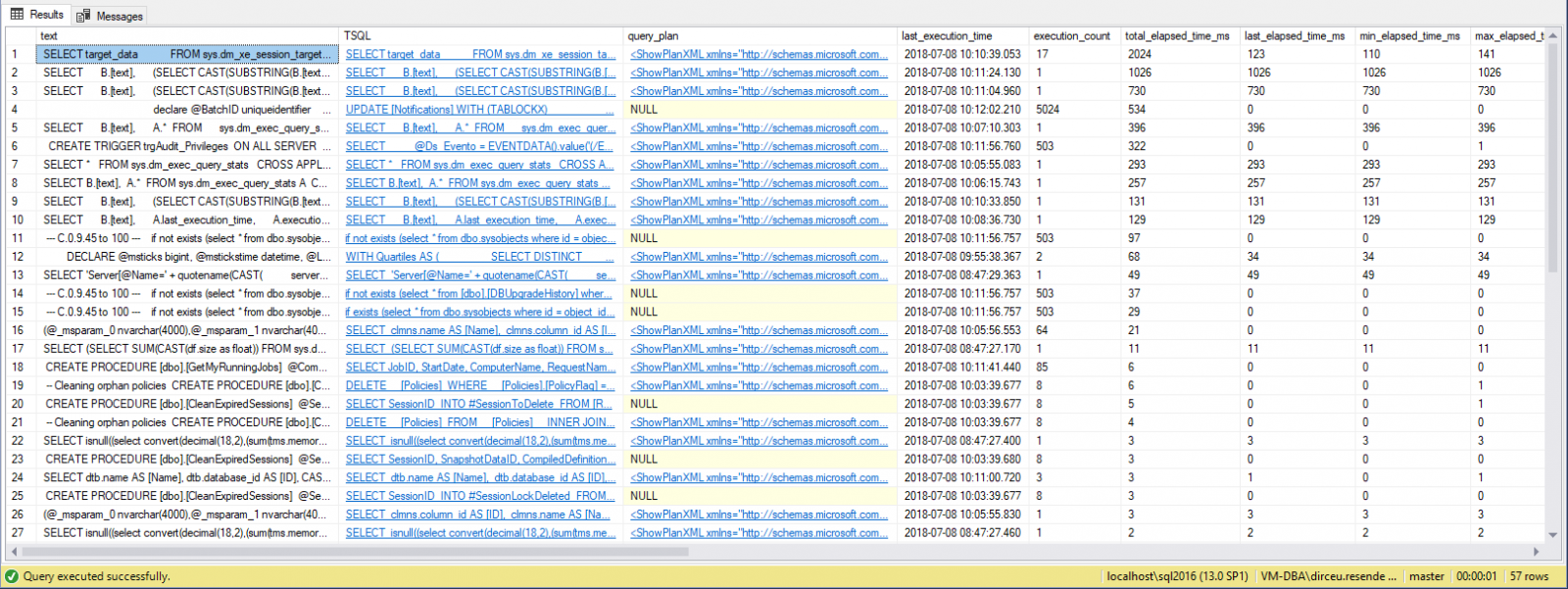
Como puedes ver, en el ejemplo anterior filtré los datos para devolver las consultas que tardan más en ejecutarse, pero puedes ordenar por la columna que quieras, pudiendo refinar tu consulta según tu entorno y necesidades, junto con el análisis de eventos de espera.
Vale recordar que, al estar consultando datos de estadísticas bancarias, si se reinicia el servicio estos datos se perderán. Por esta razón, te sugiero crear una rutina que recopile estos datos cada cierto tiempo y los almacene en una tabla física, así cuando esto suceda, puedas continuar tu análisis donde lo dejaste y no tengas que esperar horas o días para tener datos para seguir analizando.
