¡¡¡Hola, chicos!!!
En este artículo me gustaría compartir con ustedes algo que veo mucho a diario cuando estoy realizando consultoría de Tuning, que son consultas que consumen mucho tiempo, con alto consumo de E/S y CPU, y que usan funciones WHERE o JOIN en tablas con muchos registros y cómo podemos usar una técnica de indexación de columnas calculada (o computada) muy simple para resolver este problema.
Como comento en el artículo. Comprender cómo funcionan los índices en SQL Server, al usar funciones en cláusulas WHERE o JOINS, estamos violando el concepto de Consulta SARGabilidad, es decir, que estamos haciendo que esta consulta ya no utilice operaciones de búsqueda en los índices, ya que SQL Server necesita leer la tabla completa, aplicar la función deseada y luego comparar los valores y devolver los resultados.
Lo que quiero en este artículo es mostrarle este escenario, cómo identificarlo y algunas posibles soluciones para mejorar el rendimiento de las consultas. Entonces, ¡vamos!
Creando la base de demostración para este artículo
Para crear esta tabla de ejemplo similar a la mía (los datos son aleatorios, cierto... jajaja), para poder seguir el artículo y simular estos escenarios, puedes usar el siguiente script:
IF (OBJECT_ID('_Clientes') IS NOT NULL) DROP TABLE _Clientes
CREATE TABLE _Clientes (
Id_Cliente INT IDENTITY(1,1),
Dados_Serializados VARCHAR(MAX)
)
INSERT INTO _Clientes ( Dados_Serializados )
SELECT
CONVERT(VARCHAR(19), DATEADD(SECOND, (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 199999999, '2015-01-01'), 121) + '|' +
CONVERT(VARCHAR(20), CONVERT(INT, (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 9)) + '|' +
CONVERT(VARCHAR(20), CONVERT(INT, (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 10)) + '|' +
CONVERT(VARCHAR(20), CONVERT(INT, 0.459485495 * (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0)) * 1999)
GO 10000
INSERT INTO _Clientes ( Dados_Serializados )
