¡Hola, chicos!
Todo en paz ¿no?
En este artículo me gustaría comentar un problema de rendimiento en consultas que encontramos mucho aquí en nuestra vida diaria en Fabricio Lima – BD Solutions, una de las mejores y más reconocidas empresas de Performance Tuning de Brasil. Estamos hablando de algo que muchas veces es terriblemente sencillo de resolver y de conversión implícita, inexplicable y extremadamente común.
Para los ejemplos de este artículo, utilizaré la siguiente estructura de la tabla Órdenes:
CREATE TABLE dbo.Pedidos (
Id_Pedido INT IDENTITY(1,1),
Dt_Pedido DATETIME,
[Status] INT,
Quantidade INT,
Ds_Pedido VARCHAR(10),
Valor NUMERIC(18, 2)
)
CREATE CLUSTERED INDEX SK01_Pedidos ON dbo.Pedidos(Id_Pedido)
CREATE NONCLUSTERED INDEX SK02_Pedidos ON dbo.Pedidos (Ds_Pedido)
GO
¿Qué es la conversión implícita?
La conversión implícita ocurre cuando SQL Server necesita convertir el valor de una o más columnas o variables a otro tipo de datos para permitir la comparación, concatenación u otras operaciones con otras columnas o variables, ya que SQL Server no puede comparar una columna varchar con otro tipo int, por ejemplo, si no convirtió una de las columnas para que ambas tengan el mismo tipo de datos.
Cuando hablamos de conversión, tenemos 2 tipos:
- Explícito: Ocurre cuando el propio desarrollador de la consulta convierte los datos mediante funciones como CAST, CONVERT, etc.
- Implícito: Ocurre cuando SQL Server se ve obligado a convertir el tipo de datos entre columnas o variables internamente porque fueron declarados con diferentes tipos.
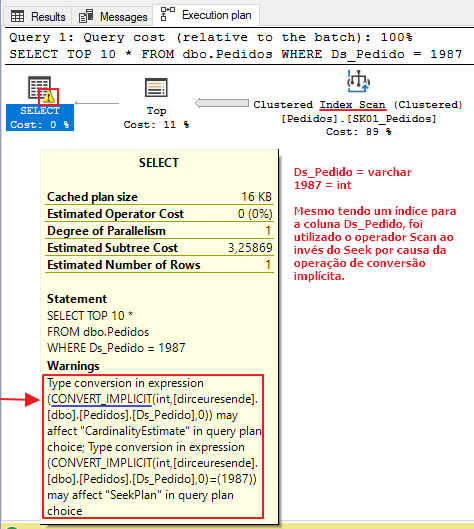
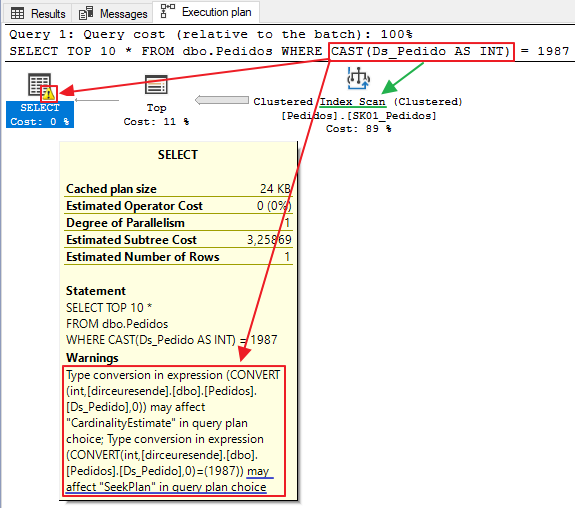
Como esta conversión se aplica a todos los registros de las columnas implicadas, esta operación puede acabar siendo muy costosa y dificultando notablemente la ejecución de la consulta, ya que aunque exista un índice para estas columnas, el optimizador de consultas acabará utilizando el operador Scan en lugar de Seek, no utilizando este índice de la mejor forma posible. Como consecuencia, el tiempo de ejecución y el número de lecturas lógicas pueden terminar aumentando significativamente.
¿Cuál es el impacto de la conversión en mi consulta?
Como mencioné anteriormente, cuando es necesario comparar datos con diferentes tipos, el desarrollador de la consulta debe realizar la conversión explícita usando CAST/CONVERT, o SQL Server tendrá que realizar la conversión implícita internamente para ecualizar los tipos de datos.