Procedimiento almacenado para almacenar consultas Ad-hoc de todas las bases de datos:
USE [dirceuresende]
GO
CREATE PROCEDURE [dbo].[stpCarga_Historico_Execucao_Consultas]
AS BEGIN
IF (OBJECT_ID('dirceuresende.dbo.Historico_Execucao_Consultas') IS NULL)
BEGIN
-- DROP TABLE dirceuresende.dbo.Historico_Execucao_Consultas
CREATE TABLE dirceuresende.dbo.Historico_Execucao_Consultas
(
Id_Coleta BIGINT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED,
Dt_Coleta datetime NOT NULL,
[database] sys.sysname NOT NULL,
[text] NVARCHAR(MAX) NULL,
[TSQL] XML NULL,
[query_plan] XML NULL,
last_execution_time datetime NULL,
execution_count bigint NOT NULL,
total_elapsed_time_ms bigint NULL,
last_elapsed_time_ms bigint NULL,
min_elapsed_time_ms bigint NULL,
max_elapsed_time_ms bigint NULL,
avg_elapsed_time_ms bigint NULL,
total_worker_time_ms bigint NULL,
last_worker_time_ms bigint NULL,
min_worker_time_ms bigint NULL,
max_worker_time_ms bigint NULL,
avg_worker_time_ms bigint NULL,
total_physical_reads bigint NOT NULL,
last_physical_reads bigint NOT NULL,
min_physical_reads bigint NOT NULL,
max_physical_reads bigint NOT NULL,
total_logical_reads bigint NOT NULL,
last_logical_reads bigint NOT NULL,
min_logical_reads bigint NOT NULL,
max_logical_reads bigint NOT NULL,
total_logical_writes bigint NOT NULL,
last_logical_writes bigint NOT NULL,
min_logical_writes bigint NOT NULL,
max_logical_writes bigint NOT NULL
) WITH(DATA_COMPRESSION=PAGE)
CREATE INDEX SK01_Historico_Execucao_Consultas ON dirceuresende.dbo.Historico_Execucao_Consultas(Dt_Coleta, [database])
END
DECLARE
@Dt_Referencia DATETIME = GETDATE(),
@Query VARCHAR(MAX)
SET @Query = '
IF (''?'' NOT IN (''master'', ''model'', ''msdb'', ''tempdb''))
BEGIN
INSERT INTO dirceuresende.dbo.Historico_Execucao_Consultas
SELECT
''' + CONVERT(VARCHAR(19), @Dt_Referencia, 120) + ''' AS Dt_Coleta,
''?'' AS [database],
B.[text],
(SELECT CAST(SUBSTRING(B.[text], (A.statement_start_offset/2)+1, (((CASE A.statement_end_offset WHEN -1 THEN DATALENGTH(B.[text]) ELSE A.statement_end_offset END) - A.statement_start_offset)/2) + 1) AS NVARCHAR(MAX)) FOR XML PATH(''''),TYPE) AS [TSQL],
C.query_plan,
A.last_execution_time,
A.execution_count,
A.total_elapsed_time / 1000 AS total_elapsed_time_ms,
A.last_elapsed_time / 1000 AS last_elapsed_time_ms,
A.min_elapsed_time / 1000 AS min_elapsed_time_ms,
A.max_elapsed_time / 1000 AS max_elapsed_time_ms,
((A.total_elapsed_time / A.execution_count) / 1000) AS avg_elapsed_time_ms,
A.total_worker_time / 1000 AS total_worker_time_ms,
A.last_worker_time / 1000 AS last_worker_time_ms,
A.min_worker_time / 1000 AS min_worker_time_ms,
A.max_worker_time / 1000 AS max_worker_time_ms,
((A.total_worker_time / A.execution_count) / 1000) AS avg_worker_time_ms,
A.total_physical_reads,
A.last_physical_reads,
A.min_physical_reads,
A.max_physical_reads,
A.total_logical_reads,
A.last_logical_reads,
A.min_logical_reads,
A.max_logical_reads,
A.total_logical_writes,
A.last_logical_writes,
A.min_logical_writes,
A.max_logical_writes
FROM
[?].sys.dm_exec_query_stats A
CROSS APPLY [?].sys.dm_exec_sql_text(A.[sql_handle]) B
OUTER APPLY [?].sys.dm_exec_query_plan (A.plan_handle) AS C
END'
EXEC master.dbo.sp_MSforeachdb
@command1 = @Query
END
GO
Cómo identificar procedimientos “pesados” con el DMV
Ver contenidoConsulta utilizada (Ordenación por número de ejecuciones):
SELECT TOP 100
B.[name] AS rotina,
A.cached_time,
A.last_execution_time,
A.execution_count,
A.total_elapsed_time / 1000 AS total_elapsed_time_ms,
A.last_elapsed_time / 1000 AS last_elapsed_time_ms,
A.min_elapsed_time / 1000 AS min_elapsed_time_ms,
A.max_elapsed_time / 1000 AS max_elapsed_time_ms,
((A.total_elapsed_time / A.execution_count) / 1000) AS avg_elapsed_time_ms,
A.total_worker_time / 1000 AS total_worker_time_ms,
A.last_worker_time / 1000 AS last_worker_time_ms,
A.min_worker_time / 1000 AS min_worker_time_ms,
A.max_worker_time / 1000 AS max_worker_time_ms,
((A.total_worker_time / A.execution_count) / 1000) AS avg_worker_time_ms,
A.total_physical_reads,
A.last_physical_reads,
A.min_physical_reads,
A.max_physical_reads,
A.total_logical_reads,
A.last_logical_reads,
A.min_logical_reads,
A.max_logical_reads,
A.total_logical_writes,
A.last_logical_writes,
A.min_logical_writes,
A.max_logical_writes
FROM
sys.dm_exec_procedure_stats A
JOIN sys.objects B ON A.[object_id] = B.[object_id]
ORDER BY
A.execution_count DESC
Resultado:

Vale recordar que, al estar consultando datos de estadísticas bancarias, si se reinicia el servicio estos datos se perderán. Por esta razón, te sugiero crear una rutina que recopile estos datos cada cierto tiempo y los almacene en una tabla física, así cuando esto suceda, puedas continuar tu análisis donde lo dejaste y no tengas que esperar horas o días para tener datos para seguir analizando. Si el objeto se cambia o se vuelve a compilar, se generará un nuevo plan de ejecución para él y los datos en esta vista se restablecerán, lo que refuerza la necesidad de tener este historial para identificar el efecto de estos cambios de plan.
