
¡Hola, chicos!
En esta publicación, me gustaría compartir con ustedes un script para identificar todos los índices faltantes (Missing indexes) de una base de datos en SQL Server, Instancia administrada o Azure SQL Database. Recuerde que para ejecutar este script, necesitará el permiso "Ver estado del servidor" en la instancia.
Ya había compartido este script en los artículos. Comprender cómo funcionan los índices en SQL Server y SQL Server: consultas de DBA útiles para el día a día que siempre debe buscar en Internet, pero Google no indexó correctamente a quienes buscaban este script.
Una reflexión sobre los índices
Una de las tareas diarias de un DBA es identificar índices en la base de datos que podrían mejorar el rendimiento de las consultas que afectan el medio ambiente. Este siempre debe ser el objetivo de un índice: mejorar el rendimiento de consultas que están impactando el entorno o podrían tener una ganancia en un proceso crítico.
En la mayoría de los entornos, no podrá crear índices para cubrir todas las consultas que ingresan a la base de datos. Los índices tienen un costo de almacenamiento (ocupan espacio; los índices a menudo ocupan más espacio que la propia tabla) y reducen el rendimiento de las operaciones de escritura, además de requerir procesos de mantenimiento como reorganización/reconstrucción para mantener baja la fragmentación.
Por los motivos mencionados anteriormente, no puede crear índices sin ningún control. Los índices deben estar muy bien pensados para intentar tener el mejor coste-beneficio posible. Si no se utiliza un índice, se debe eliminar.
Otro consejo del que siempre hablo es: muchas veces necesitarás crear varios índices no agrupados porque tu índice agrupado no estuvo bien planificado. Evalúe siempre si el índice agrupado está optimizado para la forma en que se realizan las consultas a la base de datos. No tiene sentido crear el índice agrupado en la columna de incremento automático si no se utiliza como filtro en las consultas principales.
No se centre únicamente en los números y en las grandes reducciones del tiempo de ejecución. Si un índice sirve para reducir el tiempo de una consulta de 1 hora a 1 segundo, pero es una consulta que sólo se ejecuta una vez al día, en las primeras horas de la mañana, y no aporta grandes ganancias, no ayuda. Hubiera sido mejor intentar optimizar una consulta que tardaba 5 segundos y ahora tarda 0ms, pero se ejecuta 1 millón de veces al día.
Trate siempre de pensar detenidamente en el valor que agregará el índice a los procesos de la empresa antes de crearlo. Como dije, no se puede crear un índice para cada consulta que llega a la base de datos. Concéntrese en lo que realmente importa y que en realidad es un problema, lo que hace que el sistema se ralentice, que el cliente espere mientras se cargan los datos, cosas así.
¿Cuáles son los índices que faltan?
Para ayudar a los DBA a identificar rápidamente situaciones en las que un índice podría marcar la diferencia, SQL Server tiene un conjunto de DMV. dm_db_missing_index_% que proporcionan información sobre estos índices faltantes (Missing indexes).
Esta información es generada automáticamente por el Motor SQL Server con base en planes de ejecución almacenados en caché, es decir, con base en las consultas que ya han sido enviadas a la base de datos, SQL Server identifica algunos índices que podrían cubrir estas consultas para brindar un mejor rendimiento, considerando los índices ya existentes, las columnas filtradas y las columnas devueltas.
Luego de este análisis, el resultado está disponible para consulta usando el script que compartiré contigo, y el DBA puede analizar rápidamente las sugerencias e identificar qué tiene sentido crear y qué no.
No cree índices sin analizarlos primero, incluso si son índices faltantes devueltos por este script. No siempre se devolverá el mejor índice posible y, a menudo, ya existe un índice muy similar al sugerido, donde vale la pena fusionar el índice existente con el índice sugerido, cambiar el índice actual e incluir solo las nuevas columnas sugeridas. Esto es mucho mejor que mantener 2 índices casi iguales.
Y créanme: es muy común ver varios y varios índices creados en clientes, donde el DBA no quiso tomarse la molestia de siquiera cambiar el nombre de los índices, y mucho menos analizar si existen mejores formas de crear el índice sugerido.
Cómo identificar todos los índices faltantes en una base de datos
Con la consulta a continuación, podrá ver sugerencias de índice de SQL Server basadas en las estadísticas del índice faltante. Para generar estos datos, se utilizará el conjunto de DMV de índices faltantes (dm_db_missing_index_%).