¿Pero esto realmente hará alguna diferencia significativa en mi consulta? Analicemos...
Prueba 1: usar el mismo tipo de datos entre la columna y la variable
En esta primera prueba, usaremos la forma correcta de escribir consultas. El tipo de datos de la columna (varchar) es el mismo que el de la variable literal (varchar) y no se produce ninguna conversión de datos. Como resultado de esto, la consulta se ejecutará en 0 ms, con solo 6 lecturas lógicas en el disco.

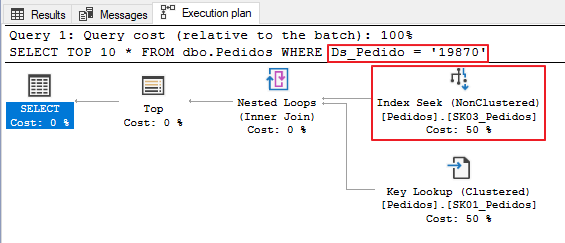
Prueba 2: conversión implícita
En la segunda prueba, usaré una consulta simple, sin conversiones de tipos de datos. Como la columna Ds_Pedido es de tipo varchar y el valor literal 19870 es de tipo entero, SQL Server tendrá que realizar la conversión (implícita) de estos datos.

Prueba 3: conversión de tipos de datos (conversión explícita)
En esta última prueba, usaré una función CAST para aplicar la conversión explícita y evaluar cómo se comportó la consulta en relación con las otras dos consultas.

¿La conversión implícita solo ocurre entre cadenas y números?
En verdad no. Demostraré algunos ejemplos de conversión entre cadenas y cadenas, pero puede ocurrir entre cadenas y fechas, identificador único y cadenas, etc.
VARCHAR y NVARCHAR
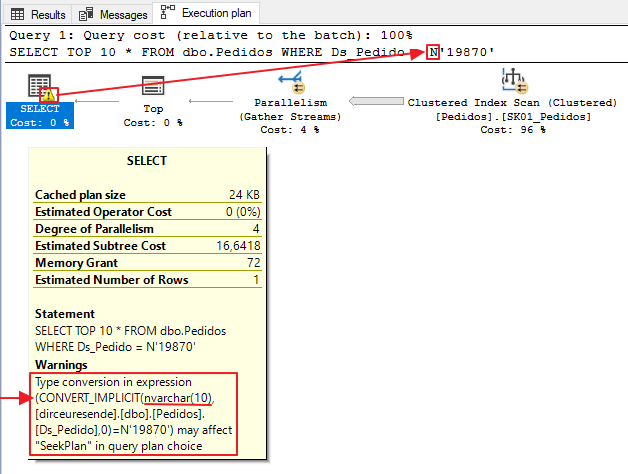
Un error muy común que vemos a diario es la aparición de una conversión implícita entre valores/columnas varchar y nvarchar. Esto ocurre mucho en aplicaciones que usan ORM, como Entity Framework.
Mucha gente termina pensando que no es necesario realizar la conversión entre varchar y nvarchar, pero veamos en el siguiente ejemplo que esto sí sucede:
Otro ejemplo, usando una variable de tipo NVARCHAR(10):
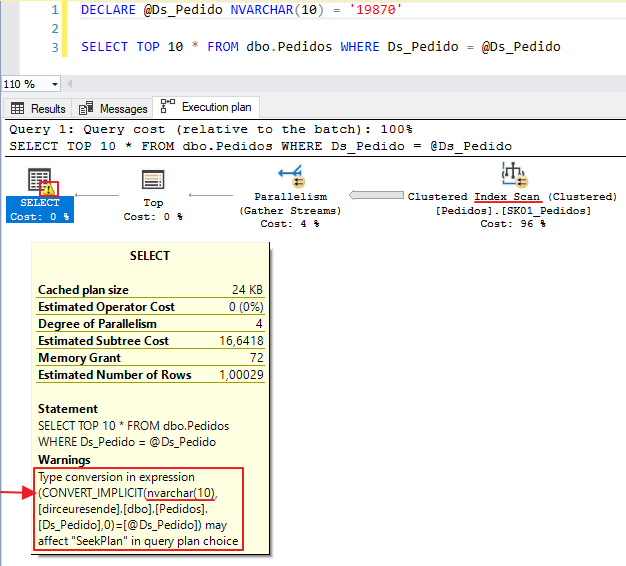
¿No se produce la conversión implícita entre números con diferentes tipos?