SELECT Dados_Serializados
FROM _Clientes
GO 9
CREATE CLUSTERED INDEX SK01_Pedidos ON _Clientes(Id_Cliente)
CREATE NONCLUSTERED INDEX SK02_Pedidos ON _Clientes(Dados_Serializados)
GO
Demostración usando la función nativa
Para demostrar cómo una consulta puede ser lenta simplemente porque usa una función WHERE o JOIN, inicialmente usaré la siguiente consulta:
SELECT *
FROM _Clientes
WHERE Dados_Serializados = '2016-11-22 04:49:06|2|0|0'
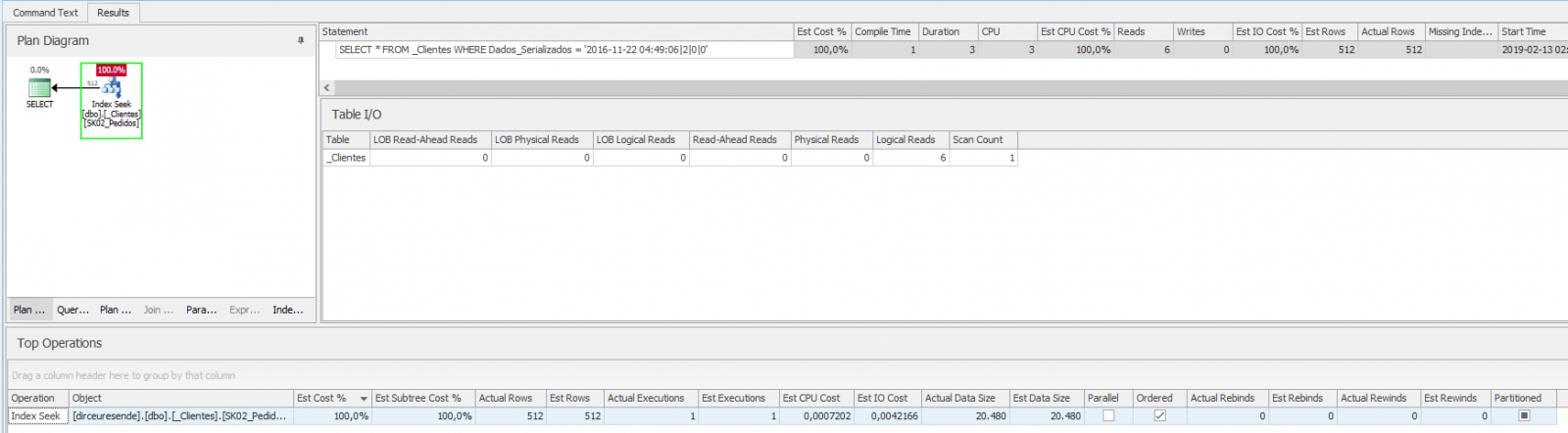
Si analizamos el plan de ejecución de esta consulta vemos que está utilizando el operador Index Seek, realizando solo 6 lecturas y 512 registros. Al analizar la información de CPU y IO, podemos concluir que 3 ms de CPU (compilación) y 3 ms de tiempo de ejecución son bastante aceptables:
Ahora usemos una función en esta misma consulta:
SELECT *
FROM _Clientes
WHERE SUBSTRING(Dados_Serializados, 1, 10) = '2016-11-22'
Análisis de ejecución:
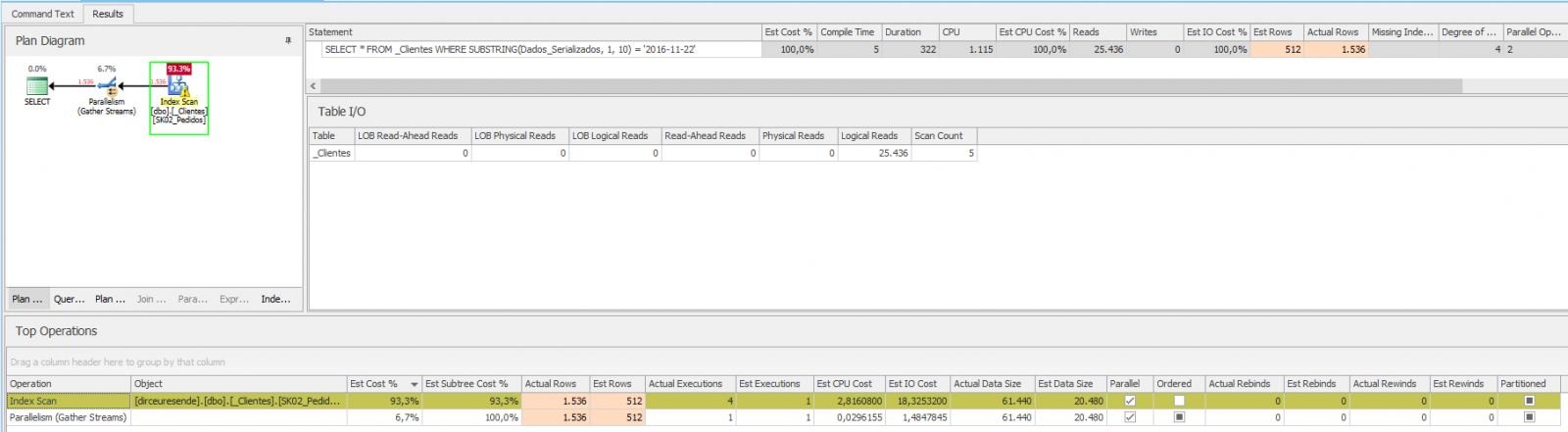
En otras palabras, el resultado fue terrible... Escaneo de índice, tiempo de CPU elevado, tiempo de ejecución elevado, muchas lecturas lógicas. Todo esto por la función utilizada, que dejó de utilizar el operador Index Seek y pasó a utilizar Index Scan.
Resolver esto es muy sencillo, sobre todo porque esta función tal como está configurada (igual a IZQUIERDA), nos está ayudando, ya que en estos casos podemos reemplazar la función por LIKE 'texto%' fácilmente, ya que SQL Server usará la operación Buscar en el índice:
SELECT *
FROM _Clientes
WHERE Dados_Serializados LIKE '2016-11-22%'Análisis de ejecución:

Podemos notar que al usar LIKE ‘texto%’, el índice se usó con la operación Buscar, haciendo que nuestra consulta vuelva a funcionar.
ME GUSTA y SARGabilidad
IMPORTANTE: A diferencia de LIKE 'text%', si agregas el símbolo '%' antes del texto, para filtrar todo lo que contenga o termine con una determinada expresión, el índice no se utilizará con el operador Seek, sino Scan.