Procedimiento almacenado para almacenar estadísticas de SP de todas las bases de datos:
USE [dirceuresende]
GO
CREATE PROCEDURE [dbo].[stpCarga_Historico_Execucao_Procedures]
AS BEGIN
IF (OBJECT_ID('dirceuresende.dbo.Historico_Execucao_Procedures') IS NULL)
BEGIN
-- DROP TABLE dirceuresende.dbo.Historico_Execucao_Procedures
CREATE TABLE dirceuresende.dbo.Historico_Execucao_Procedures (
Id_Coleta BIGINT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED,
Dt_Coleta datetime NOT NULL,
[database] sys.sysname NOT NULL,
rotina sys.sysname NOT NULL,
cached_time datetime NULL,
last_execution_time datetime NULL,
execution_count bigint NOT NULL,
total_elapsed_time_ms bigint NULL,
last_elapsed_time_ms bigint NULL,
min_elapsed_time_ms bigint NULL,
max_elapsed_time_ms bigint NULL,
avg_elapsed_time_ms bigint NULL,
total_worker_time_ms bigint NULL,
last_worker_time_ms bigint NULL,
min_worker_time_ms bigint NULL,
max_worker_time_ms bigint NULL,
avg_worker_time_ms bigint NULL,
total_physical_reads bigint NOT NULL,
last_physical_reads bigint NOT NULL,
min_physical_reads bigint NOT NULL,
max_physical_reads bigint NOT NULL,
total_logical_reads bigint NOT NULL,
last_logical_reads bigint NOT NULL,
min_logical_reads bigint NOT NULL,
max_logical_reads bigint NOT NULL,
total_logical_writes bigint NOT NULL,
last_logical_writes bigint NOT NULL,
min_logical_writes bigint NOT NULL,
max_logical_writes bigint NOT NULL
) WITH(DATA_COMPRESSION = PAGE)
CREATE INDEX SK01_Historico_Execucao_Procedures ON dirceuresende.dbo.Historico_Execucao_Procedures(Dt_Coleta, [database], rotina)
END
DECLARE
@Dt_Referencia DATETIME = GETDATE(),
@Query VARCHAR(MAX)
SET @Query = '
INSERT INTO dirceuresende.dbo.Historico_Execucao_Procedures
SELECT
''' + CONVERT(VARCHAR(19), @Dt_Referencia, 120) + ''' AS Dt_Coleta,
''?'' AS [database],
B.name AS rotina,
A.cached_time,
A.last_execution_time,
A.execution_count,
A.total_elapsed_time / 1000 AS total_elapsed_time_ms,
A.last_elapsed_time / 1000 AS last_elapsed_time_ms,
A.min_elapsed_time / 1000 AS min_elapsed_time_ms,
A.max_elapsed_time / 1000 AS max_elapsed_time_ms,
((A.total_elapsed_time / A.execution_count) / 1000) AS avg_elapsed_time_ms,
A.total_worker_time / 1000 AS total_worker_time_ms,
A.last_worker_time / 1000 AS last_worker_time_ms,
A.min_worker_time / 1000 AS min_worker_time_ms,
A.max_worker_time / 1000 AS max_worker_time_ms,
((A.total_worker_time / A.execution_count) / 1000) AS avg_worker_time_ms,
A.total_physical_reads,
A.last_physical_reads,
A.min_physical_reads,
A.max_physical_reads,
A.total_logical_reads,
A.last_logical_reads,
A.min_logical_reads,
A.max_logical_reads,
A.total_logical_writes,
A.last_logical_writes,
A.min_logical_writes,
A.max_logical_writes
FROM
[?].sys.dm_exec_procedure_stats A WITH(NOLOCK)
JOIN [?].sys.objects B WITH(NOLOCK) ON A.object_id = B.object_id'
EXEC master.dbo.sp_MSforeachdb
@command1 = @Query
END
GO
Cómo identificar consultas "pesadas" con WhoIsActive
Ver contenidoUsando este SP, podemos monitorear las consultas que se ejecutan en la instancia y evaluar cuáles consumen más CPU, Disco, Memoria y también monitorear los eventos de espera para cada consulta y si alguna sesión está causando bloqueos en la instancia:

Por esta razón, me parece muy interesante tener una rutina que recopile datos de este Procedimiento Almacenado/Vista cada X minutos y los almacene en una tabla física durante X días, de manera que puedas analizar el pasado en caso de una desaceleración y quieras identificar exactamente qué se estaba ejecutando en un momento dado y cómo fue el consumo de recursos (CPU, disco, memoria, eventos de espera, etc.) de cada consulta de este tipo.
Tener este nivel de información puede resultar muy útil a la hora de investigar problemas de rendimiento (e incluso otros tipos de problemas también).