Más o menos. Puede ocurrir una conversión implícita en el operador Compute Scalar, pero no impide el uso del operador Seek. Debido a que todos los números pertenecen a la misma familia, SQL Server puede comparar de forma nativa números con diferentes tipos de datos, como INT vs BIGINT o BIGINT vs SMALLINT, por ejemplo.
Después de un consejo del gran jose dice, Terminé prestando atención al hecho de que cuando usamos algunas expresiones con números de diferentes tipos de datos, no vemos una advertencia en el plan de ejecución que demuestre la conversión implícita, ni se usa el operador Scan en lugar de Seek, pero la conversión implícita sí ocurre, en el operador Compute Scalar, como lo demostraré a continuación:

Antes de analizar la conversión implícita, creemos un nuevo índice para evitar este operador de búsqueda de claves, en una técnica conocida como “índice de cobertura”:
CREATE NONCLUSTERED INDEX SK05_Pedidos ON dbo.Pedidos (Ds_Pedido) INCLUDE(Quantidade, Valor)
Al analizar nuevamente el plan de ejecución, vemos que el operador Key Lookup ha abandonado el plan, el nuevo índice se está utilizando con el operador Seek y no hay ninguna advertencia de conversión implícita. ¿Dónde está ella?
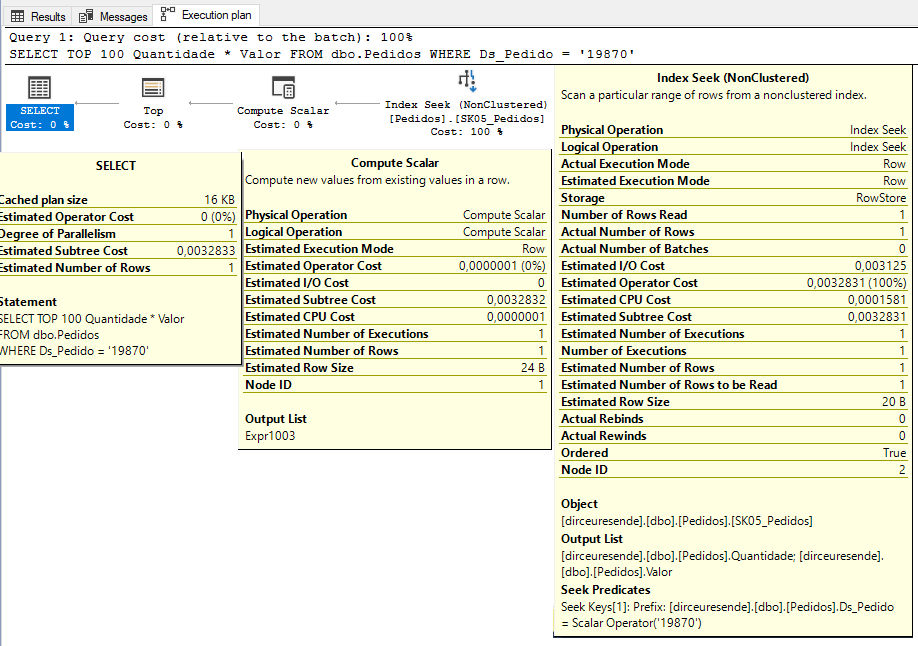
Al visualizar las propiedades del operador Compute Scalar, pudimos identificar que SQL Server realizó la conversión implícita para multiplicar la columna Valor (numérica) por la columna Cantidad (int):
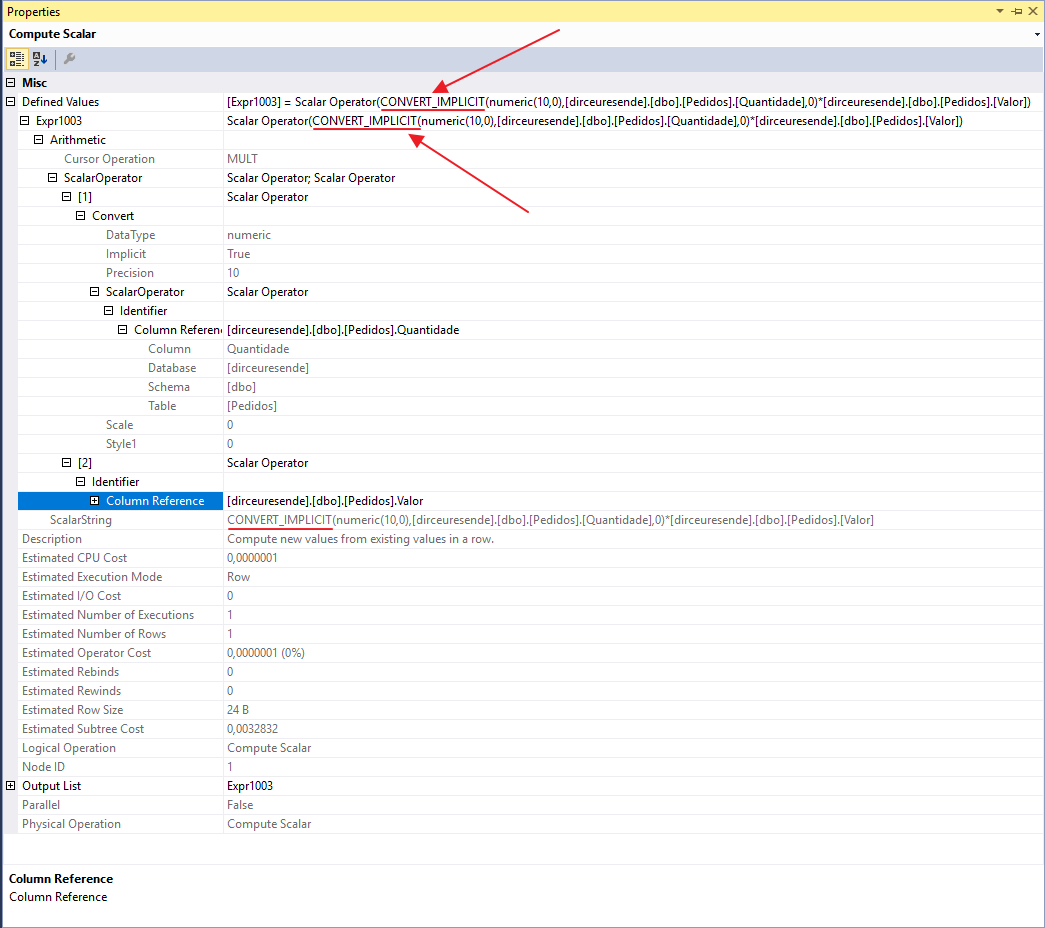
en el articulo Conversiones implícitas que provocan análisis de índice, de Jonathan Kehayias, llevó a cabo una serie de pruebas entre varios tipos de datos y el resultado de este estudio es la siguiente tabla, que demuestra qué cruces entre tipos de datos causan el evento Scan en lugar de Seek en comparación:

En documentación oficial de SQL Server, podemos encontrar la siguiente tabla, que ilustra qué cruces entre tipos de datos que generan conversión implícita, cuáles necesitan utilizar conversión explícita y qué conversiones no son posibles:

¿Se produce también la conversión implícita en JOIN?
En cualquier operación o comparación de expresiones con diferentes tipos de datos, puede ocurrir una conversión implícita (de acuerdo con las reglas vistas anteriormente), ya sea en SELECT, WHERE, JOIN, CROSS APPLY, etc., como lo demostraré a continuación.