Para entender el motivo de esto, hagamos una analogía con el índice de un diccionario: Para encontrar todas las palabras en el diccionario que comienzan con 'prueba' es muy sencillo, basta con ir a la letra T, luego a la letra 'e', luego a la letra 's' y así sucesivamente hasta encontrar las palabras deseadas. Cuando la siguiente palabra de la lista sea mayor que 'prueba', podremos finalizar la búsqueda.
Para identificar todas las palabras del diccionario que contienen la palabra 'prueba' o terminan en 'prueba', tendremos que mirar todas las palabras del diccionario para poder identificarlas.
¿Facilitó la comprensión de cómo funcionan los índices? Si todavía tienes preguntas, lee mi artículo. Comprender cómo funcionan los índices en SQL Server.
Pero ¿y si fuera la función CORRECTA, por ejemplo? ¿Nuestra consulta no utilizará la operación de búsqueda en el índice mismo?
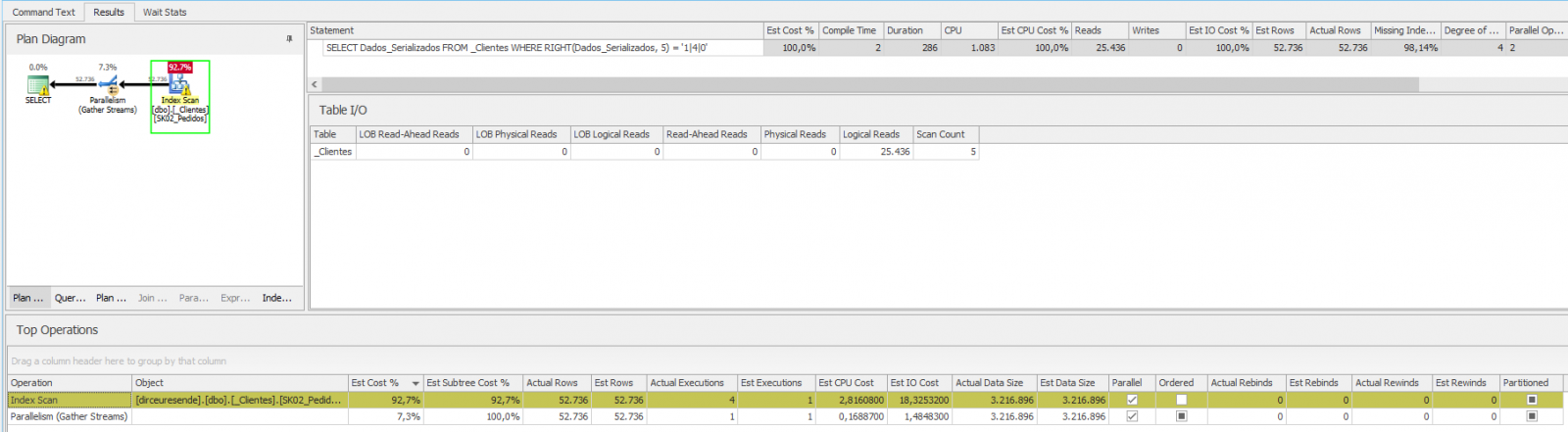
Como vimos arriba, la consulta fue muy mala, con una gran cantidad de lecturas lógicas, tiempo de ejecución y CPU. Para resolver este problema, usemos la función de columna calculada e indexemos esta columna calculada:
-- Cria a nova coluna calculada
ALTER TABLE _Clientes ADD Right_5 AS (RIGHT(Dados_Serializados, 5))
GO
-- Cria um índice para a nova coluna criada
CREATE NONCLUSTERED INDEX SK03_Clientes ON dbo._Clientes(Right_5)
GO
-- Executa a consulta nova
SELECT Right_5
FROM _Clientes
WHERE Right_5 = '1|4|0'
Análisis de ejecución:
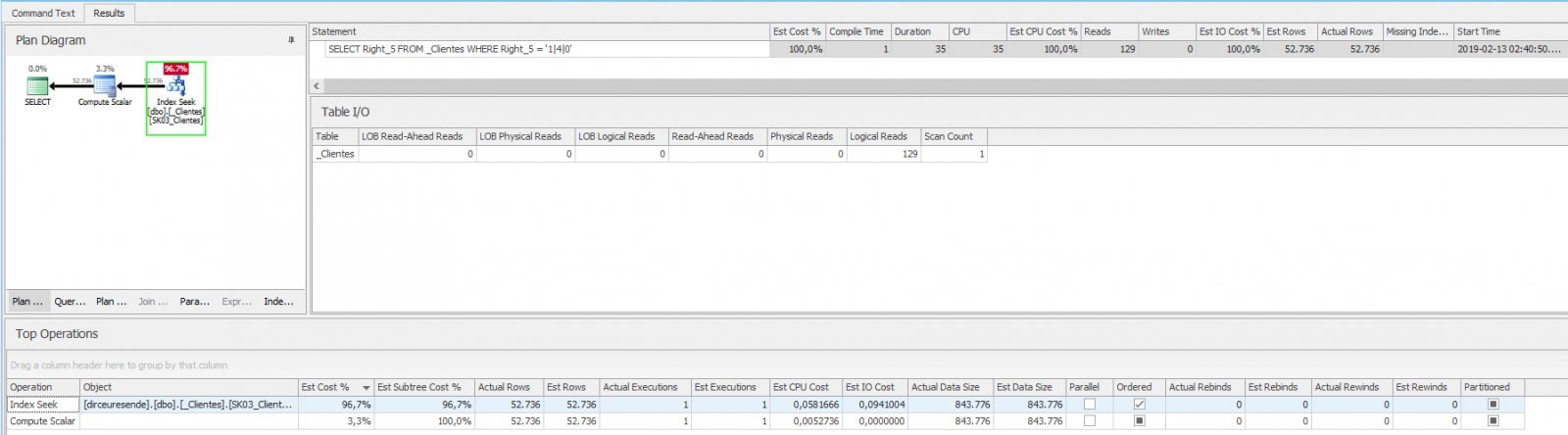
¡Guau! ¡La consulta es mucho más rápida ahora! Esto sucede porque al crear el índice ya calculó estos datos para toda la columna y la dejó ordenada. Esto hace que las consultas sean mucho más rápidas que tener que calcular esto en tiempo real y luego comparar los valores.
Consideraciones para la creación de índices y determinismo de funciones del sistema.