Cómo identificar consultas "pesadas" con sp_BlitzFirst
Ver contenidosp_BlitzCache, por otro lado, realiza varias comprobaciones de los planes de ejecución almacenados en caché en la instancia y busca situaciones que normalmente conducen a un rendimiento deficiente durante la ejecución, como índices faltantes (Missing index), conversiones implícitas, etc.
Ejemplo de ejecución de sp_BlitzFirst (descripción general de la instancia):
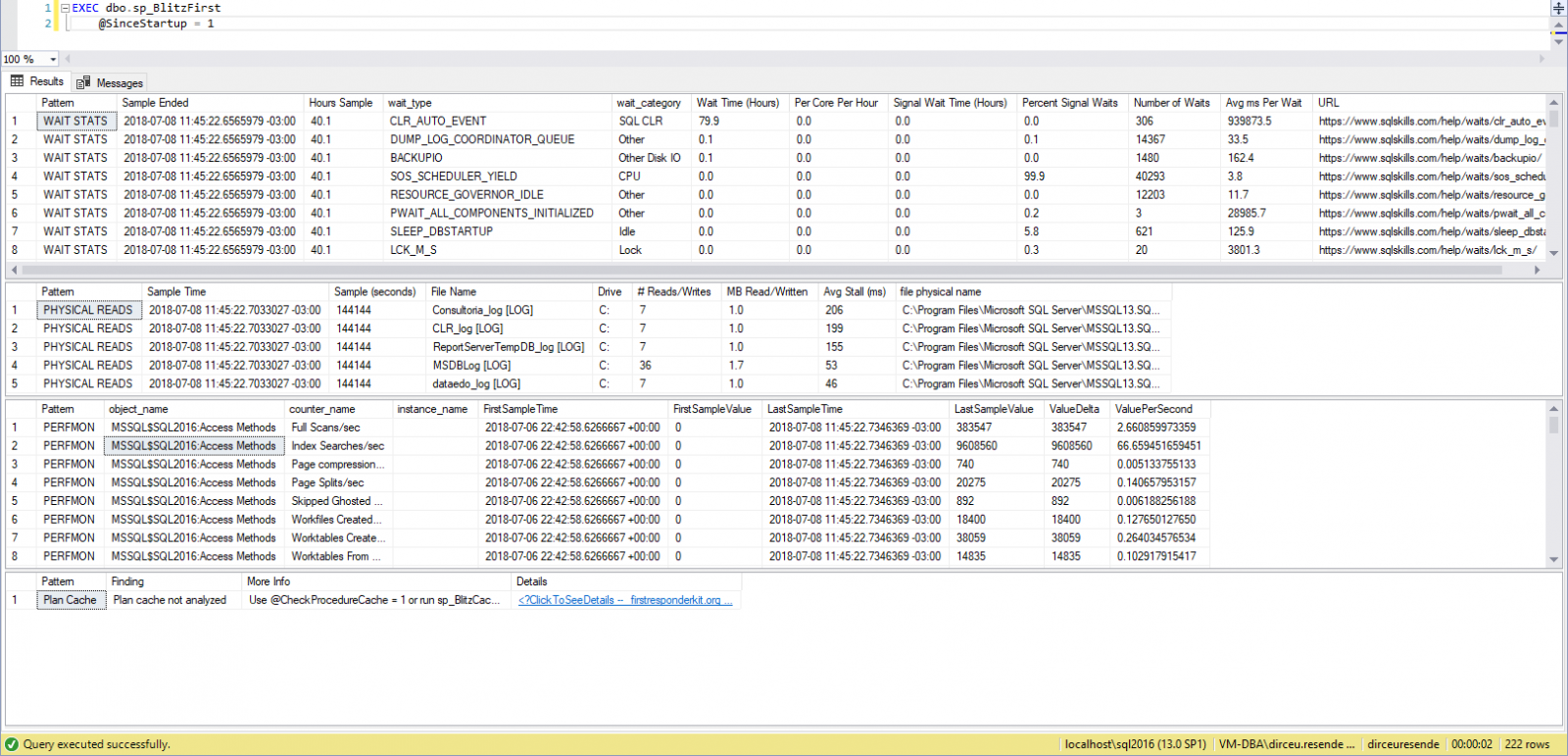
Ejemplo de ejecución de sp_BlitzCache (Analiza planes de ejecución en caché):
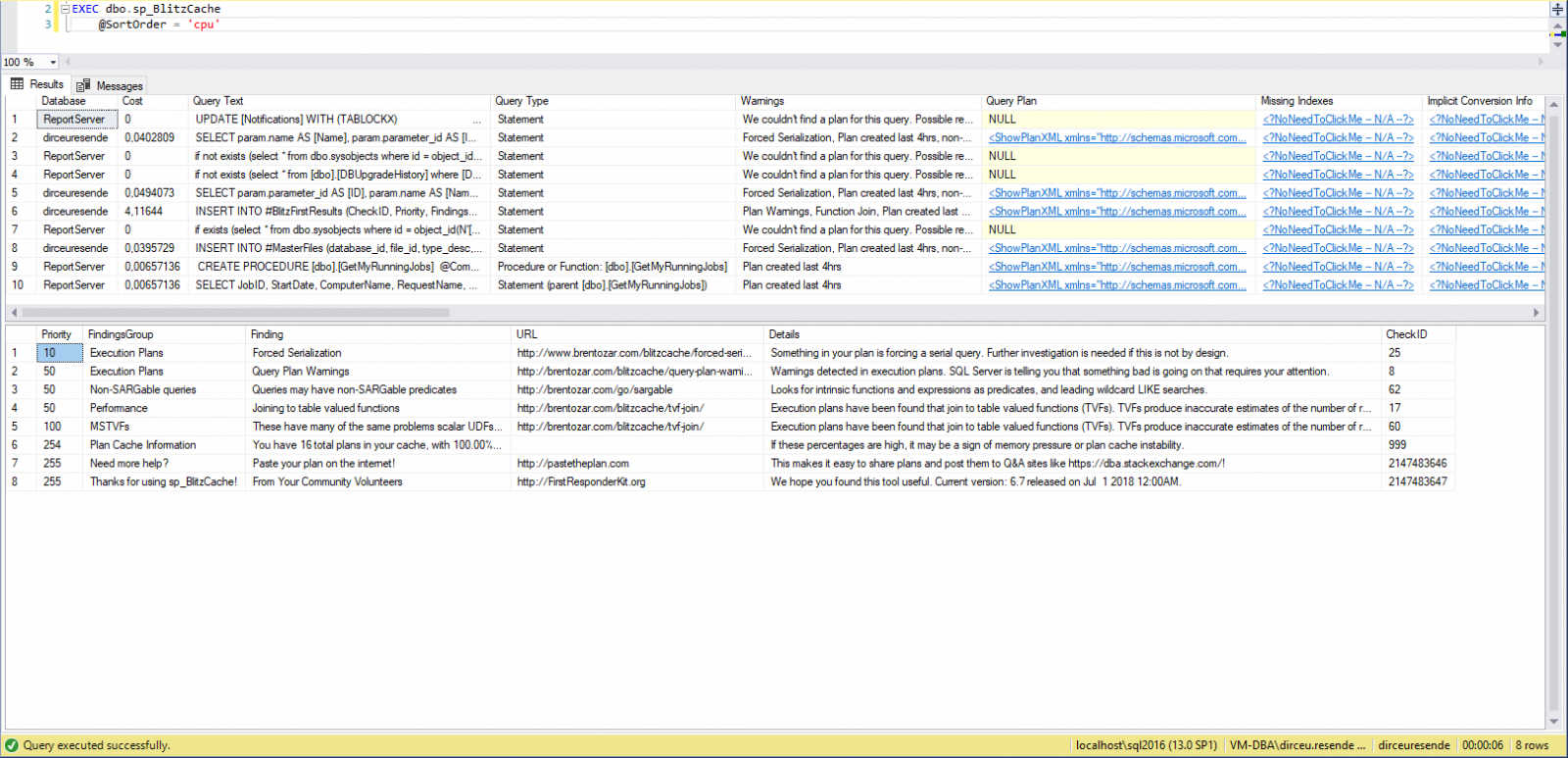
Vea cómo funciona en la práctica:
Descargar SP en este enlace aquí.
Cómo identificar consultas "pesadas" con Management Studio (SSMS)
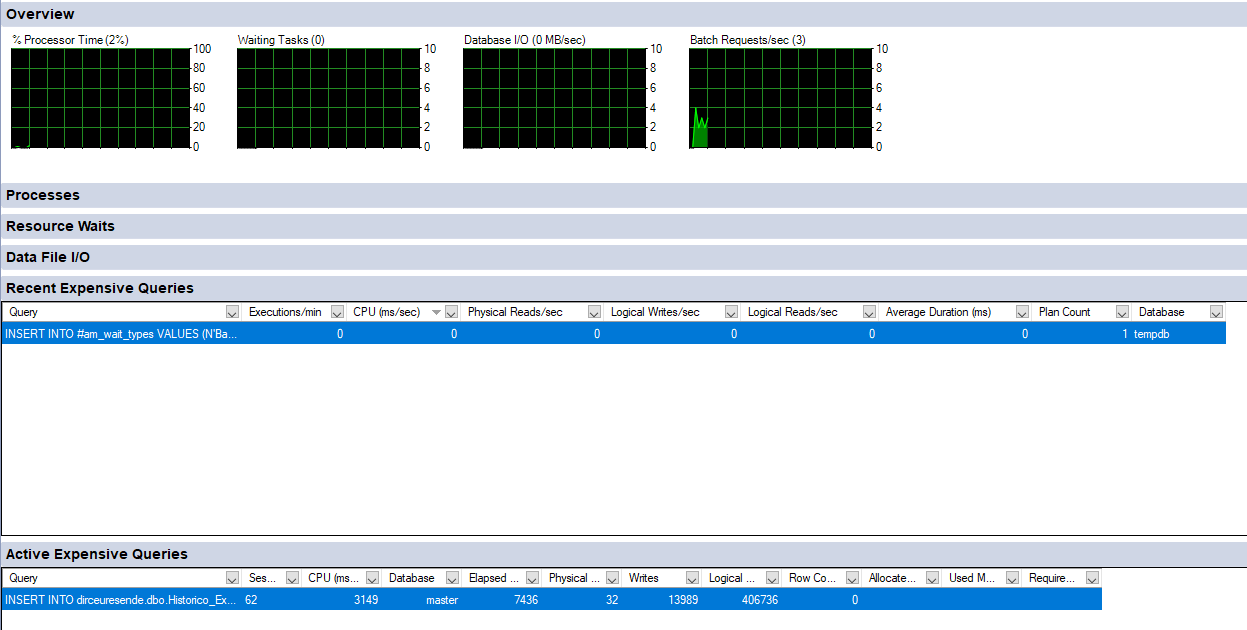
