¡Hola, chicos!
En este artículo me gustaría compartir con ustedes un guión para Kendal Van Dyke para identificar/encontrar ocurrencias de búsqueda de claves a través del plancache, lo que puede ser muy útil para identificar fácilmente posibles buenos candidatos para un análisis de rendimiento.
Como usted sabe, las ocurrencias de KeyLookup generalmente causan un impacto muy grande en el rendimiento y se pueden corregir fácilmente creando o cambiando índices.
¿Qué es y cómo evitar la búsqueda de claves y la búsqueda de RID?
Como ya expliqué en el artículo. Comprender cómo funcionan los índices en SQL Server, cuando se realiza una consulta sobre una tabla, el optimizador de consultas de SQL Server determinará el mejor método de acceso a los datos de acuerdo con las estadísticas recopiladas y elegirá el de menor costo.
Como el índice agrupado es la tabla en sí y genera un gran volumen de datos, generalmente se utiliza para la consulta el índice no agrupado de menor costo.
Esto puede crear un problema, ya que el índice no agrupado se utilizará a menudo para buscar información indexada (Index Seek NonClustered), pero no todas las columnas solicitadas en la selección forman parte del índice.
Cuando esto suceda, también habrá que utilizar el índice agrupado para devolver la información restante, utilizando el puntero a la posición exacta de la información en el índice agrupado (o el ROWID, si la tabla no tiene un índice agrupado).
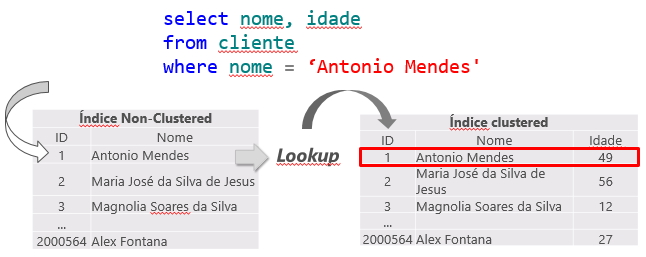
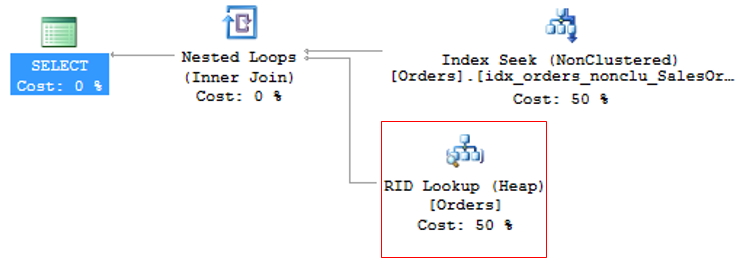
Esta operación se llama Búsqueda de claves, en el caso de tablas con índice agrupado o Búsqueda RID (RID = ID de fila) para tablas que no tienen un índice agrupado (llamadas tablas HEAP) y debido a que genera 2 operaciones de lectura para una sola consulta, se debe evitar siempre que sea posible.
Búsqueda de claves
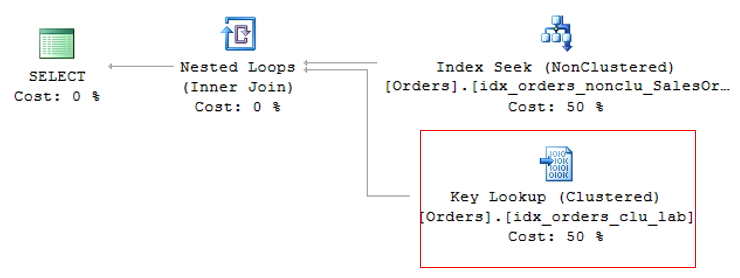
Búsqueda RID
Para evitar KeyLookup, basta con utilizar la técnica del índice de cobertura, que consiste en agregar las columnas principales que se utilizan en las consultas de tablas al índice NonClustered (INCLUDE). Esto significa que el optimizador de consultas puede obtener toda la información leyendo solo el índice elegido, sin tener que leer también el índice agrupado.
Sin embargo, se debe prestar gran atención a la modelización de los índices. No se recomienda agregar todas las columnas de la tabla al índice no agrupado, ya que será tan grande que ya no será efectivo y el optimizador de consultas puede incluso decidir no usarlo y preferir el operador Index Scan, que lee todo el índice secuencialmente, perjudicando el rendimiento de la consulta.
Para evitar la búsqueda RID, simplemente cree el índice agrupado en la tabla y preste atención a los eventos de búsqueda de claves que puedan surgir.
Cómo identificar/encontrar ocurrencias de búsqueda clave a través de plancache
Ahora que comprende qué es una búsqueda de claves y cómo solucionarla, aprendamos cómo identificar estos eventos de forma rápida y sencilla.