Nota 1: Tenga en cuenta el hecho de que la creación del índice consumirá espacio en el disco y la inclusión de una columna en una tabla, incluso si se calcula, debe probarse primero para garantizar que esto no genere ningún error durante una operación de inserción que no especifique los campos, por ejemplo.
Nota 2: Un punto muy importante a resaltar es que crear columnas calculadas persistentes en el disco e indexar columnas calculadas solo es posible cuando se usa función determinista.
Todas las funciones que existen en SQL Server son deterministas o no deterministas. El determinismo de una función está definido por los datos devueltos por la función. A continuación se describe el determinismo de una función:
- Se considera una función determinista se siempre devuelve el mismo conjunto de resultados cuando se llama con el mismo conjunto de valores de entrada.
- Se considera una función no determinista si no devuelve el mismo conjunto de resultados cuando se llama con el mismo conjunto de valores de entrada.
Esto puede parecer un poco complicado, pero en realidad no lo es. Consulte, por ejemplo, las funciones DATEDIFF y GETDATE. DatedIFF es determinista porque siempre devolverá los mismos datos siempre que se ejecute con los mismos parámetros de entrada. GETDATE no es determinista porque nunca devolverá la misma fecha cada vez que se ejecuta.
Demostración utilizando la función definida por el usuario (UDF)
Si usar una función nativa en WHERE/JOIN ya empeora el rendimiento de nuestras consultas, usar una función personalizada del usuario el escenario es aún peor. Para esta publicación, usaré la función. fncDividir (con enlace de esquema):
SELECT Dados_Serializados
FROM _Clientes
WHERE dbo.fncSplit(Dados_Serializados, '|', 3) = '1'Análisis de ejecución:

Como puede ver, esta consulta simple, en una tabla de 10,000 registros, tardó alrededor de 35 segundos en ejecutarse, consumiendo casi 15 segundos de CPU. Se realizaron alrededor de 240 mil lecturas lógicas, procesándose 610 mil líneas para devolver las 1.040 líneas del resultado final. Resumen: ¡Es realmente malo!