Creé una tabla llamada Pedidos2, con la misma estructura y datos que la tabla Pedidos. Después de eso, realicé una operación ALTER TABLE para cambiar el tipo de datos de la columna Ds_Pedido a NVARCHAR(10) y con eso tenemos el siguiente ejemplo:
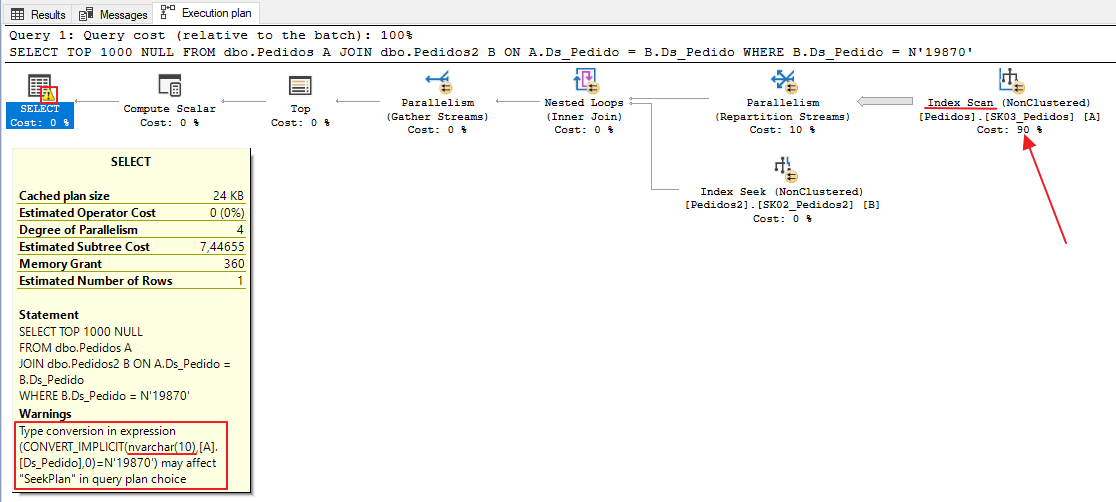
Note que hubo una conversión implícita entre las columnas Ds_Pedido, ya que en la tabla Orders es de tipo VARCHAR y en la tabla Orders2 es de tipo NVARCHAR. Debido a esto, en lugar de utilizar la operación de búsqueda de índice, se utilizó la exploración de índice para leer los datos de la tabla de pedidos.
Si analizamos el número de lecturas de las 2 tablas, vemos una diferencia llamativa debido a la conversión implícita:

En este caso podemos observar un GRAVE error de modelado de datos, que permitió que dos tablas que tienen relaciones entre sí utilizaran diferentes tipos de datos. Para resolver este problema de rendimiento en este escenario, y obtener el máximo rendimiento de esta consulta, cambiemos el tipo de columna Ds_Pedido en la tabla Pedidos a nvarchar(10), el mismo tipo que en la tabla Pedidos2, ya que el filtro usado en WHERE es de tipo NVARCHAR:
ALTER TABLE Pedidos ALTER COLUMN Ds_Pedido nvarchar(10)Pero luego encontramos este error al intentar cambiar el tipo de datos de la columna:
Mensaje 5074, Nivel 16, Estado 1, Línea 8
El índice 'SK03_Pedidos' depende de la columna 'Ds_Pedido'.
Mensaje 4922, Nivel 16, Estado 9, Línea 8
ALTER TABLE ALTER COLUMN Ds_Pedido falló porque uno o más objetos acceden a esta columna.
Sin mencionar que puede haber otras relaciones entre esta tabla y otras que usan esta columna, que actualmente funcionan bien, y que pueden comenzar a tener problemas de conversión implícitos al cambiar el tipo de datos. Como todo en el rendimiento, realizar este tipo de correcciones requiere validaciones, análisis y ¡muchas pruebas!
Si necesita un script para identificar y recrear claves externas que hacen referencia a una tabla, lea mi publicación Cómo identificar, eliminar y recrear claves externas (FK) de una tabla en SQL Server.
En este caso anterior, consideraremos que esta columna al ser de tipo VARCHAR fue un error de modelado y corregiremos el problema. Para hacer esto, usaré los siguientes comandos T-SQL para eliminar el índice, cambiar el tipo y crear el índice nuevamente:
DROP INDEX SK03_Pedidos ON dbo.Pedidos
GO
ALTER TABLE Pedidos ALTER COLUMN Ds_Pedido nvarchar(10)
GO
CREATE NONCLUSTERED INDEX [SK03_Pedidos] ON [dbo].[Pedidos] ([Ds_Pedido])
GO
Después de hacer coincidir el tipo de datos entre las dos columnas, repitamos la consulta realizada anteriormente y analicemos los resultados:
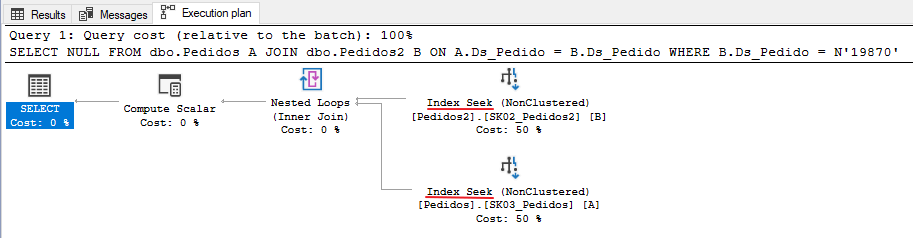
Ahora el plan de ejecución es excelente. Hemos eliminado la conversión implícita y utilizamos operadores de búsqueda en los índices. Veamos cómo quedó el tiempo de ejecución y las lecturas lógicas:

Tiempo de ejecución de 0 ms y solo 3 lecturas lógicas. ¡¡Excelente!! Consulta optimizada.