SELECT
db.[name] AS [DatabaseName],
id.[object_id] AS [ObjectID],
OBJECT_NAME(id.[object_id], db.[database_id]) AS [ObjectName],
gs.avg_total_user_cost * ( gs.avg_user_impact / 100.0 ) * ( gs.user_seeks + gs.user_scans ) AS ImprovementMeasure,
gs.[user_seeks] * gs.[avg_total_user_cost] * ( gs.[avg_user_impact] * 0.01 ) AS [IndexAdvantage],
'CREATE INDEX [IX_' + OBJECT_NAME(id.[object_id], db.[database_id]) + '_' + REPLACE(REPLACE(REPLACE(ISNULL(id.[equality_columns], ''), ', ', '_'), '[', ''), ']', '') + CASE WHEN id.[equality_columns] IS NOT NULL AND id.[inequality_columns] IS NOT NULL THEN '_' ELSE '' END + REPLACE(REPLACE(REPLACE(ISNULL(id.[inequality_columns], ''), ', ', '_'), '[', ''), ']', '') + '_' + LEFT(CAST(NEWID() AS [NVARCHAR](64)), 5) + ']' + ' ON ' + id.[statement] + ' (' + ISNULL(id.[equality_columns], '') + CASE WHEN id.[equality_columns] IS NOT NULL AND id.[inequality_columns] IS NOT NULL THEN ',' ELSE '' END + ISNULL(id.[inequality_columns], '') + ')' + ISNULL(' INCLUDE (' + id.[included_columns] + ')', '') AS [ProposedIndex],
id.[statement] AS [FullyQualifiedObjectName],
id.[equality_columns] AS [EqualityColumns],
id.[inequality_columns] AS [InEqualityColumns],
id.[included_columns] AS [IncludedColumns],
gs.[unique_compiles] AS [UniqueCompiles],
gs.[user_seeks] AS [UserSeeks],
gs.[user_scans] AS [UserScans],
gs.[last_user_seek] AS [LastUserSeekTime],
gs.[last_user_scan] AS [LastUserScanTime],
gs.[avg_total_user_cost] AS [AvgTotalUserCost],
gs.[avg_user_impact] AS [AvgUserImpact],
gs.[system_seeks] AS [SystemSeeks],
gs.[system_scans] AS [SystemScans],
gs.[last_system_seek] AS [LastSystemSeekTime],
gs.[last_system_scan] AS [LastSystemScanTime],
gs.[avg_total_system_cost] AS [AvgTotalSystemCost],
gs.[avg_system_impact] AS [AvgSystemImpact],
CAST(CURRENT_TIMESTAMP AS [SMALLDATETIME]) AS [CollectionDate]
FROM
[sys].[dm_db_missing_index_group_stats] gs WITH ( NOLOCK )
JOIN [sys].[dm_db_missing_index_groups] ig WITH ( NOLOCK ) ON gs.[group_handle] = ig.[index_group_handle]
JOIN [sys].[dm_db_missing_index_details] id WITH ( NOLOCK ) ON ig.[index_handle] = id.[index_handle]
JOIN [sys].[databases] db WITH ( NOLOCK ) ON db.[database_id] = id.[database_id]
WHERE
db.[database_id] = DB_ID()
--AND gs.avg_total_user_cost * ( gs.avg_user_impact / 100.0 ) * ( gs.user_seeks + gs.user_scans ) > 10
ORDER BY
[IndexAdvantage] DESC