Para intentar mejorar el rendimiento de esta consulta, usaremos la misma solución que en el ejemplo anterior, creando una columna calculada e indexando esta columna:
-- Cria a nova coluna calculada
ALTER TABLE _Clientes ADD Coluna_Teste AS (dbo.fncSplit(Dados_Serializados, '|', 3))
GO
-- Cria um índice para a nova coluna criada
CREATE NONCLUSTERED INDEX SK04_Clientes ON dbo._Clientes(Coluna_Teste) INCLUDE(Dados_Serializados)
GO
-- Executa a consulta nova
SELECT Dados_Serializados
FROM _Clientes
WHERE Coluna_Teste = '1'
Antes de analizar la ejecución de esta prueba, debo hacer una advertencia sobre la creación de una columna calculada persistente en el disco usando una función definida por el usuario (UDF) y la creación de índices en estas columnas calculadas:
Determinismo de función definida por el usuario (UDF)
Importante: Cuando crea una función definida por el usuario (UDF), SQL Server registra determinismo. El determinismo de una función definida por el usuario está determinado por cómo se crea la función. Una función definida por el usuario se considera determinista si se cumplen todos los criterios siguientes:
- La función está vinculada al esquema para todos los objetos de base de datos a los que hace referencia.
- Cualquier función llamada por la función definida por el usuario es determinista. Esto incluye todas las funciones del sistema y definidas por el usuario.
- La función no hace referencia a ningún objeto de base de datos que esté fuera de su alcance. Esto significa que la función no puede hacer referencia a tablas, variables o cursores externos.
Cuando crea una función, SQL Server aplica todos estos criterios a la función para determinar su determinismo. Si una función falla alguna de estas comprobaciones, la función se marca como no determinista. A veces, estas comprobaciones pueden producir funciones marcadas como no deterministas incluso cuando espera que estén marcadas como deterministas.
En el caso de este ejemplo, si no incluyo el parámetro FROM SCHEMABINDING en la declaración fncSplit, encontraremos el siguiente mensaje de error:
La columna 'Coluna_Teste' de la tabla 'dbo._Clientes' no se puede utilizar en un índice o estadística ni como clave de partición porque no es determinista.
Análisis de ejecución:
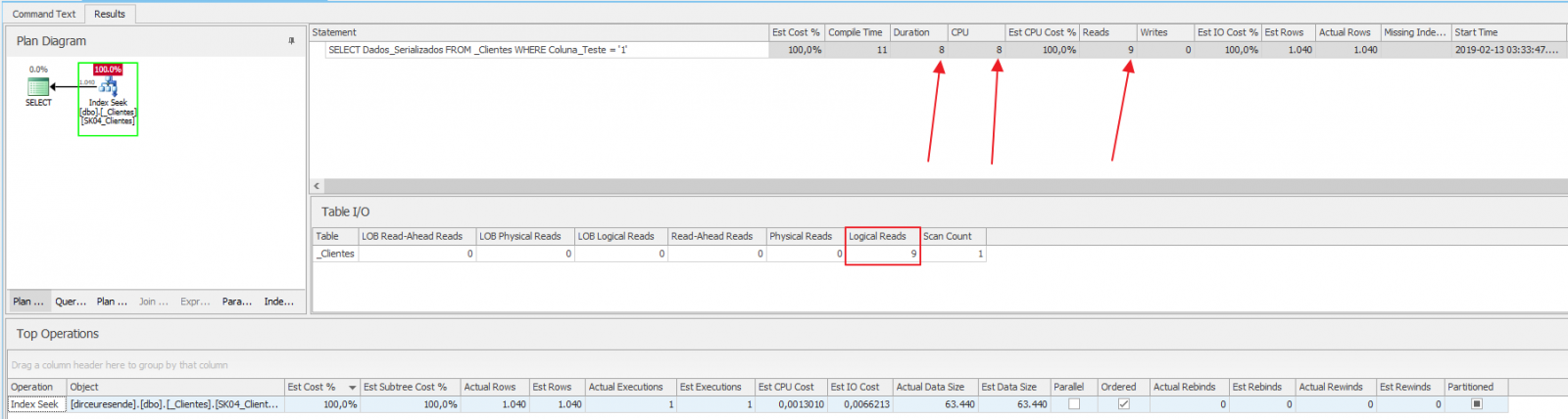
¡¡Guau!! ¡¡De 32 segundos nuestra consulta bajó a 8 ms!! ¡La cantidad de CPU cayó de 14,974 a 8 y la cantidad de lecturas lógicas cayó de 240,061 a 9! Esta afinación fue realmente muy efectiva. Apuesto a que si hicieras algo similar con un cliente, recibirías grandes elogios 🙂
Antes de terminar este artículo, me gustaría dejarte un último mensaje:
Como siempre digo: al aplicar técnicas de ajuste del rendimiento, ¡PRUEBE SIEMPRE!
Bueno chicos, espero que les haya gustado este artículo.
¡Un fuerte abrazo y hasta luego!

Comentários (0)
Carregando comentários…