Pero ¿qué pasa con los casos en los que no podemos ejecutar el comando ALTER TABLE debido a otras relaciones que ya existen? ¿Qué alternativas tenemos para esto?
R: Hay varias soluciones, pero una que me gusta mucho es el uso de columnas calculadas e indexadas, que tienen un bajo impacto en la aplicación (aunque puede tener impacto, especialmente en operaciones INSERT) y suelen ser muy efectivas y prácticas, ya que cada vez que se cambia la columna original, automáticamente también se actualiza la columna calculada (así como los índices que hacen referencia a la columna calculada, si existen). Pero recuerda: ¡PRUEBA ANTES DE IMPLEMENTAR!
Demostraré cómo se puede implementar esta solución en el ejemplo anterior:
ALTER TABLE dbo.Pedidos ADD Ds_Pedido_NVARCHAR AS (CONVERT(NVARCHAR(10), Ds_Pedido))
GO
CREATE NONCLUSTERED INDEX SK04_Pedidos ON dbo.Pedidos(Ds_Pedido_NVARCHAR)
GO
Al crear esta columna calculada, no ocupará NINGÚN espacio en su base de datos, ya que se calcula en tiempo real. Sólo el índice creado ocupará espacio y aportará mejoras de rendimiento a esta solución:
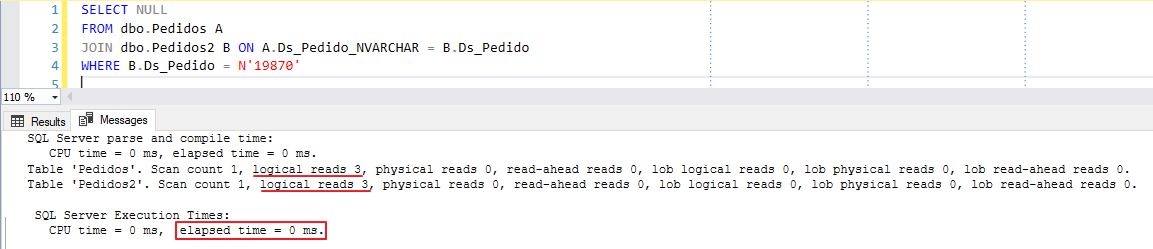
Y si analizamos nuestro plan de ejecución usando la nueva columna calculada, vemos que no tiene conversión implícita y está realizando una operación de Búsqueda, tal como cuando demostré cómo sería si las columnas fueran del mismo tipo:

¿Cómo elige SQL Server qué tipo convertir?
Esta es una excelente pregunta. ¿Cómo podemos consultar la página? Prioridad del tipo de datosSegún la documentación de Microsoft, cuando un operador combina dos expresiones de diferentes tipos de datos, las reglas para la precedencia de tipos de datos especifican que el tipo de datos con menor precedencia se convierte al tipo de datos con mayor precedencia. Si la conversión no es una conversión implícita admitida, se devuelve un error.