OPTION ( RECOMPILE );Resultado:
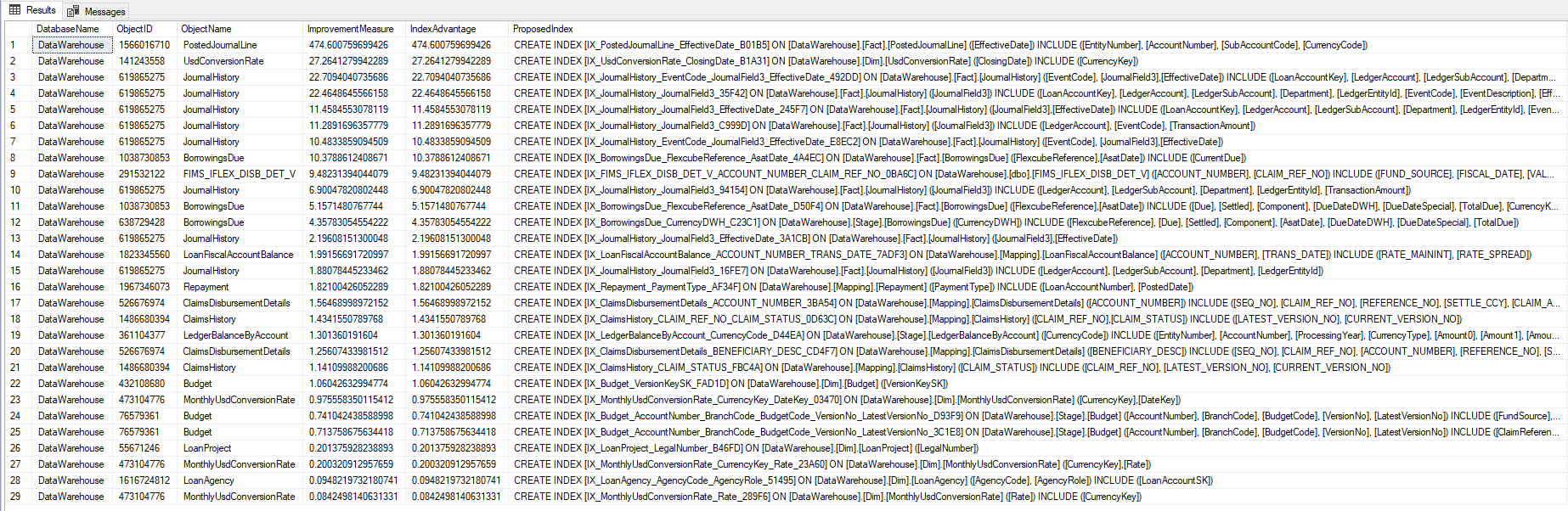
Como vio, en el script anterior, utilizamos DMV de SQL Server para identificar los índices faltantes en la base. Otra alternativa, que incluso nos permite ver el plan de ejecución, es ir directamente a los DMV's del plancache, y extraer estos datos del XML del plan de ejecución.
IF (OBJECT_ID('tempdb..#MissingIndexInfo') IS NOT NULL) DROP TABLE #MissingIndexInfo
;WITH XMLNAMESPACES
(
DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan'
)
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(REPLACE(REPLACE(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'), '[', ''), ']', '')) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' + n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' + n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' + n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' + n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)') AS statement,
(
SELECT DISTINCT
c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM
n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE
cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
(
SELECT DISTINCT
c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM
n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE
cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
(
SELECT DISTINCT
c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM
n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE
cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
INTO
#MissingIndexInfo
FROM
(
SELECT
query_plan
FROM
(
SELECT DISTINCT
plan_handle
FROM
sys.dm_exec_query_stats WITH ( NOLOCK )
) AS qs
OUTER APPLY sys.dm_exec_query_plan(qs.plan_handle) tp
WHERE
tp.query_plan.exist('//MissingIndex') = 1
) AS tab(query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE
n.exist('QueryPlan/MissingIndexes') = 1;
-- Trim trailing comma from lists
UPDATE
#MissingIndexInfo
SET
equality_columns = LEFT(equality_columns, LEN(equality_columns) - 1),
inequality_columns = LEFT(inequality_columns, LEN(inequality_columns) - 1),
include_columns = LEFT(include_columns, LEN(include_columns) - 1);
SELECT
*
FROM
#MissingIndexInfo
ORDER BY
[impact] DESC;Resultado:
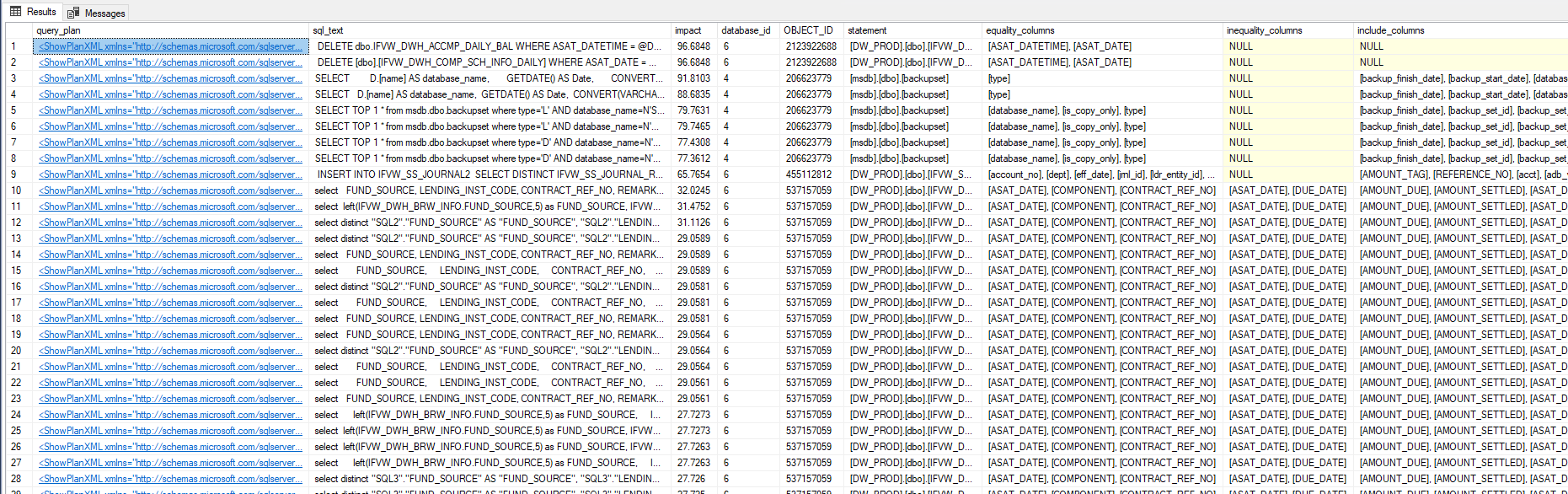
Ahora simplemente haga clic en XML (primera columna: query_plan) para ver el plan de ejecución (y ver la advertencia de índice faltante).