Método 1: usar un simple ME GUSTA
Esta consulta a continuación es relativamente simple, simplemente haciendo una consulta en algunos DMV's y una consulta textual usando LIKE en el plan de ejecución para buscar la expresión. Búsqueda = "1" dentro de XML. El resultado suele ser muy preciso, pero pueden aparecer falsos positivos.
SELECT
DB_NAME([detqp].[dbid]),
SUBSTRING([dest].[text], ( [deqs].[statement_start_offset] / 2 ) + 1, ( CASE [deqs].[statement_end_offset] WHEN -1 THEN DATALENGTH([dest].[text])ELSE [deqs].[statement_end_offset] END - [deqs].[statement_start_offset] ) / 2 + 1) AS [StatementText],
CAST([detqp].[query_plan] AS XML),
[deqs].[execution_count],
[deqs].[total_elapsed_time],
[deqs].[total_logical_reads],
[deqs].[total_logical_writes]
FROM
[sys].[dm_exec_query_stats] AS [deqs]
CROSS APPLY [sys].dm_exec_text_query_plan([deqs].[plan_handle], [deqs].[statement_start_offset], [deqs].[statement_end_offset]) AS [detqp]
CROSS APPLY [sys].dm_exec_sql_text([deqs].[sql_handle]) AS [dest]
WHERE
[detqp].[query_plan] LIKE '%Lookup="1"%';Resultado:
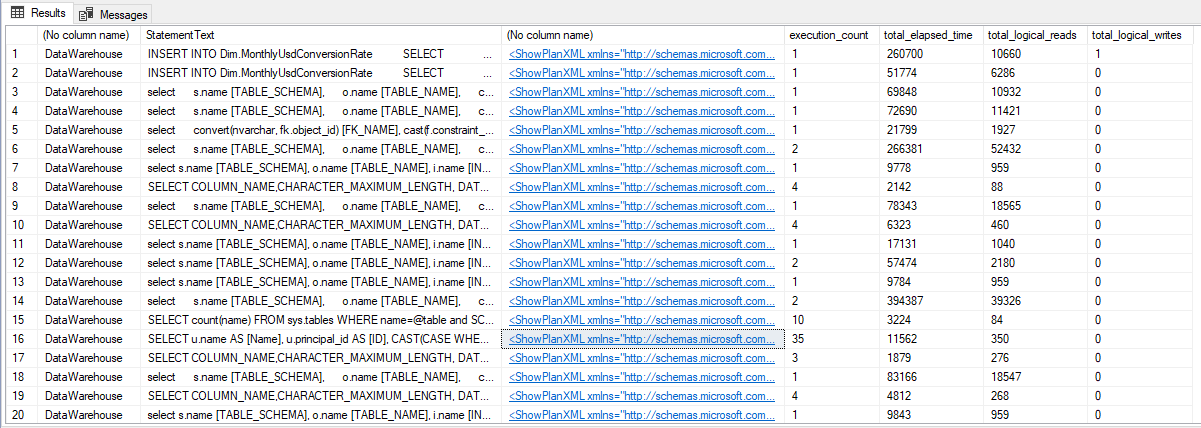
Método 2: usar XPath en el XML del plan de ejecución
Este segundo método es mucho más completo, devuelve más información y utiliza fórmulas XPath para navegar dentro del XML del plan de ejecución y devolver datos de forma más precisa y correcta.
/*********************************************************************************************
Find Key Lookups in Cached Plans v1.00 (2010-07-27)
(C) 2010, Kendal Van Dyke
Feedback: mailto:[email protected]
License:
This query is free to download and use for personal, educational, and internal
corporate purposes, provided that this header is preserved. Redistribution or sale
of this query, in whole or in part, is prohibited without the author's express
written consent.
Note:
Exercise caution when running this in production!
The function sys.dm_exec_query_plan() is resource intensive and can put strain
on a server when used to retrieve all cached query plans.