SQL Server utiliza el siguiente orden de prioridad para los tipos de datos:
- tipos de datos personalizados del usuario (nivel más alto)
- variante_sql
- XML
- compensación de fecha y hora
- fechahora2
- fecha y hora
- pequeña fecha y hora
- fecha
- equipo
- flotar
- real
- decimal
- dinero
- poco dinero
- bigint
- entero
- pequeño
- diminuto
- poco
- ntexto
- texto
- imagen
- marca de tiempo
- identificador único
- nvarchar (incluido nvarchar(max) )
- nchar
- varchar (incluido varchar(max) )
- carbonizarse
- varbinary (incluido varbinary(max) )
- binario (nivel más bajo)
En otras palabras, es por eso que en el ejemplo anterior, cuando comparamos una columna varchar con una expresión nvarchar, la columna se convirtió a nvarchar en lugar de al revés (lo que en realidad tenía más sentido convertir un valor fijo que una columna completa).
Cómo identificar conversiones implícitas en su entorno
Como dije anteriormente, las operaciones de conversión implícitas son muy comunes en entornos de SQL Server y por eso, compartiré dos formas de identificar la ocurrencia de estos eventos en su entorno.
Método 1: planificar el caché del DMV
Con el siguiente script, podrá identificar las consultas que consumieron la mayor cantidad de CPU y que tienen una conversión implícita a través de las DMV de SQL Server. No es necesario habilitar ninguna opción ni crear ningún objeto, ya que estas consultas son nativas y se recopilan automáticamente de forma predeterminada.
SELECT TOP ( 100 )
DB_NAME(B.[dbid]) AS [Database],
B.[text] AS [Consulta],
A.total_worker_time AS [Total Worker Time],
A.total_worker_time / A.execution_count AS [Avg Worker Time],
A.max_worker_time AS [Max Worker Time],
A.total_elapsed_time / A.execution_count AS [Avg Elapsed Time],
A.max_elapsed_time AS [Max Elapsed Time],
A.total_logical_reads / A.execution_count AS [Avg Logical Reads],
A.max_logical_reads AS [Max Logical Reads],
A.execution_count AS [Execution Count],
A.creation_time AS [Creation Time],
C.query_plan AS [Query Plan]
FROM
sys.dm_exec_query_stats AS A WITH ( NOLOCK )
CROSS APPLY sys.dm_exec_sql_text(A.plan_handle) AS B
CROSS APPLY sys.dm_exec_query_plan(A.plan_handle) AS C
WHERE
CAST(C.query_plan AS NVARCHAR(MAX)) LIKE ( '%CONVERT_IMPLICIT%' )
AND B.[dbid] = DB_ID()
AND B.[text] NOT LIKE '%sys.dm_exec_sql_text%' -- Não pegar a própria consulta
ORDER BY
A.total_worker_time DESCResultado:

Método 2: eventos extendidos (XE)
Con el siguiente script, puede capturar eventos de conversión implícitos generados a través de eventos de eventos extendidos.
La ventaja de esta solución sobre consultar el plancache es que los datos se almacenan permanentemente, ya que el caché del plan se “trunca” cada vez que se reinicia el servicio SQL Server, no todas las consultas se almacenan allí y cuando lo hacen, el almacenamiento es temporal. Además, si inicia el servicio utilizando el parámetro -x, varios DMV, como dm_exec_query_stats, no se completan.
La desventaja es que necesitas crear objetos en la base de datos (Job, XE, tabla), generando mucho más trabajo para obtener esta información, que solo será recopilada después de la creación de estos controles. No se identificarán eventos que ocurrieron en el pasado.
Guión XE:
IF (EXISTS(SELECT NULL FROM sys.dm_xe_sessions WHERE [name] = 'Conversão Implícita')) DROP EVENT SESSION [Conversão Implícita] ON SERVER
GO
CREATE EVENT SESSION [Conversão Implícita]
ON SERVER
ADD EVENT sqlserver.plan_affecting_convert (
ACTION (
sqlserver.client_app_name,
sqlserver.client_hostname,
sqlserver.database_name,
sqlserver.username,
sqlserver.sql_text
)
WHERE (
[convert_issue] = 2 -- 1 = Cardinality Estimate / 2 = Seek Plan
)
)
ADD TARGET package0.event_file (
SET filename = N'C:\Traces\Conversão Implícita',
max_file_size = ( 50 ),
max_rollover_files = ( 16 )
)
GO
ALTER EVENT SESSION [Conversão implícita] ON SERVER STATE = START
GO
Y después de crear este XE, puede usar el siguiente script para recopilar los datos y registrarlos en una tabla de historial.