Ver contenido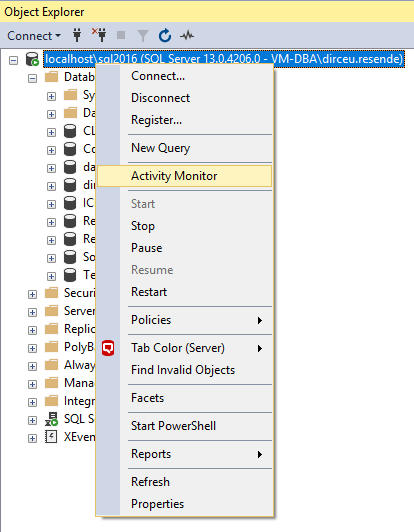
Y analizando sus resultados, donde ya muestra algunas consultas que cree que consumen muchos recursos de instancia:
SSMS también ofrece varios informes listos para usar, que van desde medir el espacio en disco utilizado por cada tabla hasta informes de rendimiento (estadísticas de uso de índice, estadísticas físicas de índice y estadísticas de ejecución de objetos):
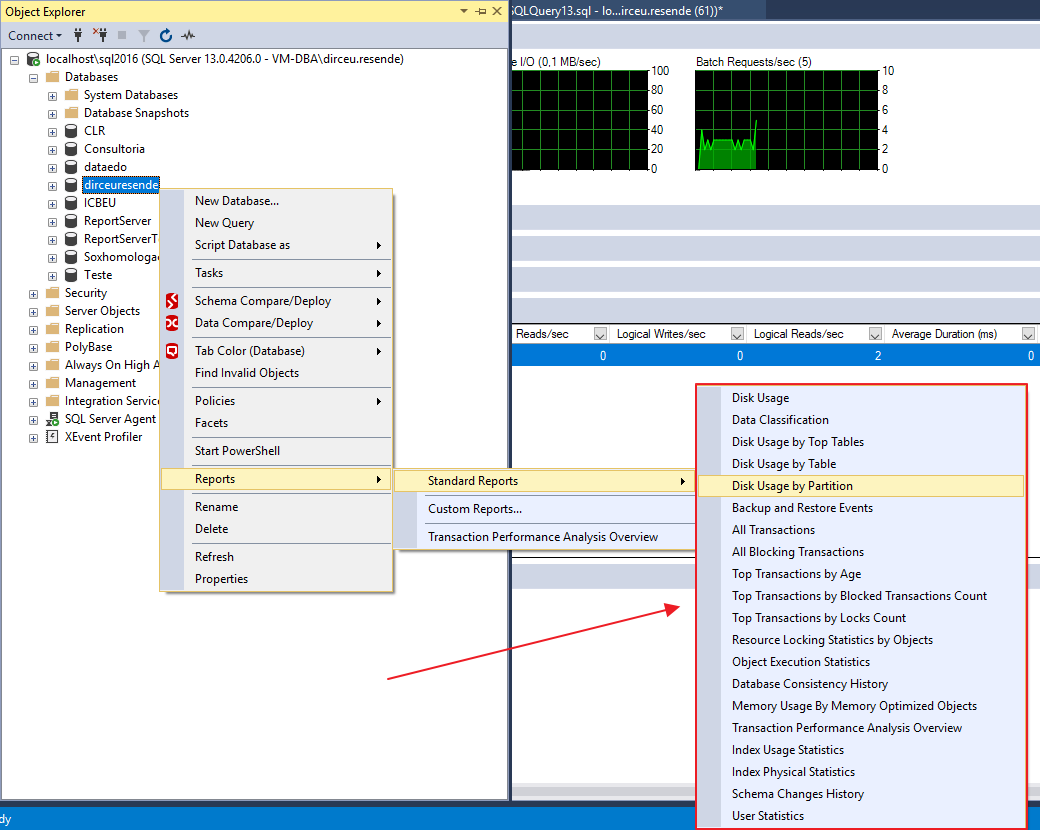
Informe de estadísticas de ejecución de objetos:
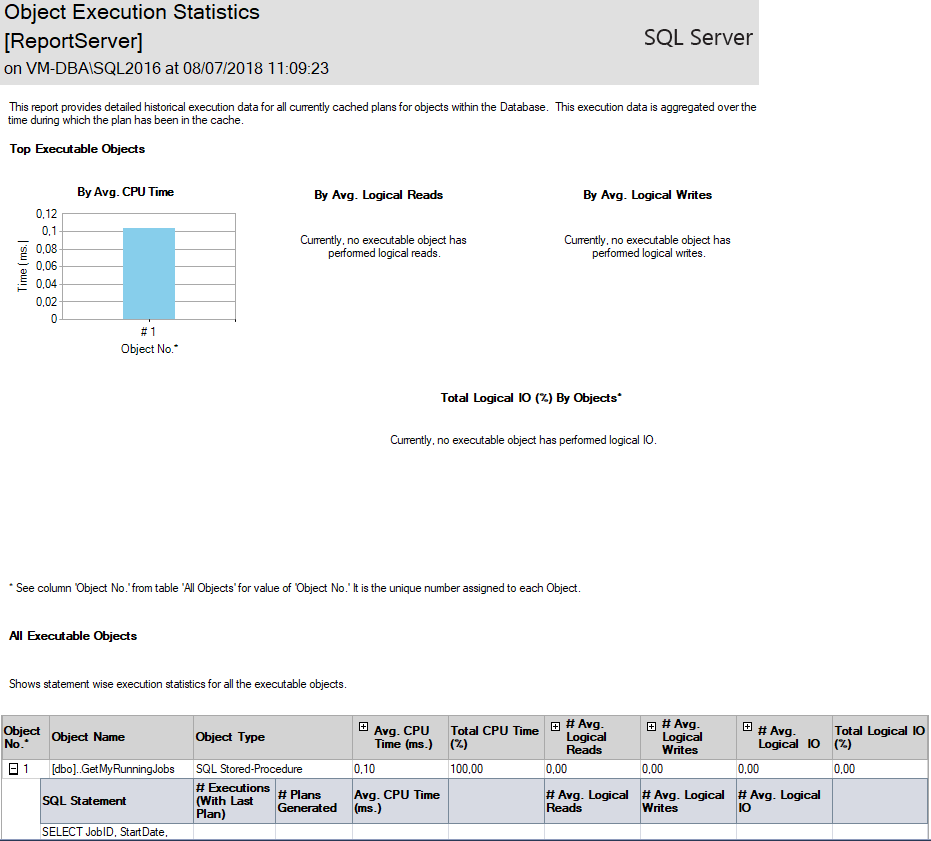
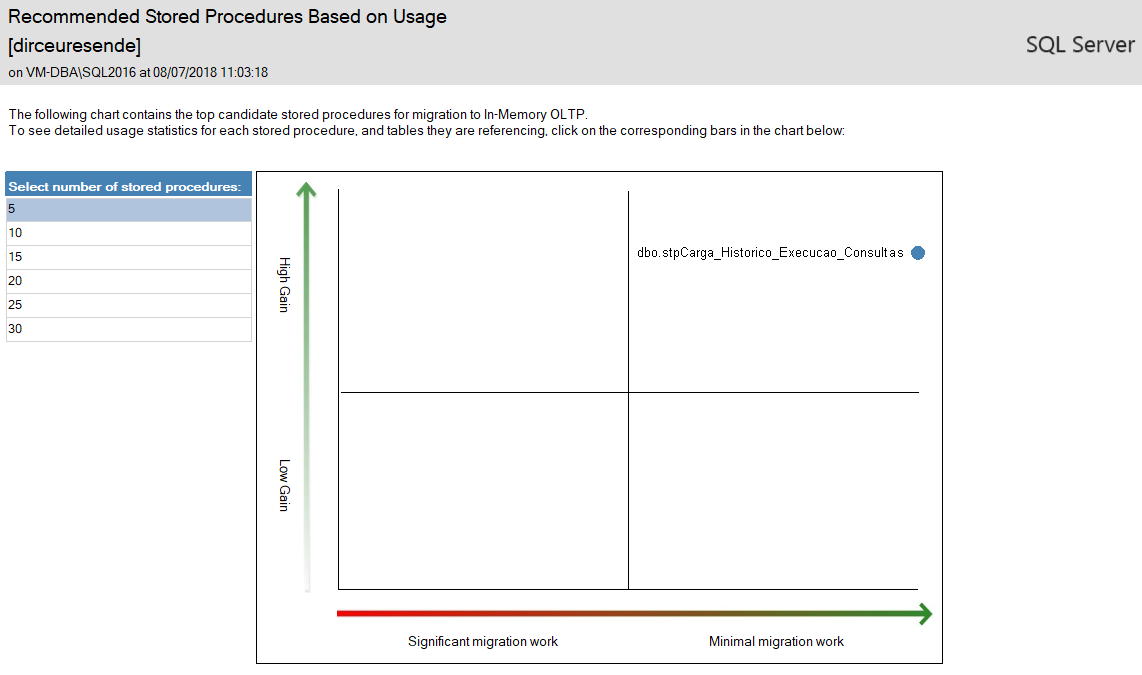
SSMS incluso tiene informes que ayudan a migrar objetos físicos (tablas y procedimientos almacenados) a objetos en memoria (OLTP en memoria), a través del informe “Descripción general del análisis del rendimiento de las transacciones”:
Cómo identificar consultas "pesadas" con Perfmon
Ver contenidoAccediendo a Rendimiento:
Vista gráfica:
Vista textual:
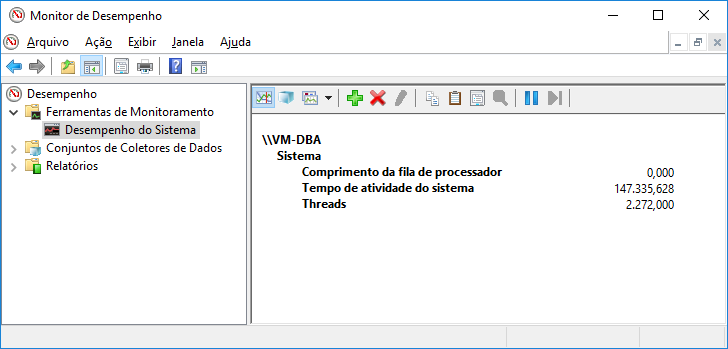
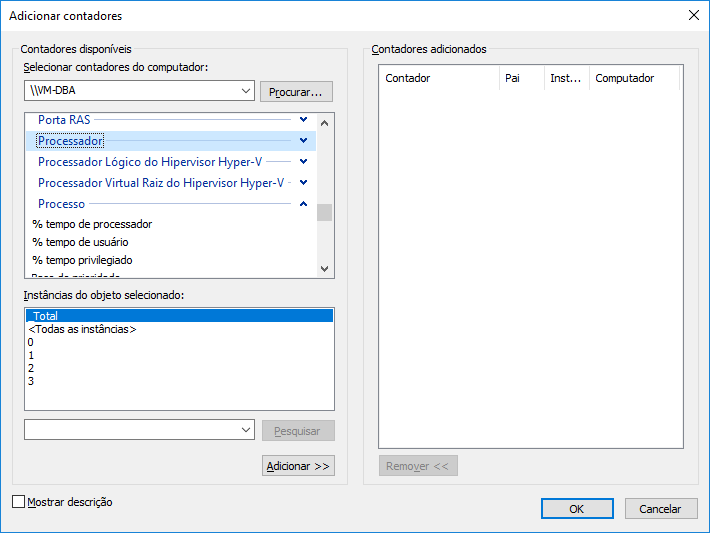
Tipos de contadores:
Vídeo de MVP Osanam Giordane acerca del rendimiento:
en el articulo Contadores de rendimiento, de MCM Fabricio Catae, nos presenta una lista de contadores que se suelen utilizar para monitorear instancias de SQL Server, los cuales son:
Disco lógico
- Promedio de segundos de disco/lectura
- Promedio de segundos/transferencia de disco
- Promedio de segundos/escritura de disco
- Longitud actual de la cola del disco
- Bytes de disco/seg
- Bytes de lectura de disco/seg.
- Bytes de escritura en disco/seg.