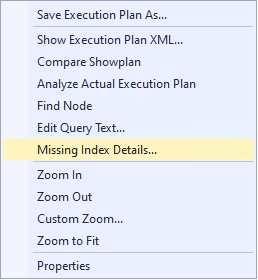
Haga clic derecho y seleccione la opción "Detalles faltantes del índice...".
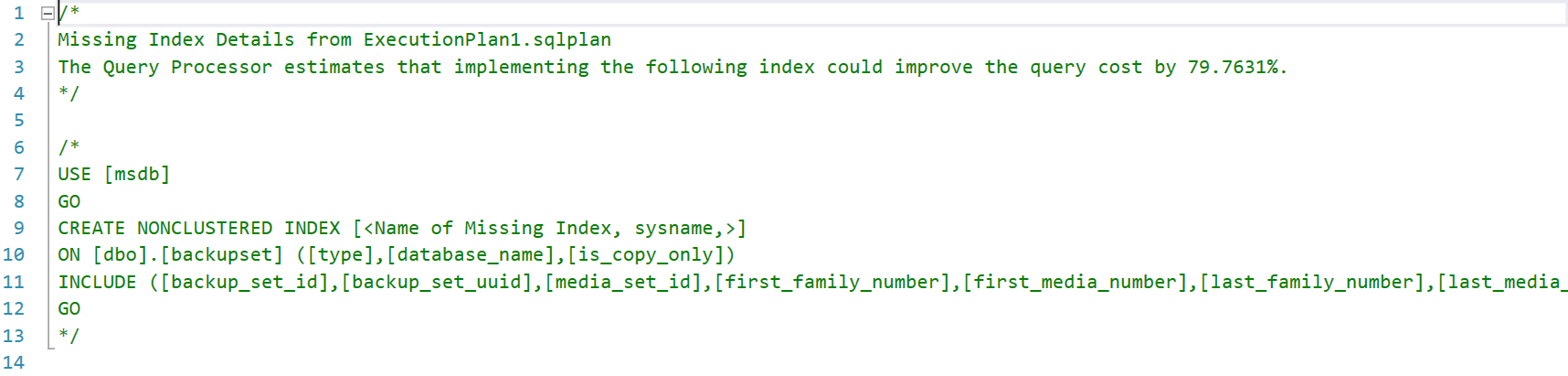
Y verifique el script generado automáticamente para crear el índice:
Para comprender mejor el ajuste del rendimiento y comprender qué es la operación de búsqueda, escaneo, etc., lea el artículo SQL Server – Introducción al estudio de Performance Tuning.
Conclusión
Cerrando este artículo, espero que te haya gustado este consejo. Sin duda te será de gran utilidad en tu día a día como DBA, especialmente para principiantes.
Recuerde mis consejos y no cree todos los índices sugeridos y analícelos siempre antes de crearlos para ver si este índice podría optimizarse mejor o fusionarse con uno existente.
Analiza también si este índice realmente aportará valor al negocio o simplemente ocupará espacio en disco y mejorará una consulta que no marcará la diferencia, como por ejemplo una consulta ejecutada una vez al día, en las primeras horas de la mañana.
¡Y eso es todo, amigos!
¡Un fuerte abrazo y nos vemos en el próximo post!

Comentários (0)
Carregando comentários…