IF (OBJECT_ID('dbo.Historico_Conversao_Implicita') IS NULL)
BEGIN
-- DROP TABLE dbo.Historico_Conversao_Implicita
CREATE TABLE dbo.Historico_Conversao_Implicita (
Dt_Evento DATETIME,
[database_name] VARCHAR(100),
username VARCHAR(100),
client_hostname VARCHAR(100),
client_app_name VARCHAR(100),
[convert_issue] VARCHAR(50),
[expression] VARCHAR(MAX),
sql_text XML
)
CREATE CLUSTERED INDEX SK01_Historico_Erros ON dbo.Historico_Conversao_Implicita(Dt_Evento)
END
DECLARE @TimeZone INT = DATEDIFF(HOUR, GETUTCDATE(), GETDATE())
DECLARE @Dt_Ultimo_Evento DATETIME = ISNULL((SELECT MAX(Dt_Evento) FROM dbo.Historico_Conversao_Implicita WITH(NOLOCK)), '1990-01-01')
IF (OBJECT_ID('tempdb..#Eventos') IS NOT NULL) DROP TABLE #Eventos
;WITH CTE AS (
SELECT CONVERT(XML, event_data) AS event_data
FROM sys.fn_xe_file_target_read_file(N'C:\Traces\Conversão Implícita*.xel', NULL, NULL, NULL)
)
SELECT
DATEADD(HOUR, @TimeZone, CTE.event_data.value('(//event/@timestamp)[1]', 'datetime')) AS Dt_Evento,
CTE.event_data
INTO
#Eventos
FROM
CTE
WHERE
DATEADD(HOUR, @TimeZone, CTE.event_data.value('(//event/@timestamp)[1]', 'datetime')) > @Dt_Ultimo_Evento
SET QUOTED_IDENTIFIER ON
INSERT INTO dbo.Historico_Conversao_Implicita
SELECT
A.Dt_Evento,
A.[database_name],
A.username,
A.client_hostname,
A.client_app_name,
A.convert_issue,
A.expression,
TRY_CAST(A.sql_text AS XML) AS sql_text
FROM (
SELECT DISTINCT
A.Dt_Evento,
xed.event_data.value('(action[@name="database_name"]/value)[1]', 'varchar(100)') AS [database_name],
xed.event_data.value('(action[@name="username"]/value)[1]', 'varchar(100)') AS [username],
xed.event_data.value('(action[@name="client_hostname"]/value)[1]', 'varchar(100)') AS [client_hostname],
xed.event_data.value('(action[@name="client_app_name"]/value)[1]', 'varchar(100)') AS [client_app_name],
xed.event_data.value('(data[@name="convert_issue"]/text)[1]', 'varchar(100)') AS [convert_issue],
xed.event_data.value('(data[@name="expression"]/value)[1]', 'varchar(max)') AS [expression],
xed.event_data.value('(action[@name="sql_text"]/value)[1]', 'varchar(max)') AS [sql_text]
FROM
#Eventos A
CROSS APPLY A.event_data.nodes('//event') AS xed (event_data)
) AY ahora simplemente cree 1 trabajo para recopilar estos datos periódicamente. Para acceder a los datos recopilados, simplemente consulte la tabla recién creada para analizar las ocurrencias de conversión implícitas en su entorno:

Otros artículos sobre conversión implícita
¿Quieres otros puntos de vista y ejemplos sobre este tema? Consulte algunos artículos de otros autores que he seleccionado para usted:
- https://portosql.wordpress.com/2018/10/25/os-perigos-da-conversao-implicita-1/
- https://portosql.wordpress.com/2018/11/28/os-perigos-da-conversao-implicita-2/
- https://sqlkiwi.blogspot.com/2011/07/join-performance-implicit-conversions-and-residuals.html
- https://www.sqlskills.com/blogs/jonathan/implicit-conversions-that-cause-index-scans/
- https://hackernoon.com/are-implicit-conversions-killing-your-sql-query-performance-70961e547f11
- https://docs.microsoft.com/en-us/sql/t-sql/data-types/data-type-conversion-database-engine?view=sql-server-2017
Bueno chicos, espero que les haya gustado este post, que realmente hayan entendido los peligros de la conversión explícita e implícita y no permitan que esto vuelva a suceder en sus consultas. El DBA te lo agradece.
Un abrazo grande y hasta la próxima.

Comentários (0)
Carregando comentários…