- Lecturas de disco/seg.
- Transferencias de disco/seg.
- Escrituras de disco/seg.
memoria
- % de bytes confirmados en uso
- DisponibleMB
- Bytes confirmados
- Entradas gratuitas en la tabla de la página del sistema
- Bytes no paginados del grupo
- Bytes paginados del grupo
Interfaces de red
- Bytes recibidos/seg.
- Bytes enviados/seg
- Bytes totales/seg.
Procesador
- % de tiempo del procesador
- %Tiempo privilegiado
Sistema
- Cambios de contexto/seg.
- Envíos de excepción/seg.
- Longitud de la cola del procesador
- Llamadas al sistema/seg.
Además, utilice estos contadores por instancia de SQL:
Administrador de búfer
- Páginas de base de datos
- Puestos de lista libres/seg.
- paginas gratis
- Escrituras diferidas/seg.
- Esperanza de vida de la página
- Búsquedas de páginas/seg.
- Lecturas de página/seg.
- Páginas de lectura/seg.
- paginas robadas
- Páginas de destino
- Páginas totales
Estadísticas Generales
- Restablecimiento de conexión/seg.
- Inicios de sesión/seg
- Cierres de sesión/seg.
- Conexiones de usuario
Estadísticas SQL
- Solicitudes por lotes/seg.
- Parámetros automáticos seguros/seg.
- Parametrizaciones forzadas/seg
- Compilaciones SQL/seg.
- Recompilaciones de SQL/seg.
Para profundizar en el monitoreo de instancias de SQL Server usando Perfmon, asegúrese de consultar la Publicaciones de rendimiento ninja.
Cómo identificar consultas "pesadas" utilizando software de monitoreo
Ver contenido¡Eso es todo, amigos!
Espero que hayas disfrutado de esta publicación y ¡hasta la próxima!

Comentarios (0)
Cargando comentarios...