Consider using TOP in the initial select statement (insert into @plans)
to limit the impact of running this query or run during non-peak hours
*********************************************************************************************/
DECLARE @plans TABLE (
[query_text] NVARCHAR(MAX),
[o_name] sysname,
[execution_plan] XML,
[last_execution_time] DATETIME,
[execution_count] BIGINT,
[total_worker_time] BIGINT,
[total_physical_reads] BIGINT,
[total_logical_reads] BIGINT
);
DECLARE @lookups TABLE (
[table_name] sysname,
[index_name] sysname,
[index_cols] NVARCHAR(MAX)
);
WITH [query_stats]
AS (
SELECT
[sql_handle],
[plan_handle],
MAX([last_execution_time]) AS [last_execution_time],
SUM([execution_count]) AS [execution_count],
SUM([total_worker_time]) AS [total_worker_time],
SUM([total_physical_reads]) AS [total_physical_reads],
SUM([total_logical_reads]) AS [total_logical_reads]
FROM
[sys].[dm_exec_query_stats]
GROUP BY
[sql_handle],
[plan_handle]
)
INSERT INTO @plans (
[query_text],
[o_name],
[execution_plan],
[last_execution_time],
[execution_count],
[total_worker_time],
[total_physical_reads],
[total_logical_reads]
)
SELECT /*TOP 50*/
[sql_text].[text],
CASE
WHEN [sql_text].[objectid] IS NOT NULL THEN ISNULL(OBJECT_NAME([sql_text].[objectid], [sql_text].[dbid]), 'Unresolved')
ELSE CAST('Ad-hoc\Prepared' AS sysname)
END,
[query_plan].[query_plan],
[query_stats].[last_execution_time],
[query_stats].[execution_count],
[query_stats].[total_worker_time],
[query_stats].[total_physical_reads],
[query_stats].[total_logical_reads]
FROM
[query_stats]
CROSS APPLY [sys].dm_exec_sql_text([query_stats].[sql_handle]) AS [sql_text]
CROSS APPLY [sys].dm_exec_query_plan([query_stats].[plan_handle]) AS [query_plan]
WHERE
[query_plan].[query_plan] IS NOT NULL;
;WITH XMLNAMESPACES (
DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan'
),
[lookups]
AS
(
SELECT
DB_ID(REPLACE(REPLACE([keylookups].[keylookup].[value]('(Object/@Database)[1]', 'sysname'), '[', ''), ']', '')) AS [database_id],
OBJECT_ID([keylookups].[keylookup].[value]('(Object/@Database)[1]', 'sysname') + '.' + [keylookups].[keylookup].[value]('(Object/@Schema)[1]', 'sysname') + '.' + [keylookups].[keylookup].[value]('(Object/@Table)[1]', 'sysname')) AS [object_id],
[keylookups].[keylookup].[value]('(Object/@Database)[1]', 'sysname') AS [database],
[keylookups].[keylookup].[value]('(Object/@Schema)[1]', 'sysname') AS [schema],
[keylookups].[keylookup].[value]('(Object/@Table)[1]', 'sysname') AS [table],
[keylookups].[keylookup].[value]('(Object/@Index)[1]', 'sysname') AS [index],
REPLACE([keylookups].[keylookup].[query]('for $column in DefinedValues/DefinedValue/ColumnReference return string($column/@Column)').[value]('.', 'varchar(max)'), ' ', ', ') AS [columns],
[plans].[query_text],
[plans].[o_name],
[plans].[execution_plan],
[plans].[last_execution_time],
[plans].[execution_count],
[plans].[total_worker_time],
[plans].[total_physical_reads],
[plans].[total_logical_reads]
FROM
@plans AS [plans]
CROSS APPLY [execution_plan].nodes('//RelOp/IndexScan[@Lookup="1"]') AS [keylookups]([keylookup])
)
SELECT
[lookups].[database],
[lookups].[schema],
[lookups].[table],
[lookups].[index],
[lookups].[columns],
[index_stats].[user_lookups],
[index_stats].[last_user_lookup],
[lookups].[execution_count],
[lookups].[total_worker_time],
[lookups].[total_physical_reads],
[lookups].[total_logical_reads],
[lookups].[last_execution_time],
[lookups].[o_name] AS [object_name],
[lookups].[query_text],
[lookups].[execution_plan]
FROM
[lookups]
JOIN [sys].[dm_db_index_usage_stats] AS [index_stats] ON [lookups].[database_id] = [index_stats].[database_id] AND [lookups].[object_id] = [index_stats].[object_id]
WHERE
[index_stats].[user_lookups] > 0
AND [lookups].[database] NOT IN ( '[master]', '[model]', '[msdb]', '[tempdb]' )
ORDER BY
[index_stats].[user_lookups] DESC,
[lookups].[total_physical_reads] DESC,
[lookups].[total_logical_reads] DESC;Resultado:

Usando una de las consultas anteriores, identificará fácilmente las consultas que presenta el operador de búsqueda de claves. Ahora que ya sabes qué es y cómo solucionarlo, ya puedes analizar si merece la pena crear un índice para cubrir esta consulta o no (Aumento de Espacio en Disco + Aumento de Tiempo de Escritura vs Mejora en Lectura).
No olvide analizar también los índices que faltan en su entorno. Para obtener más información sobre esto, lea el artículo. SQL Server: cómo identificar todos los índices faltantes en una base de datos.
¡Un abrazo grande y hasta la próxima!

Comentarios (0)
Cargando comentarios...